개요
<통계학>
데이터 분석 및 과학을 위한 핵심 통계지식 학습
PYTHON 활용 :
통계적 가설검증,회귀(예측),분류(지도학습),클러스터링(비지도학습)에 대한 이해
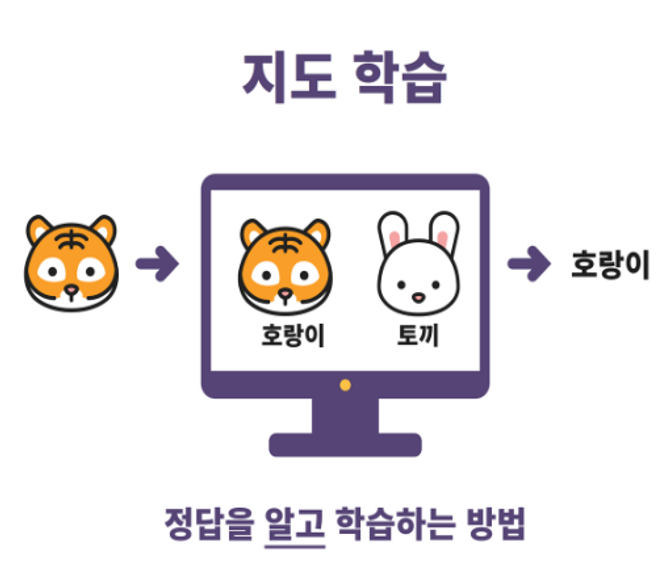
📌 지도학습 & 비지도학습
📌 지도학습
지도학습
정답이 있는 데이터 (labelled data)를 활용해 훈련 데이터로부터 프로그램 등을
학습시켜 결과에 대한 예측을 만들어내는 기계 학습 (ML)의 한 방법
→ 문제와 정답을 모두 알고있는 상태에서 시행
지도학습 > 분류 / 회귀
분류 - 내일은 날씨가 추울 것이다. (춥다 / 춥지 않다 등)
회귀 - 내일은 온도가 35.0℃ 일 것이다. ( ~ ℃ 등 수치 예측)분류 모델은 예측값으로 이산적인 값을 출력하고
회귀 모델은 예측값으로 연속적인 값을 출력한다.
-
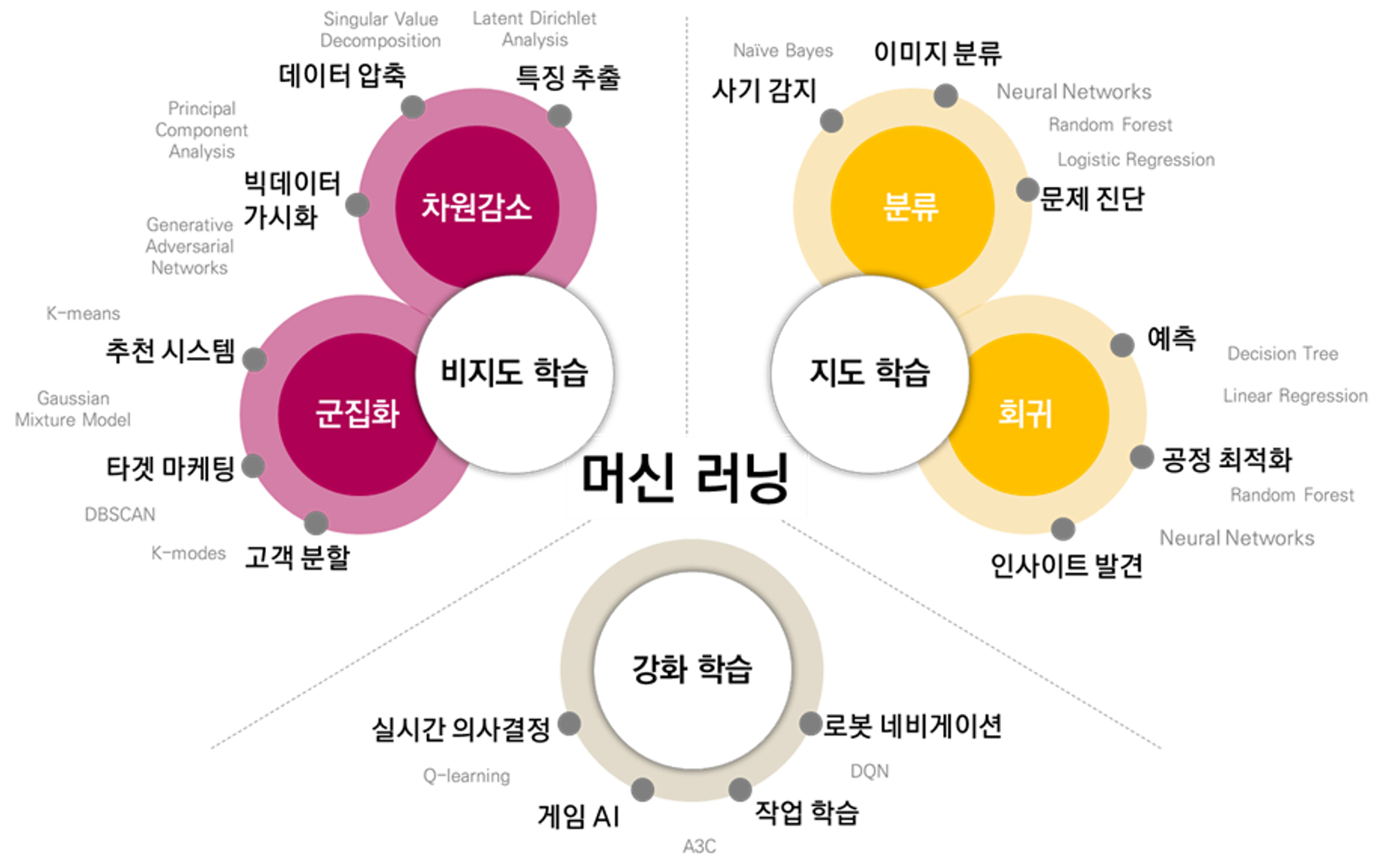
✅ 지도학습에 사용되는 기법
선형 회귀(Linear Regression)로지스틱 회귀(Logistic Regression)- 나이브 베이즈(Naive Bayes)
K-최근접 이웃(k-Nearest Neighbors)- 서포트 벡터 머신(SVM, Support Vector Machine)
- 의사결정 트리(Decision Tree)
