
#INTRO
겹벚꽃이 폈다. YR.

본 캠프 3일차, 긍정적으로! 즐겁게 하기!
#코드카타 (09:00 ~ 10:00)
#주간 스크럼 (10:00 ~ 10:30)
- 일일 목표 설정
- (개인) TIL 꼼꼼하게 작성하기
- (팀) 제품별 데이터 분석(기술통계량 분석 시도), 유의미한 인사이트 도출하기
- (팀) 발표자료 초안 완성하기
- 주간 목표 설정
- 코드카타(SQL, 알고리즘) 문제풀이: SQL 50번까지, 알고리즘 30번까지
- 매일 TIL 작성: 나의 하루가 제대로 담기도록 정성껏
- 팀 프로젝트 집중: 팀 모두가 조금씩이라도 성장할 수 있도록 유의미한 결과 만들기
주간, 일일 목표 설정 후 팀원 모두 프로젝트 역할별 개인 연구 시간을 갖기로 했다.
#프로젝트 연구 (10:30 ~ 20:00)
주간 스크럼 후 어제 하루종일 한 것들에서 크게 방향성을 잡기가 어려웠다고 느꼈고,
데이터 자체를 다시 뜯어보기로 결심했다.
데이터가 정규분포를 따르는지, 다른 특이사항은 없는지 확인하기 위해
데이터의 정규성을 확인하고 기술통계량 분석을 시도해볼 것이다.
ADsP 자격증 취득할 때 공부했던 내용들이지만
데이터를 가지고 시도해보는 것은 처음이라 과정을 잘 기록하고 이해하려고 해봐야겠다.
- 데이터의 정규성을 확인하는 방법은 다양한데 주로 사용되는 방법들은 아래와 같다.
1. 기술통계량 분석: 데이터의 왜도(skewness)와 첨도(kurtosis)를 확인
- 왜도가 2보다 작고, 첨도가 -2부터 2 사이에 있으면 데이터가 정규분포에 가깝다고 판단 가능
2. Q-Q 플롯(Quantile-Quantile Plot): 데이터의 분포를 정규분포와 비교하여 그린 그래프
데이터가 정규분포를 따른다면 점들이 대각선을 따라 모여 있어야 한다.
Q-Q 플롯으로 시각화하는 방법은 차차 공부 예정.
3. 정규성 검정: Kolmogorov-Smirnov(KS) 검정, Shapiro-Wilk(SW) 검정 사용
유의확률(p-value)이 0.05보다 크면 정규분포를 만족한다고 판단.
4. 히스토그램 분석: 히스토그램을 그려 데이터의 분포를 시각적으로 확인.- 기술통계량 분석은 데이터의 특성을 요약하고 설명하는데 사용하며,
주로 아래와 같은 기술통계량을 계산하여 데이터를 파악한다.
1. 평균 (Mean): 변수의 평균값은 데이터의 중심 경향을 나타냄.
모든 관측치를 더한 후 관측치의 개수로 나누어 계산.
AVG( ) 함수를 사용하여 열의 평균을 구할 수 있다.
2. 중앙값 (Median): 변수 값들을 크기 순서대로 정렬했을 때 중간에 위치한 값.
이상치에 영향을 덜 받는 통계량.
PERCENTILE_CONT( ) 함수를 사용하여 중앙값을 구할 수 있다.
3. 최빈값 (Mode): 가장 자주 나타나는 값.
범주형 변수에서 주로 사용.
COUNT( ) 함수를 사용하여 각 범주의 빈도를 구할 수 있음.
4. 표준편차 (Standard Deviation): 데이터가 평균에서 얼마나 퍼져 있는지를 나타내는 지표.
편차를 제곱한 후 평균을 구한 뒤 제곱근을 취해 계산.
STDDEV( ) 함수를 사용하여 열의 표준편차를 계산할 수 있음.
5. 범위 (Range): 최대값과 최소값의 차이.
데이터의 변동폭을 파악할 수 있음.
MAX( )와 MIN( ) 함수를 사용하여 열의 최대값과 최소값을 구한 후 차이를 계산.
6. 왜도(Skewness) / 첨도(Kurtosis): 왜도는 데이터의 비대칭성을, 첨도는 데이터의 뾰족한 정도를 나타냄.
SKEW( ) 함수를 사용하여 왜도를 계산 / KURTOSIS( ) 함수를 사용하여 첨도를 계산.
