
개요
아스키코드?
유니코드?
바이트(BYTE): 컴퓨터의 기본 저장 단위1바이트(BYTE)=8비트(BIT)- 1바이트(BYTE)에는 2의 8제곱에 해당하는 256개의 고유한 값을 저장 가능
인코딩(ENCODING)또는부호화:
문자나 기호들의 집합을 컴퓨터에 저장하거나, 통신 목적으로 사용할 경우에 부호로 바꿔주는 것
예시) 모스 부호디코딩(DECODING)또는복호화:
부호화된 문자를 복원하는 것
📌 아스키 코드 (ASCII)
ASCII: American Standard Code for Information Interchange
- 1960년대 미국에서 정의한 표준화한 부호 체계
1바이트.
즉, 8비트 중 1비트를 통신 에러 검출을 위해 사용하기 때문에
(통신 에러 검출을 위한 비트 = Parity Bit)
7비트 = 128개의 고유한 값만 사용
'영문' 키보드로 입력할 수 있는 모든 가능성을 담고 있으며,
0부터 127까지 128개의 고유값을 저장하고 있다.
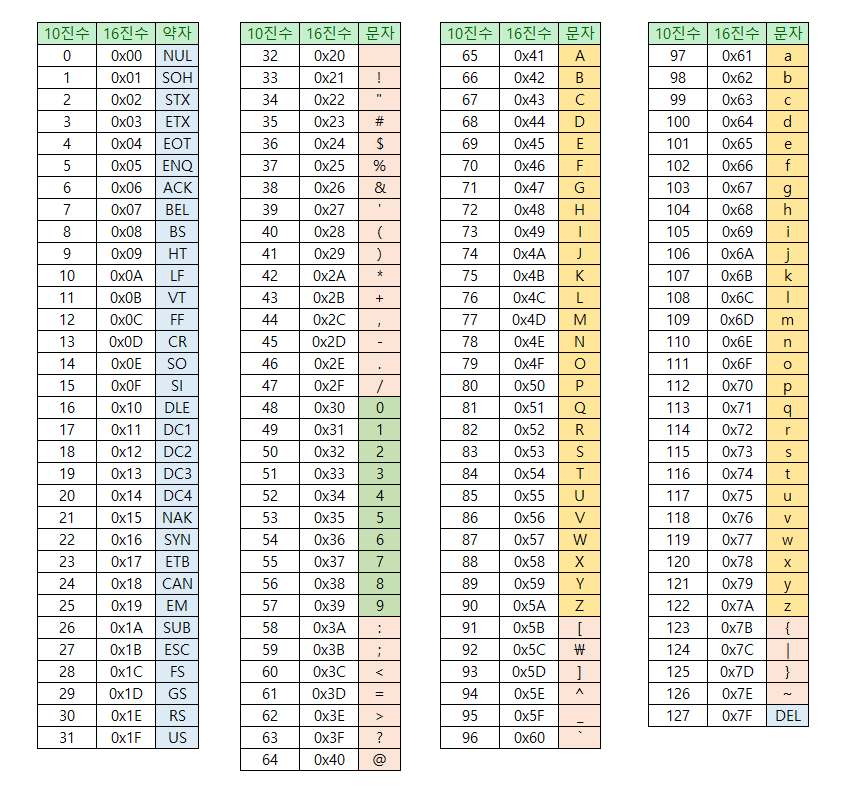
- ASCII control characters, 제어 문자 (0~31 + 127)
- 첫 32개 문자는 제어문자로 화면에 출력하거나 인쇄할 수 없고,
프린터와 같은 주변 장치를 제어하거나 전송 제어용으로 사용
- 첫 32개 문자는 제어문자로 화면에 출력하거나 인쇄할 수 없고,
- ASCII printable characters, 출력 가능한 문자 (32~126)
- 32번부터는 구두점, 숫자, 영어 대소문자 등 문자나 문장부호로 출력 가능
ASCII 는 아스키 코드로 표현할 수 있는 문자들 외 추가적인 문자를 지원할 필요성을 느껴
기존 7비트에 1비트를 추가해 8비트로 확장한ANSI 코드도 만들었고,
1비트의 추가로 128개의 값을 더 저장할 수 있었지만!
각 나라의 다양한 언어를 표현하는 데 한계가 있었다....
📌 유니 코드 (UNICODE)
Unicode: 유니코드 협회(Unicode Consortium)가 제정하는
전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준
초창기 문자 코드는 ASCII의 로마자 위주 코드였고,
1바이트의 남은 공간에 각 나라가 자국 문자를 할당하였다.
하지만 이런 상황에서 다른 국가에 이메일을 보냈더니 글자가 모두 깨졌던 것.
인터넷 웹페이지도 마찬가지였다.
이에 따라 4바이트(32비트, 약 42억 자)의 넉넉한 공간에
세상의 모든 문자를 할당한 결과물이 유니 코드이다.
현재의 유니코드는 지구상에서 통용되는 대부분의 문자들을 담고 있다.
여기에는 언어를 표기할 때 쓰는 문자는 물론, 기호, 이모지, 태그 같은 것들도 포함된다. 처음에는 2BYTE (2의 16제곱 = 65536) 의 유니코드가 등장했다.
유니코드 3.0 버전까지는 2바이트의 영역을
기본다중언어판(BMP, Basic Multilingual Plane)이라 불렀고,
여기에는 기본 문자가 들어가 있다.
