
개요

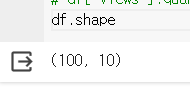
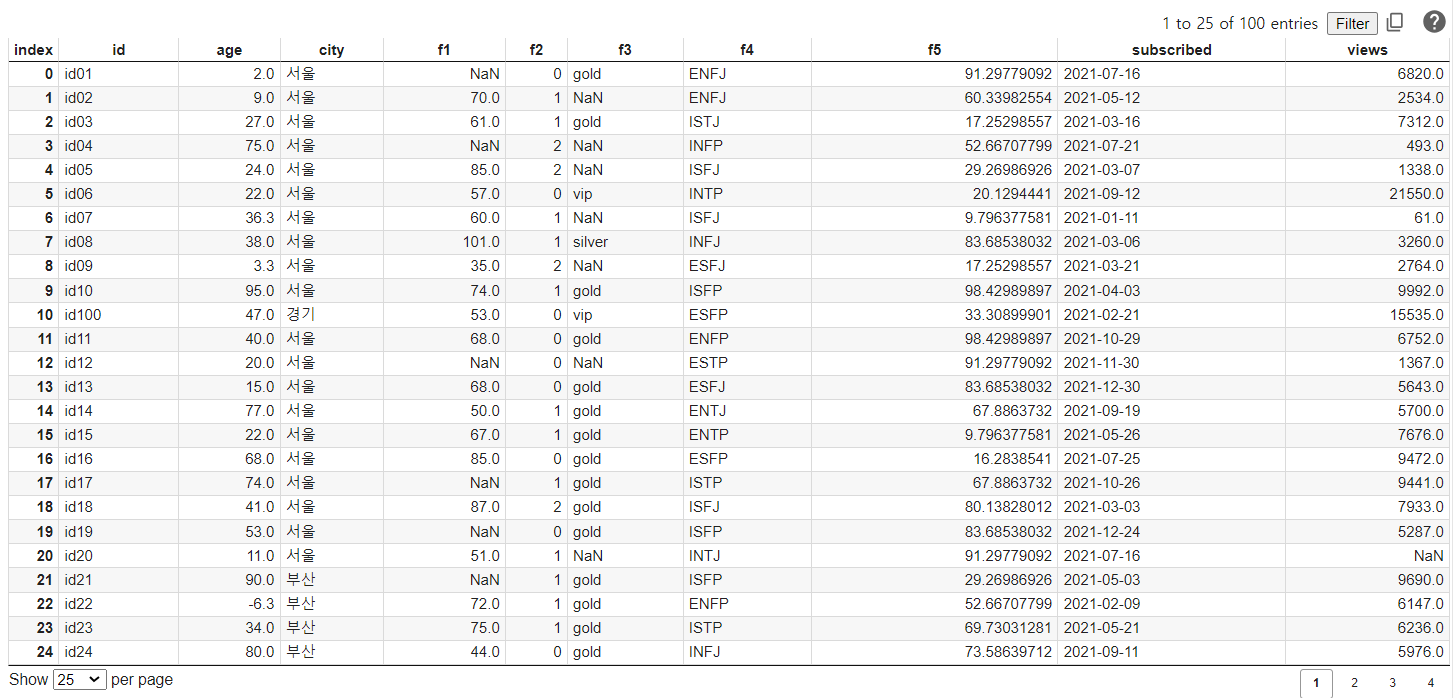
- 데이터는 100개 행과 10개 컬럼으로 이루어져 있다.
📌 문제1

- 나의 풀이
import pandas as pd df = pd.read_csv('members.csv') df['f1'] = df['f1'].fillna(df['f1'].median()) df = df.dropna() df = df.head(int(len(df)*0.7)) result = df['views'].quantile(0.75) - df['views'].quantile(0.25) print(result)

- 결측치 (중앙값,제거)
f1 컬럼의 결측치를 중앙값으로 대체
# 결측치를 대체할 때는 .fillna 함수를 사용, 괄호 안에 대체할 값을 넣는다. df['f1'] = df['f1'].fillna(df['f1'].median())
나머지 결측치가 있는 데이터(행) 모두 제거
결측치를 제거하는 함수는 .dropna() df = df.dropna()
- 데이터추출
앞에서부터 70% 데이터 추출하기
# .head 함수는 앞에서부터 데이터 불러오기 # len(df) 로 전체 데이터 갯수를 불러오고, * 0.7 을 해주면서 70%에 해당하는 데이터 갯수를 불러오고, int 함수로 정수로 바꿔준다. 해당하는 갯수만큼 앞에서부터 불러온다. df = df.head(int(len(df)*0.7))
- 사분위수: quantile
views 컬럼의 사분위수 (1분위, 3분위) 구하기
# 3분위수 df['views'].quantile(0.75) # 1분위수 df['views'].quantile(0.25)
- 출력하기
원하는 결과를 변수에 담아 print 해준다.
result = df['views'].quantile(0.75) - df['views'].quantile(0.25) print(result)
- 정답 풀이
- 중간중간 print를 통해 결측치 제거나 원하는 값이 나오고 있는지 확인하는 습관 들이기!
# 풀이 import pandas as pd df = pd.read_csv("members.csv") df['f1'] = df['f1'].fillna(df['f1'].median()) # print(df.isnull().sum()) # print(df.shape) df = df.dropna() # print(df.shape) df = df[:int(len(df) * 0.7)] r1 = df['views'].quantile(.75) r2 = df['views'].quantile(.25) print(r1 - r2)