제품별 PROFIT, SALES, QUANTITY 에 대해 기술통계량을 계산하고,
왜도와 첨도를 확인하여 정규성까지 함께 파악해봐야겠다....
-
파이썬 환경 구축 (ANACONDA + JUPYTER NOTEBOOK 설치)
아나콘다 설치 참고 블로그 -
데이터 탐색
기술통계량 분석을 위한 여러 시도를 했으나 결국 하지 못했다.
주피터노트북(파이썬 툴)에 파일 임포트 하는 것부터 버벅이고 있으니..
파이썬 관련한 공부를 집중해봐야겠다.#야간 스크럼 (20:00 ~ 21:00)
- 일일 목표: (2/2) 달성
- 오늘의 성과 ↓
-
PPT 초안 작성을 목표로 팀원들이 모두 적극적으로 참여했다 : )

-
미니프로젝트의 전체적 순서와 내용을 아래와 같이 정했다.
1. 프로젝트 배경, 목표와 방향성
2. 데이터 소개, 데이터 탐색 및 이해, 데이터 전처리
3. 데이터 분석, 분석 결과 요약 및 해석
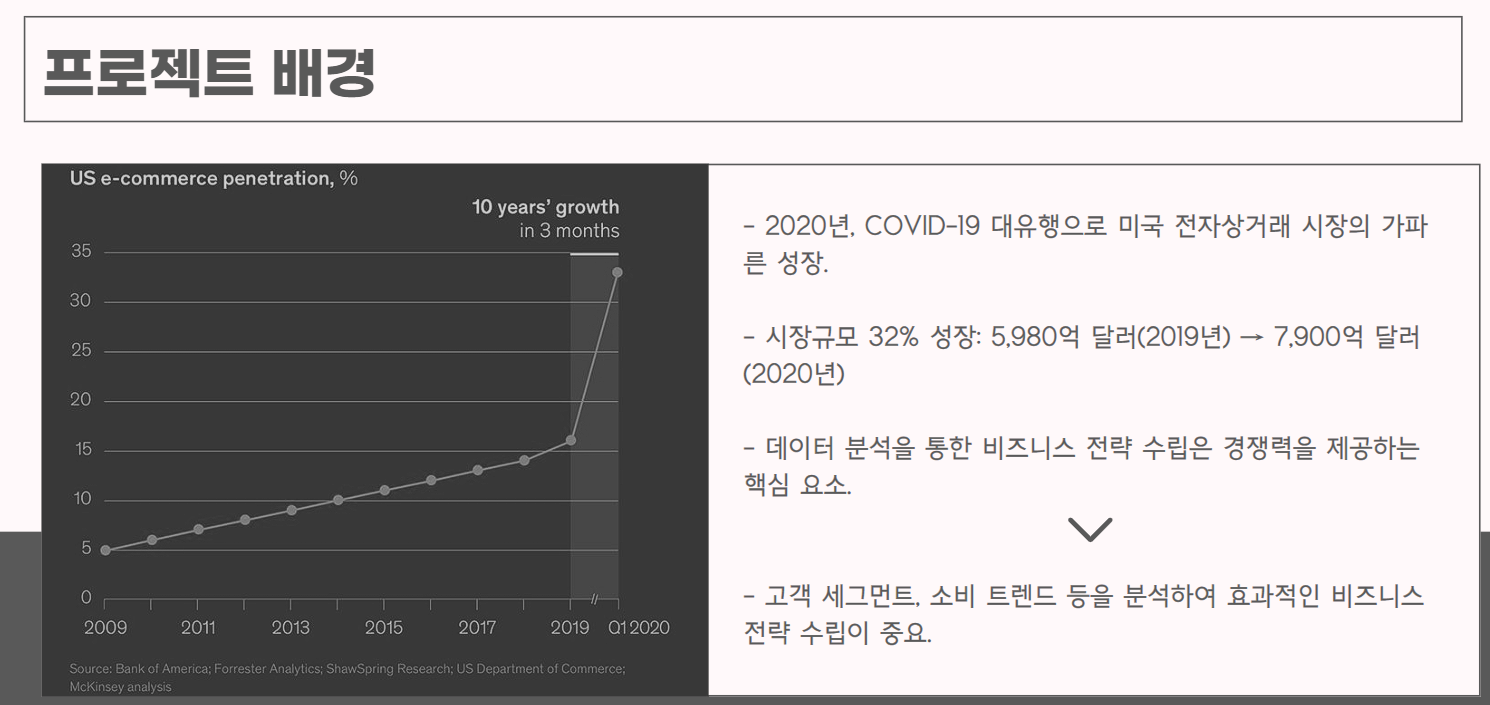
4. 해결 방안 제시, 한계점 및 개선사항▼ 프로젝트 배경
우리가 선택한 주제의 데이터는
[미국의 한 사무용품 판매 회사의 2020년 전자상거래 데이터]이고,
그에 따라 미국 전자상거래 시장의 성장세와 데이터 분석을 통한
비즈니스 전략 수립의 필요성 강조에 중점을 맞췄다.
