
#INTRO
오늘의 커피 : )

다시 한 주 시작.
화이팅 !
#코드카타 (09:00 ~ 11:00)
-
SQL
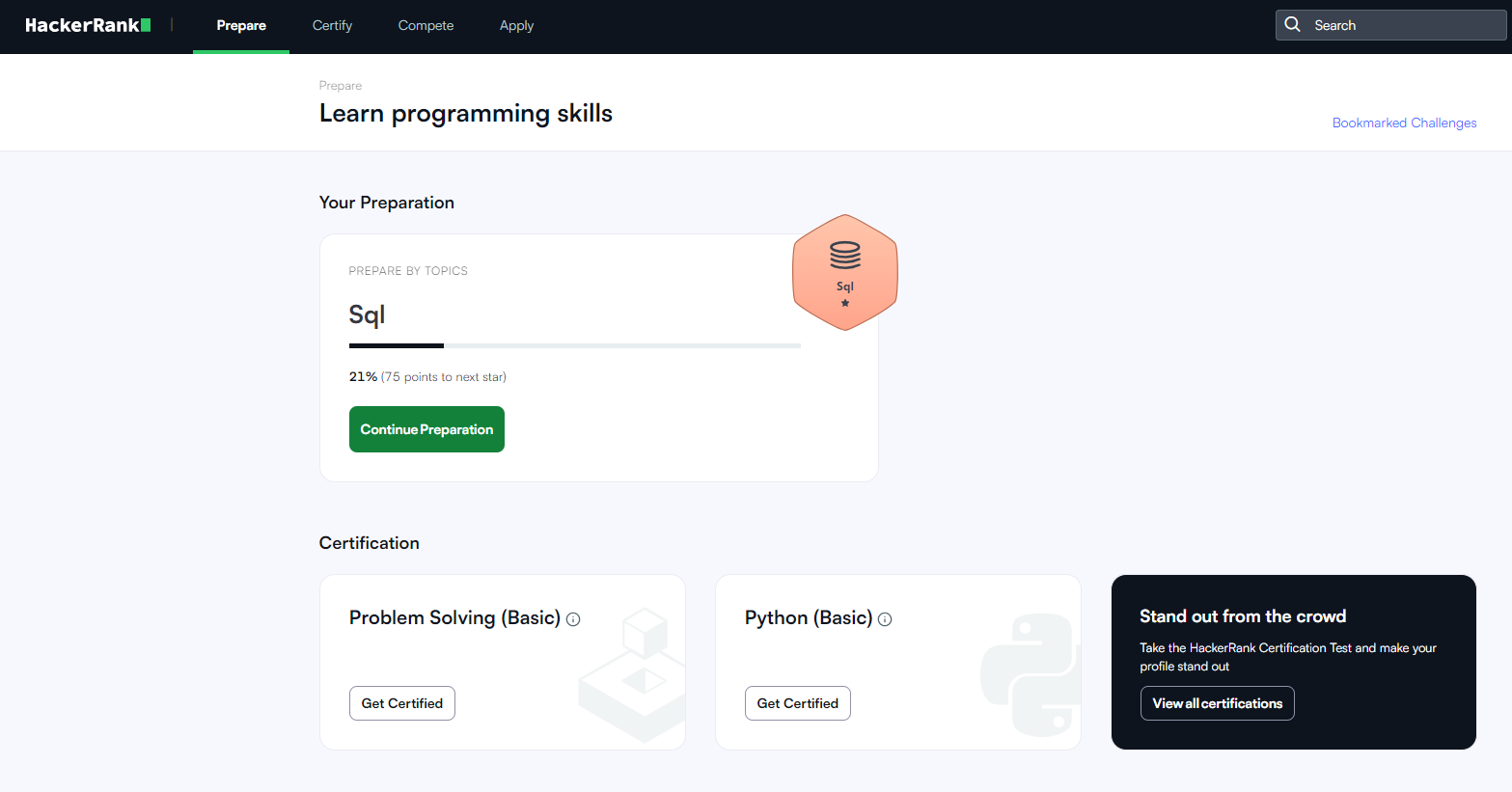
해커랭크라는 새로운 문제 사이트로 시작해서, 난이도가 다시 1이 되었다!
하루에 1~3문제를 꾸준히 풀고 정리하는 것이 목표였는데,
난이도가 너무 낮아졌기 때문에 10문제 풀고 진도 나가기
-
PYTHON
- f 포맷팅 : )
# f 포맷팅으로 최소 최대 문자열 반환 result = f"{mins} {maxs}"
- f 포맷팅 : )
#통계학 세션 (14:00 ~ 15:30)
1회차 요약
- python은 데이터의 종류에 따라 관련된 계산을 어떤식으로 수행할 지 결정
- 데이터 종류 : 대표적으로 수치형, 범주형 데이터
- 데이터 대표값 : 평균, 중간값, 최빈값
데이터 분포를 보다 명확히 파악하기 위해 편차, 분산, 표준편차 학습
- 편차는 그 합이 0 으로 분포를 확인할 수 없다.
→ 음수값을 없애기 위해 제곱을 취해주는 분산 개념 도입
→ 분산은 제곱값이라 단위가 다르기 때문에 제곱근(루트)을 씌워 단위를 맞춤
→ 표준편차
- 무수히 많은 데이터를 대상으로 효과적인 통계분석을 위해 표본추출이 이뤄지고 있다.
- 모집단은 어떤 데이터 집합을 구성하는 전체이고, 표본은 그 중 일부(부분집합)
- 표본의 분포를 가지고 모집단의 분포를 추정하며,
해당 과정에서 무수히 많은 경우의 수의 표본이 생성될 수 있다.
- 표본 크기가 충분히 크다면 어떤 분포에서도 표본평균이 정규분포를 따른다는 것
→ 중심극한정리
- 정규분포는 종 모양을 띄고 있으며, 분포는 좌우 대칭의 형태
평균치에서 그 확률이 가장 높다.
- 정규분포에서 평균 0, 분산 1을 가지는 경우, 이를 표준정규분포라고 한다.
데이터분석시 이를 표준화라고 부름
- 데이터분석시 표준화가 필요한 경우 :
머신러닝 모델을 만들 때, 데이터의 범위가 많이 차이나는 경우.
예시) 최근 일주일 접속일수의 1과 결제금액의 1 은 같은 의미가 아니며,
범위가 큰 데이터의 경우 숫자가 가지는 절대치를 잘못 받아들일 수 있어
표준화는 반드시 필요#빅분기 실기 작업형 2 (회귀) 정리 (17:00 ~ 21:00)
-
회귀 평가지표
# 평가 # r2, mae, mse 는 사이킷런 라이브러리에서 제공 # rmse, rmsle, mape 는 아래 계산식을 활용해 직접 계산해야 한다. import numpy as np from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error def rmse(y_test, y_pred): #RMSE return np.sqrt(mean_squared_error(y_test, y_pred)) def rmsle(y_test, y_pred): #RMSLE return np.sqrt(np.mean(np.power(np.log1p(y_test) - np.log1p(y_pred), 2))) def mape(y_test, y_pred): #MAPE return np.mean(np.abs((y_test - y_pred) / y_test)) * 100

#OUTRO
오늘의 한 줄.
진짜 시간이 많이 부족하네..

커피 좋아하는 데이터 꿈나무