- CHECK!
앞에서부터 70% 데이터를 불러올 때, 정답 풀이에서는
df[:int(len(df) * 0.7)]코드로 70% 지점을 구하는 방법은 동일했으나
슬라이싱을 활용해 앞에서부터 70% 지점까지를 출력했다.
📌 문제2

- 나의 풀이
import pandas as pd df = pd.read_csv('members.csv') # df.isnull().sum() # len(df) * 0.3 # f1 컬럼 결측치 삭제 # f3 컬럼 결측치 최빈값 대체 df = df.dropna(subset = ['f1']) df['f3'] = df['f3'].fillna(df['f3'].mode()[0]) print(len(df[df['f3'] == 'gold']))

- 결측치(조건에 따라 제거) : dropna
- 결측치가 30% 이상 되는 컬럼 찾기
- 전체 데이터 결측치 갯수
# df.isnull().sum()
- 데이터의 30%에 해당하는 값
len(df) * 0.3
- 결측치가 30개 이상인 컬럼 = 결측치가 30% 이상 되는 컬럼 =
f1컬럼
.dropna(subset = ['컬럼명'])메서드 활용해 f1컬럼의 결측치 제거df = df.dropna(subset = ['f1'])


- 결측치(조건에 따라 최빈값으로 대체) : mode
- 결측치가 30% 미만, 20% 이상인 컬럼의 결측치를 최빈값으로 대체
- 전체 데이터 결측치 갯수
# df.isnull().sum()
- 결측치가 20% ~ 30% 인 컬럼 = 'f3컬럼'
.fillna(대체값)메서드 활용해 f3컬럼의 결측치 최빈값으로 대체df['f3'] = df['f3'].fillna(df['f3'].mode()[0])
- 조건에 맞는 데이터 수: len
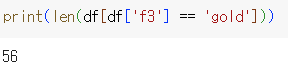
'f3' 컬럼의 'gold' 값을 가진 데이터 수 출력
print(len(df[df['f3'] == 'gold']))
- 정답 풀이
# 풀이 import pandas as pd df = pd.read_csv("members.csv") # print(df.isnull().sum()) # print(len(df) * 0.3) # f1 삭제 # f3 최빈값 # print(df.shape) df = df.dropna(subset=['f1']) # print(df.shape) # print(df.head()) df['f3'] = df['f3'].fillna(df['f3'].mode()[0]) # print(df.head()) # df.isnull().sum() print(sum(df['f3'] == 'gold'))

- CHECK !
데이터의 수를 출력할 때, 조건을 걸게 되면 (df['f3'] == 'gold')
해당 시리즈가 True와 False로 반환되어sum()함수를 통해 데이터 수를 확인 가능!
📌 문제3

- 나의 풀이
df = pd.read_csv('members.csv') df = df.dropna(subset = ['views']) import numpy as np df['f3'] = df['f3'].replace(np.nan,0).replace('silver',1).replace('gold',2).replace('vip',3) int(df['f3'].sum())

- 결측치(제거)
- views 컬럼에 결측치가 있는 데이터(행) 삭제
.dropna(subset = ['컬럼명'])메서드를 활용해 원하는 컬럼의 결측치 제거df = df.dropna(subset = ['views'])
- 값 변환: replace
- numpy 라이브러리를 임포트하여 결측치를 지정할 수 있는 환경 만들기
import numpy as np
.replace(원래 값, 바꿀 값)메서드를 활용해 값 변환df['f3'] = df['f3'].replace(np.nan,0).replace('silver',1).replace('gold',2).replace('vip',3)
- 합계
.sum()메서드 활용해 컬럼의 합계 구하고int()함수로 정수화하기int(df['f3'].sum())
- 정답 풀이
방법 #1 (replace)
#replace import pandas as pd df = pd.read_csv("members.csv") # print(df.shape) df = df.dropna(subset=['views']) # print(df.shape) # print(df.head(7)) import numpy as np df['f3'] = df['f3'].replace(np.nan,0) df['f3'] = df['f3'].replace('silver',1) df['f3'] = df['f3'].replace('gold',2) df['f3'] = df['f3'].replace('vip',3) # print(df.head(7)) print(df['f3'].sum())

방법 #2 (map)
#map import pandas as pd df = pd.read_csv("members.csv") df = df.dropna(subset=['views']) dict_list = {np.nan:0, 'silver':1, 'gold':2, 'vip':3} df['f3'] = df['f3'].map(dict_list) print(df['f3'].sum())

방법 #3 (조건)
# 조건 import pandas as pd df = pd.read_csv("members.csv") df = df.dropna(subset=['views']) r1 = sum(df['f3'] == 'silver') * 1 r2 = sum(df['f3'] == 'gold') * 2 r3 = sum(df['f3'] == 'vip') * 3 print(r1 + r2 + r3)


커피 좋아하는 데이터 꿈나무