▼ 프로젝트 목표와 방향성
프로젝트 목표는 앞서 강조한 프로젝트 배경에 이어 수집한 데이터인 미국의 사무용품 회사 A사의 거래 데이터를 분석하여 비즈니스 전략을 제안하는 것으로 정했고,
이에 따라 거래 데이터를 지역, 제품, 시간 데이터를 기준으로 분석해보기로 했다.

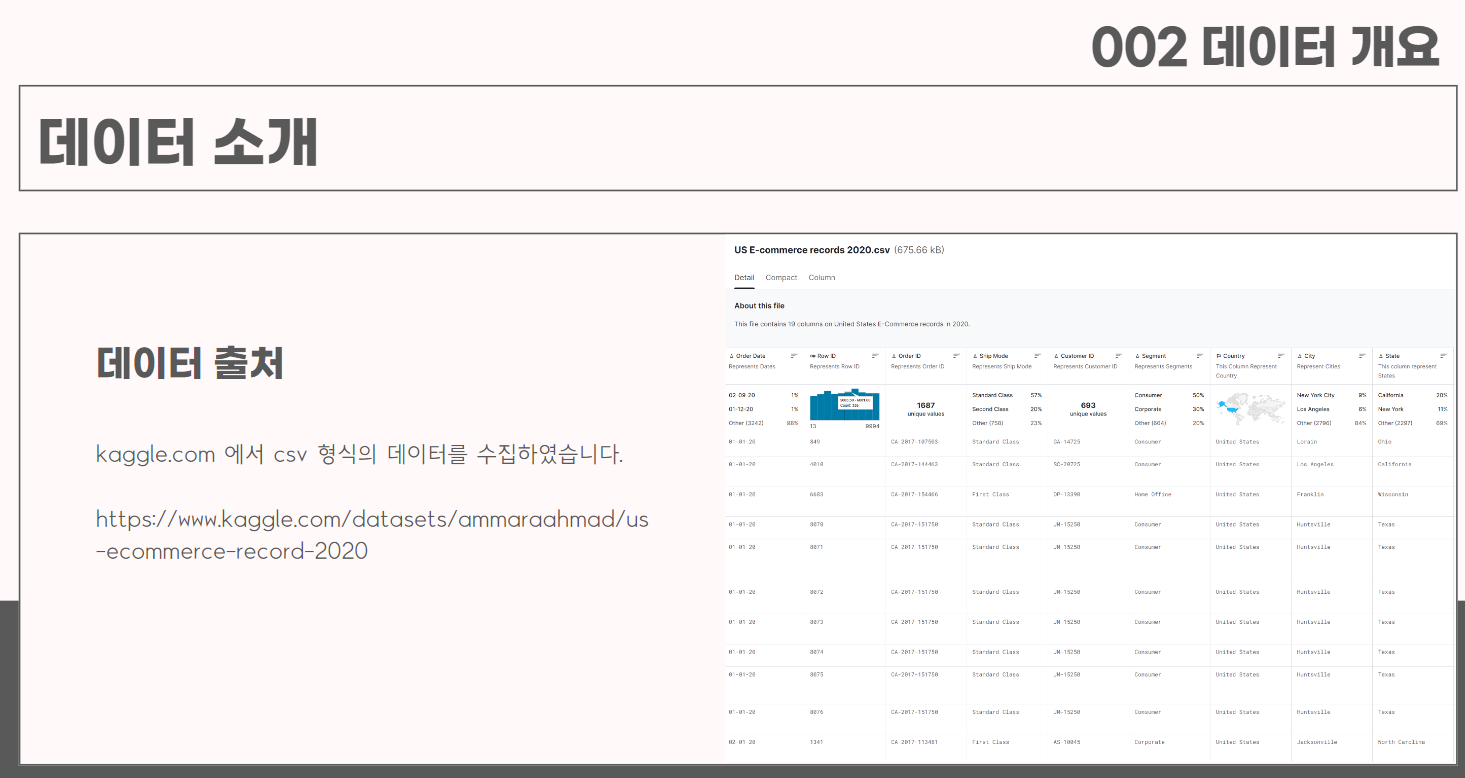