랜덤 포레스트(Random Forest)- 인공신경망(Neural Network)
-
✅ RFM (분류) 분석 : 고객 분류 기법
고객을 R, F, M 이라는 특성에 따라 분류하고,
특성에 맞춰 구매기회 창출 및 서비스를 발전시키는 것을 목표로 실시RFM 고객 세분화 분석에서 '반드시 이렇게 해야 한다.' 고 정해진 것이 없다.
비즈니스의 성격과 상황에 따라 알맞은 기준을 세우는 과정이 필요.- Recency, Frequency, Monetary를 각각 몇 단계로 나눌 것인가
- Frequency, Monetary를 집계하는 기간을 어떻게 설정할 것인가
-
R: Recency (최근성)비즈니스의 종류(물건, 정보, 서비스 등)에 따라 다르지만,
RFM 분석에서는 최근에 구매한 고객일수록 더 가치있는 고객으로 점수를 매긴다.
보통 구매시기가 오래된 고객은 재구매율이 떨어지기 때문. -
F: Frequency (빈도)자주 구매하는 고객일수록, 비즈니스에 도움이 되고 재방문율이 높다고 할 수 있다.
빈도수가 높을수록 가치있는 고객으로 점수를 매긴다. -
M: Monetary (구매 금액)빈도가 적더라도, 큰 금액을 지출하는 고객이 회사 입장에서 매출에 더 도움이 될 수 있다.
구매 금액이 높을수록 가치있는 고객으로 점수를 매긴다.