65536개의 값에 온 세상 문자를 모두 담을 수 있을 거라고 생각했지만,
쓰지않는 고어, 아프리카 토속어 등 모든 문자를 담으려 하다보니 이마저도 부족..
이를 해결하기 위해 유니코드 3.0부터 보충언어판(SP, Supplementary Plane)을 정의했다.
BMP의 일부를 상위대행(High Surrogates, 1024자), 하위대행(Low Surrogates, 1024자)으로
할당한 뒤 이 둘의 조합으로 1024 * 1024 = 1,048,576 약 100만자가 넘는 문자를 추가로 정의.

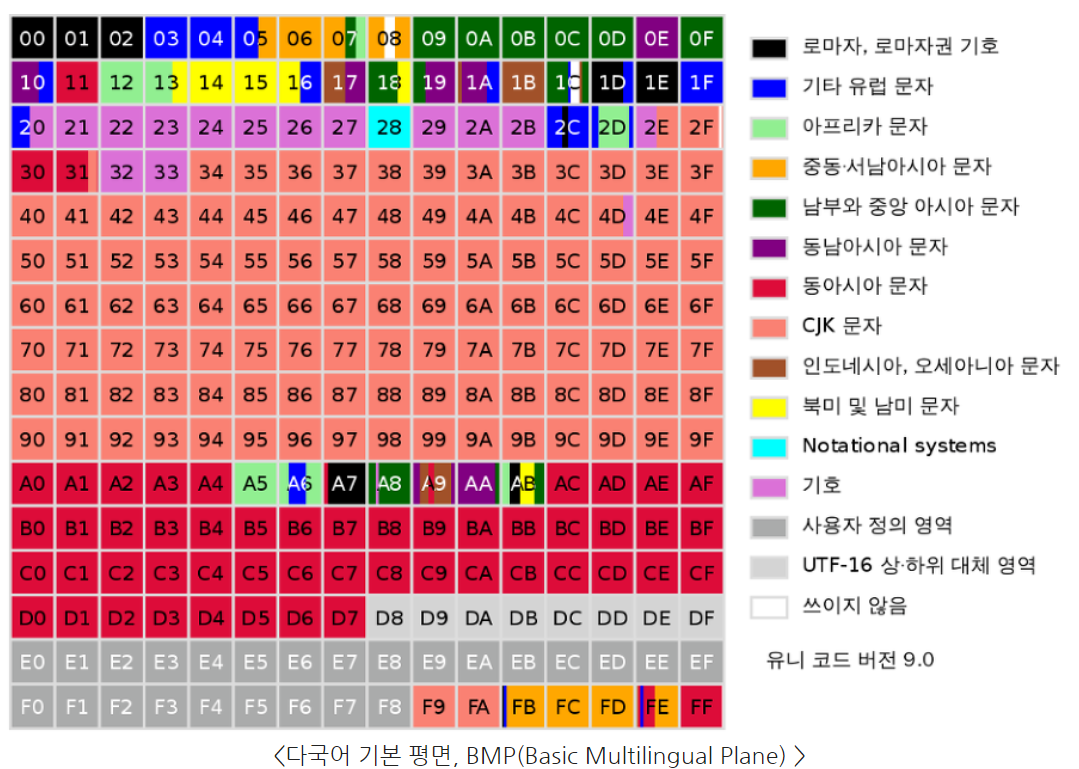
유니코드에는 총 110만 개가 넘는 코드를 지정할 수 있게 되었다.
유니코드는 이를 17개 구역으로 나누었는데,
110만 개의 코드를 2바이트에 해당하는 65536으로 나눈 것. (약 16.78개)
이 구역 하나하나를 '평면(Plane)'이라 부르며, 0번부터 16번 평면까지 있다.
따라서 유니코드는 1개의 기본언어판(BMP)와 16개의 보충언어판(SMP)를 가지고 있다.
문자 인코딩 형태(Character Encoding Form, CEF):
특정한 문자 집합 안의 문자들을 컴퓨터 시스템에서 사용할 목적으로
일정한 범위 안의 정수(코드값)들로 변환하는 방법
- 여기에는 유니코드 코드 포인트를 8비트 숫자의 집합으로 나타내는
UTF-8이나,
16비트 숫자의 집합으로 나타내는UTF-16등이 포함.
📌 UTF - 8
UTF - 8: 유니코드 한 문자를 나타내기 위해 1byte(8bit)에서 4byte(32bit)까지 사용
UTF-8은 1 byte에서 4 bytes까지의 가변 길이를 가지는 인코딩 방식,
네트워크를 통해 전송되는 텍스트는 주로 UTF-8로 인코딩되는데,
사용된 문자에 따라 더 작은 크기의 문자열을 표현할 수 있기 때문
UTF-8은 ASCII 코드의 경우 1 byte,
크게 영어 외 글자는 2byte, 3byte, 보조 글자는 4byte를 차지
이모지는 보조 글자에 해당하기 때문에 4byte가 필요 //한글은 3byte
📌 UTF - 16
UTF - 16: 유니코드 코드 대부분(U+0000부터 U+FFFF; BMP)을 16 bits로 표현
대부분에 속하지 않는 기타문자는 32 bit(4 bytes)로 표현,
UTF-16도 가변 길이라고 할 수 있으나, 대부분은 2 바이트로 표현 //한글은 2byte