▼ 데이터 소개
KAGGLE에서 CSV 형식의 데이터를 수집했다. (캠프에서 제공)
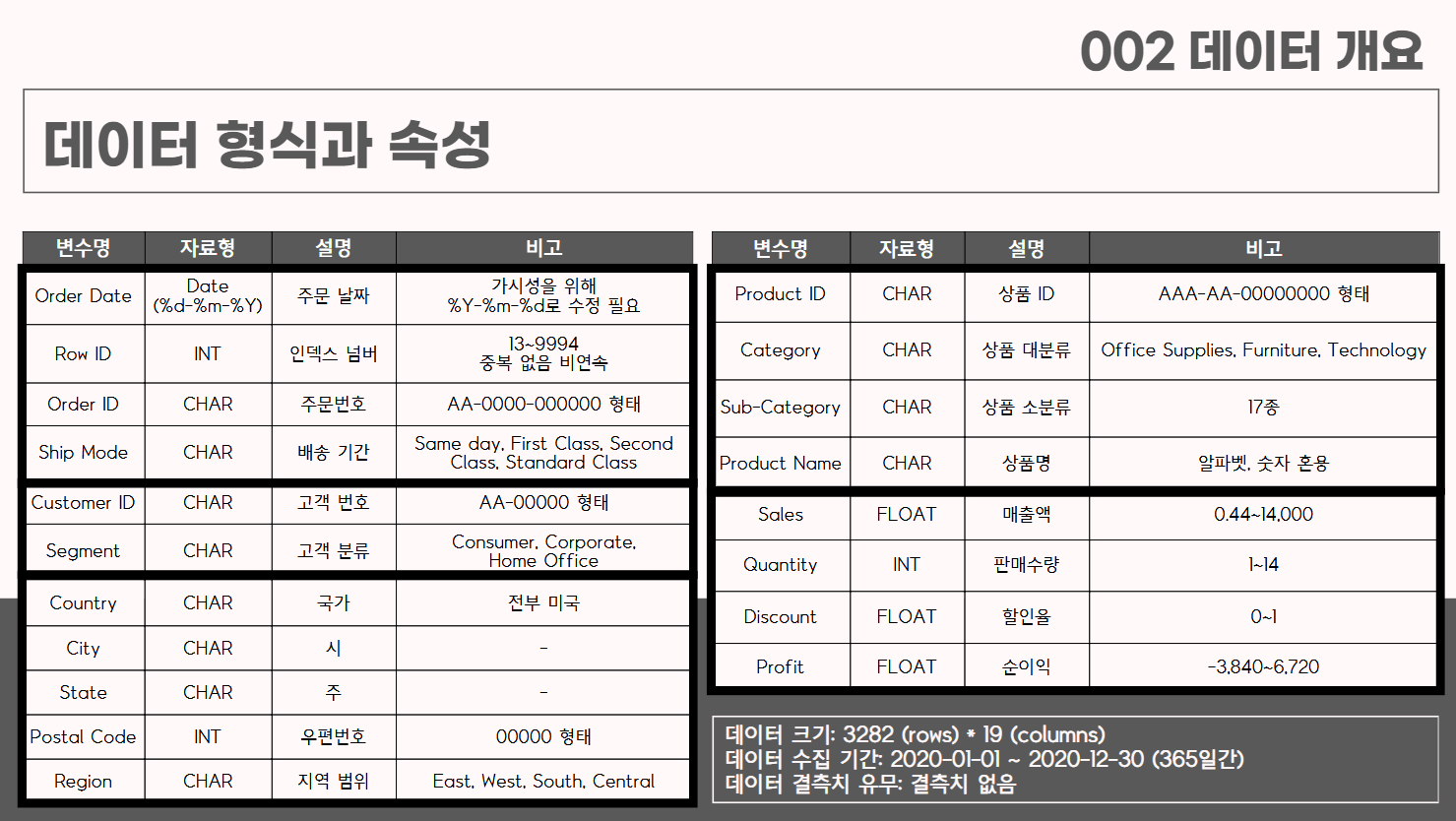
▼ 데이터 형식과 속성
데이터를 각 변수와 형태, 세부 설명 표로 작성하였고,
변수들의 성격에 따라 5개(주문, 고객, 지역, 상품, 매출)의 변수 그룹으로 정리했다.