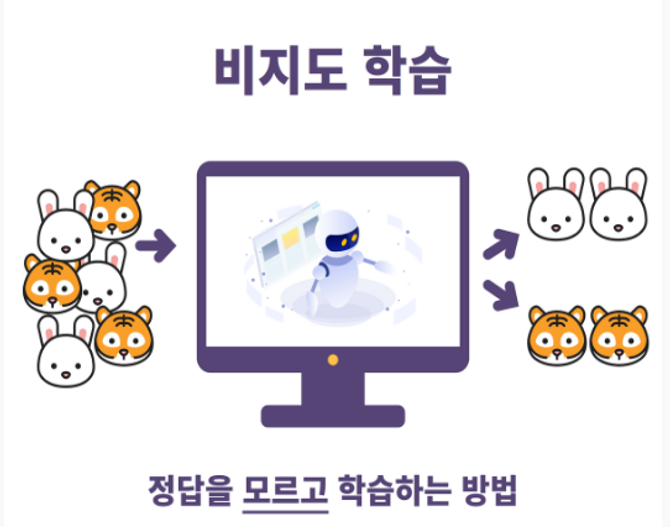
📌 비지도학습
비지도학습
정답이 없는 데이터(Unlabelled data)를 분석하여
그 안에 숨어있는 패턴을 찾아내거나 데이터를 그룹화시키는 알고리즘
→ 정답을 알 수 없는 상태에서 시행
비지도학습 > 군집화
+) 군집화 기간 설정 (최소 6개월 ~ 1년)
- ✅ 비지도학습에 사용되는 기법
군집(Clustering)K-means 클러스터링- 위계적 군집분석
- 가우시안 혼합모형(Gaussian Mix Texture Model)
주성분 분석(PCA)- LLE(Locally Linear Embedding)
- Isomap
- MDS(Multi Dimensional Scaling
- t-SNE(t-distributed Stochastic Neighbor Embedding)
📌 차이점
지도학습과 비지도학습의 가장 큰 차이점은 Label
-
두 접근 방식의 주요 차이점은 데이터 세트에 label 지정 유무
지도학습은 label 이 지정된 입력 및 출력 데이터를 사용하는 반면,
비지도학습은 그렇지 않다.지도 학습 모델은 비지도 학습 모델보다 더 정확한 경향이 있지만
데이터에 적절하게 레이블을 지정하려면 사전에 “데이터분석가의 주관” 개입이 필요- 예) 지도 학습 모델은 시간, 기상 조건 등을 기반으로 통근 시간을 예측할 수 있지만
먼저 비가 오는 날씨가 운전 시간을 연장한다는 것 등을 알기 위한 훈련이 필요하다.
비지도학습은 label 이 지정되지 않은 데이터의 고유한 구조를 발견하기 위해
자체적으로 작동.
결과의 유효성을 검사하려면 여전히 "데이터분석가의 주관" 개입이 필요- 예) 비지도 학습 모델은 온라인 쇼핑객이 구매했던 제품들을 분석해
다른 온라인 쇼핑객에게 구매할 만한 물건을 추천해 줄 수 있지만,
데이터 분석을 통해서 추천 엔진이 추천해 준 항목들이 타당한지 검증해야 한다.
- 예) 지도 학습 모델은 시간, 기상 조건 등을 기반으로 통근 시간을 예측할 수 있지만
지도학습과 비지도학습 중 뭐가 더 좋다고 할 수 없다.
데이터의 구조나 사용 분야에 맞게 적합한 방식을 선택하는 것이 중요 !
-
목표
- 지도학습 : 새로운 데이터의 결과를 예측
- 비지도학습 : 많은 양의 새로운 데이터에 대한 통찰력
-
활용
- 지도학습 : 감정 분석, 일기 예보 및 가격 예측 등
- 비지도학습 : 이상 감지, 추천 엔진, 고객 페르소나 및 의료 영상 등
-
복잡성
- 지도학습 :
일반적으로 R 또는 Python 과 같은 프로그램을 사용하여 계산되는
비교적 복잡성이 낮은 머신러닝 방법 - 비지도학습 :
대량의 분류되지 않은 데이터로 작업하기 위한 다양한 통계적 지식 및 관련 라이브러리 필요,
의도한 결과를 생성하기 위해 대규모 훈련 세트가 필요하기 때문에 계산적으로 복잡
- 지도학습 :