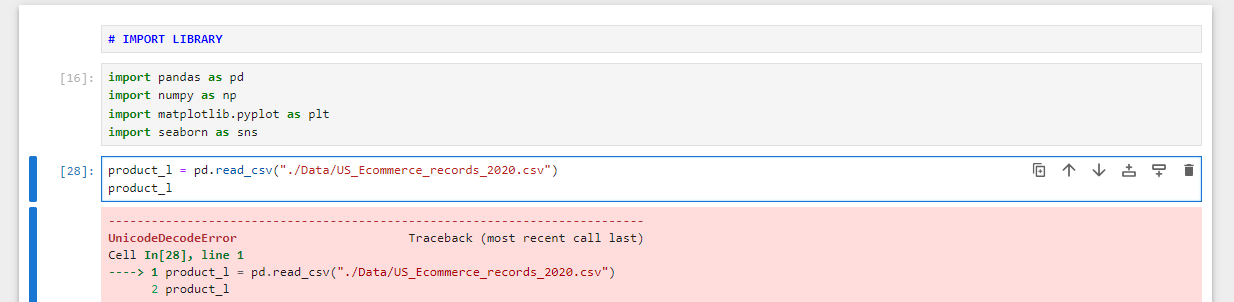
+) 데이터 형식을 파이썬으로 직접 정리하고 싶었는데 알 수 없는 오류로 성공하지 못했다.
# 라이브러리 불러오기 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns # 판다스로 파일 불러오기 product_l = pd.read_csv("./Data/US_Ecommerce_records_2020.csv") # 데이터 정보 불러오기 product_l.info()
▼ 데이터 탐색 1
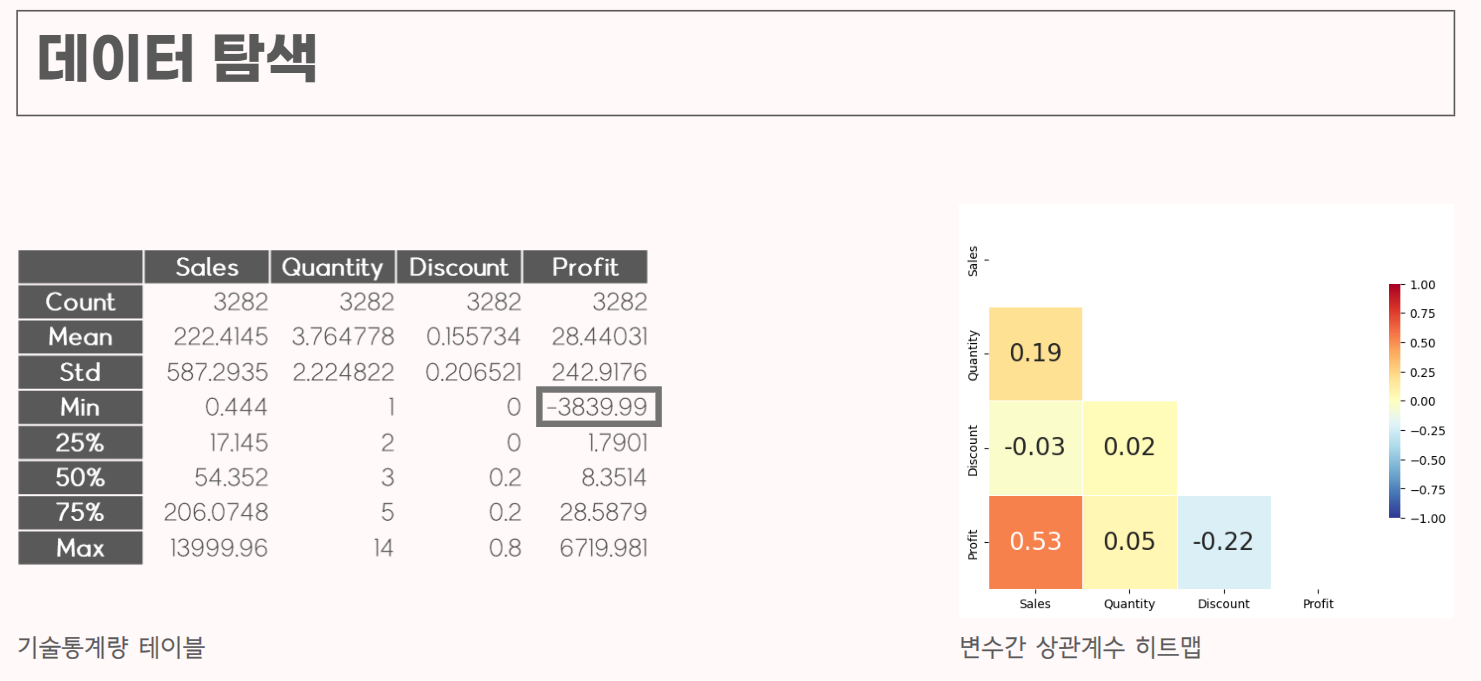
직접 해보고 싶었던 기술통계량 분석. (아쉽게도 큰 그림만 그리고 직접 하지 못했다.)
수치형 데이터인 SALES, QUANTITY, DISCOUNT, PROFIT 4개의 칼럼에 대해 기술통계량을 분석하고 각 변수들의 상관계수를 히트맵으로 표현했다.회사의 입장에서 수익이 마이너스인 제품들에 대한 데이터들에 대한 분석이 유의미하지 않다고 판단하여 PROFIT이 음수인 데이터를 제외하고 분석을 진행하겠다고 결정했고,
SALES 와 PROFIT , DISCOUNT 와 PROFIT 의 관계는 상식적이라
PROFIT 과 QUANTITY 변수에 대해 집중적으로 분석해보기로 결정했다.
▼ 데이터 탐색 2
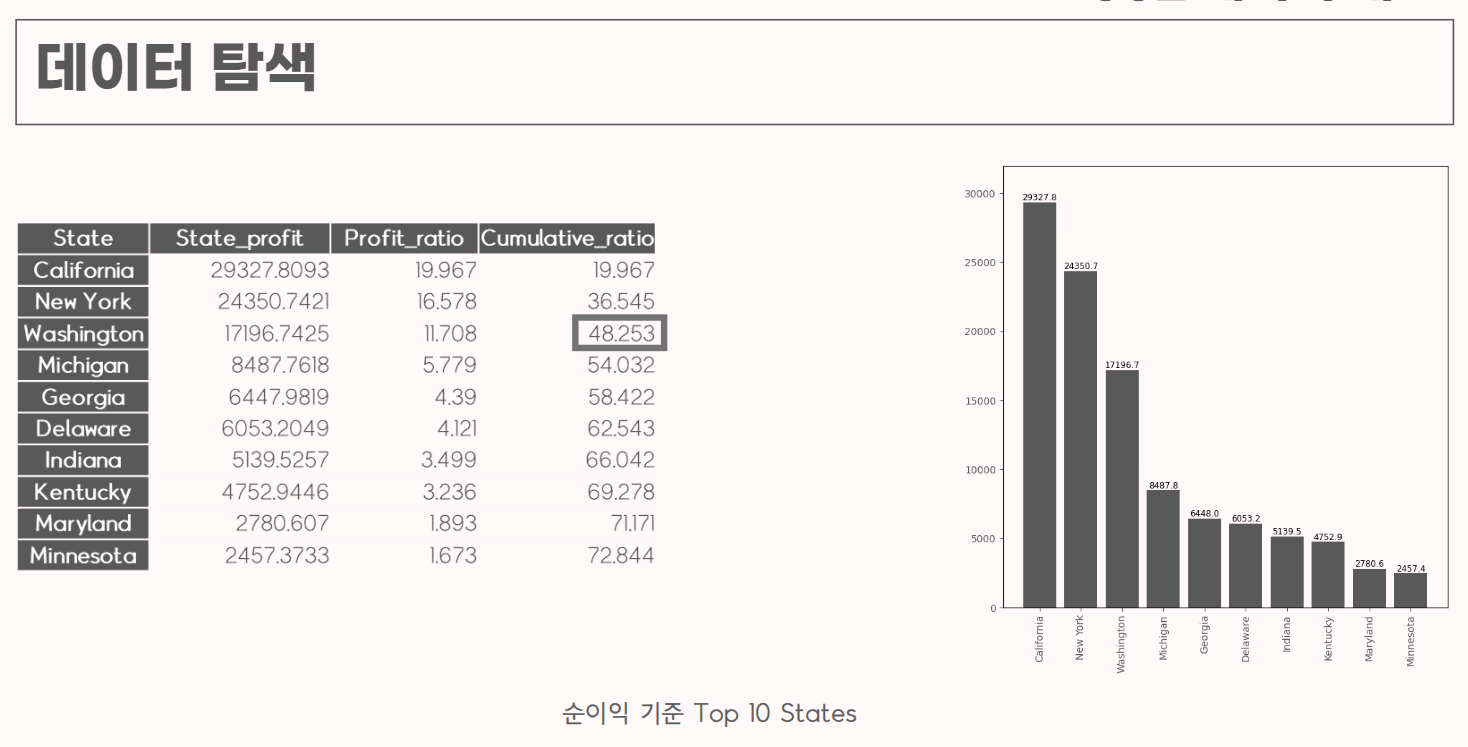
순이익 기준 지역별로 정렬하여 총 수익과 수익 비율, 누적 비율을 분석하고 시각화했다.
총 순이익 상위 3개 지역의 합계가 전체 수익의 48%를 차지한다는 인사이트를 도출했다.
▼ 데이터 탐색 3
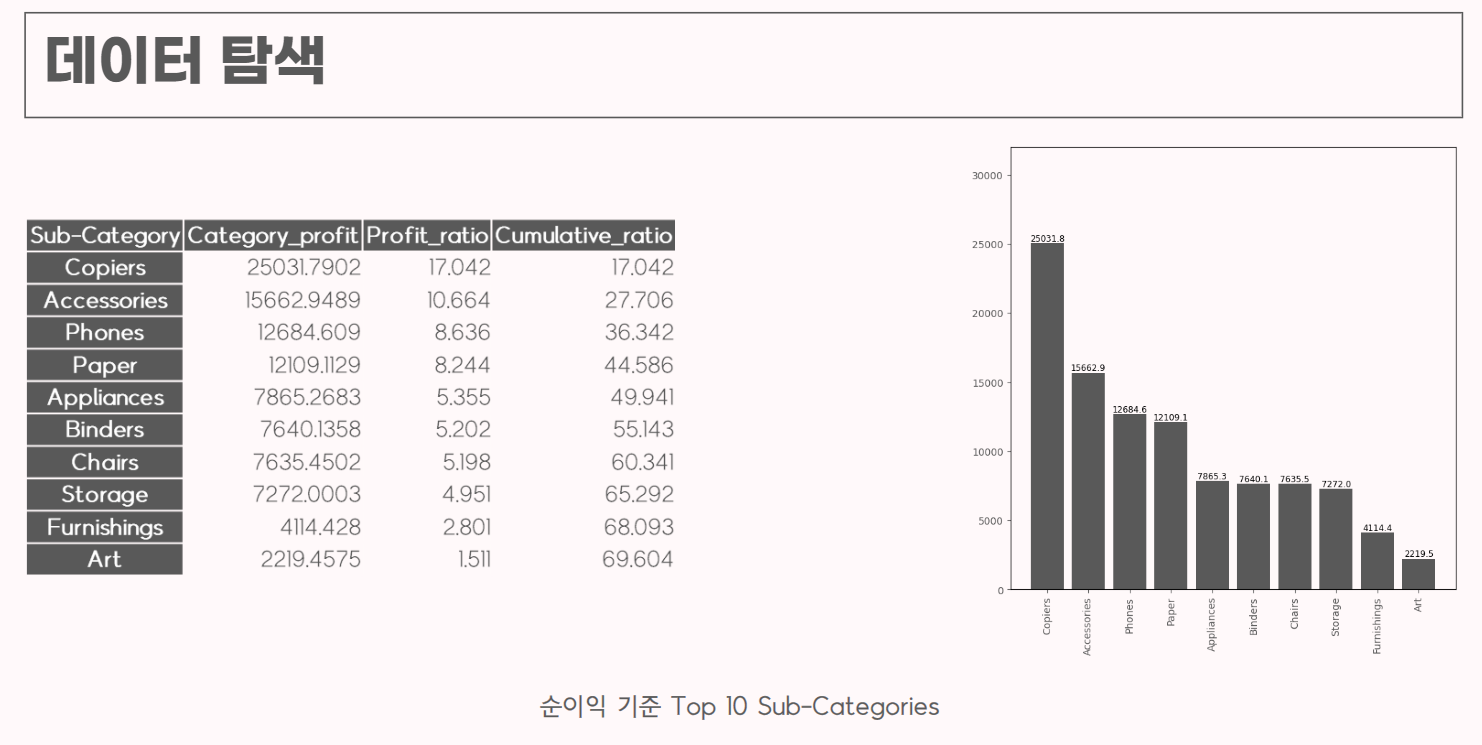
순이익 기준 제품별로 정렬하여 제품들의 분류를 진행했다.
순이익 비중이 높은 제품들을 정리하고 관련해서 추가적인 분석을 할 수 있는 아이디어를 얻었다.
(Copiers 제품군의 순이익이 다른 제품들에 비해 확연히 높다.)
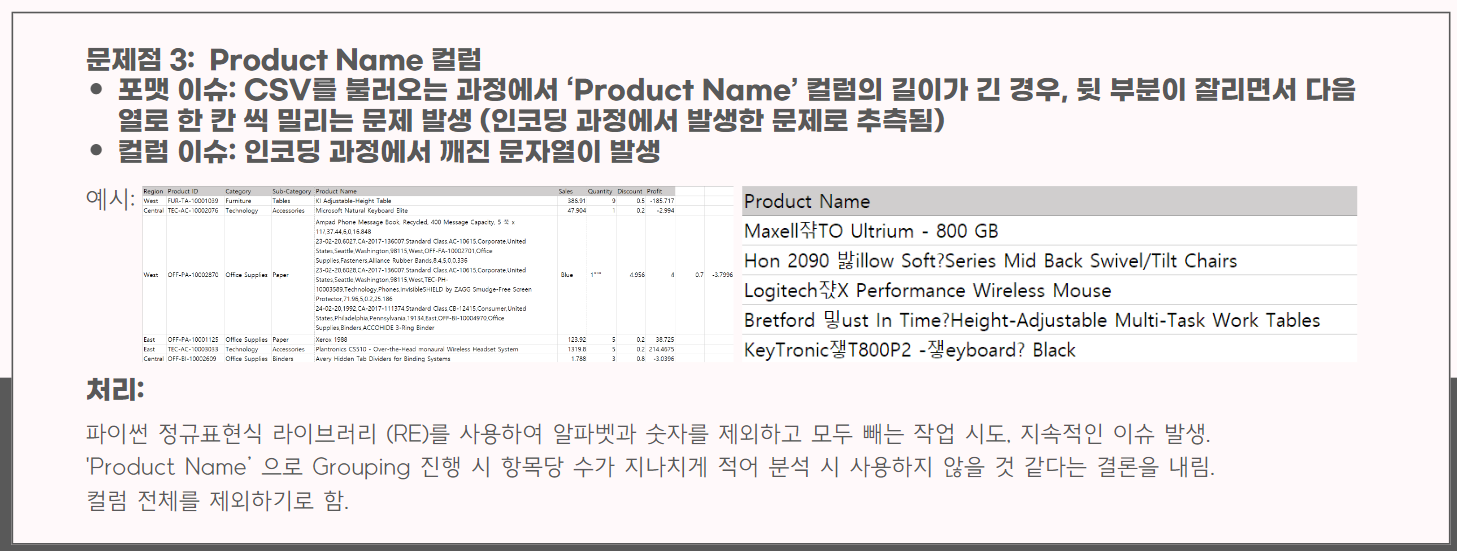
▼ 데이터 전처리

▼ 데이터 분석결과
지역별, 제품별, 시기별 주제를 가지고 분석을 시도해볼 예정이다.
분석 목표를 정하고, 분석 과정과 결과에 대한 해석을 정리해야 한다.
#OUTRO
오늘의 한 줄.
프로젝트 진행에 대한 막막했던 감정들이 어느 정도 해소되는 하루.
