
개요
회귀 평가지표의 이해,
다양한 회귀 모델을 통해 학습 및 예측
📌 문제
에어비엔비 가격예측
- 평가: R-Squared, MAE, MSE, RMSE, RMSLE, MAPE
- target : price(가격)
- csv파일 생성 : 수험번호.csv (예시 아래 참조)
id,price
34323697,238
29927138,183
120362,234📌 데이터 불러오기

import pandas as pd
import numpy as np
train = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/MLpractice/ab_nyc/train.csv")
test = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/MLpractice/ab_nyc/test.csv")
train.shape, test.shape📌 EDA
# 타겟 컬럼 (price) 확인 train.head(3)
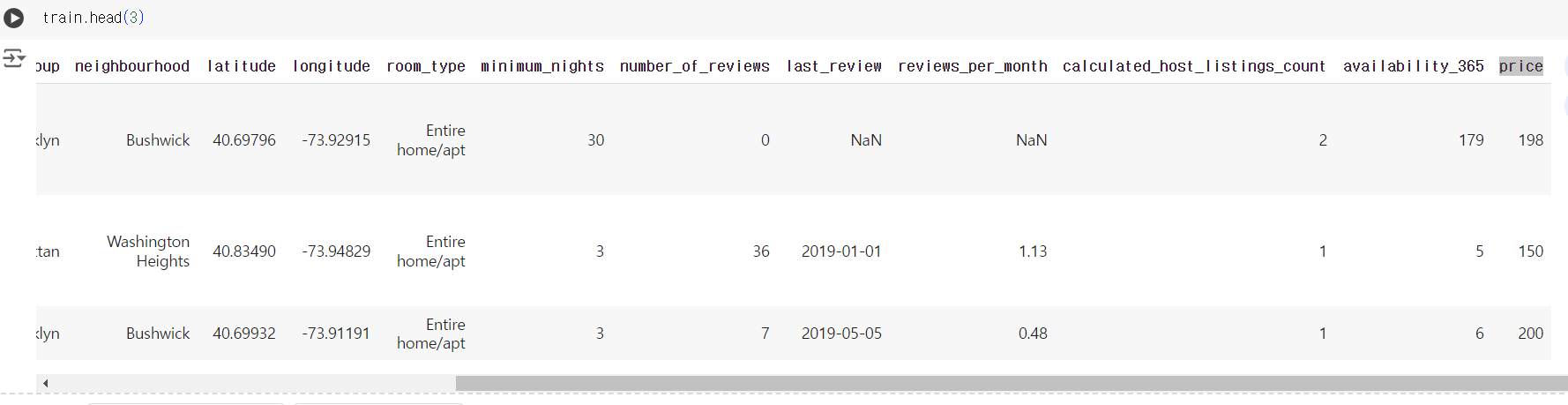
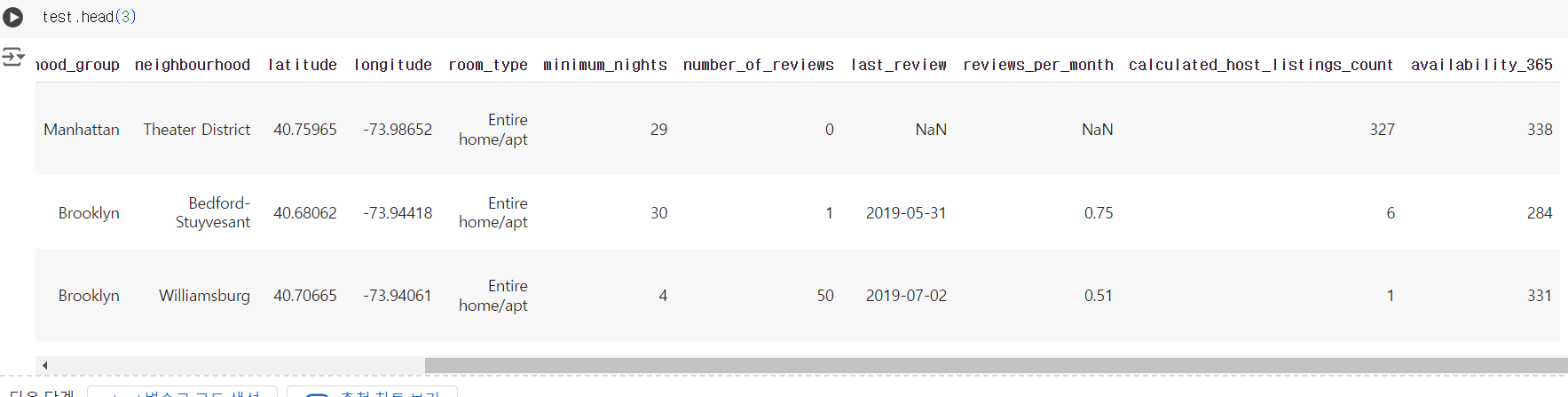
# 테스트 데이터에는 타겟 컬럼이 없다. test.head(3)
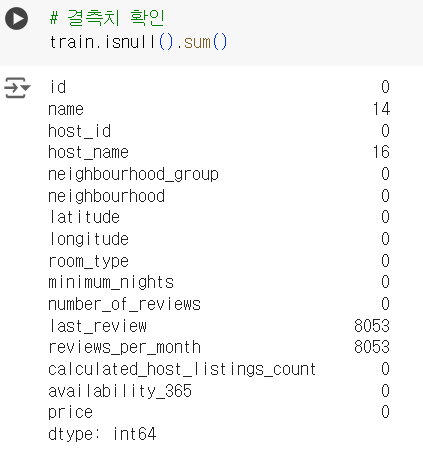
# 결측치 확인 train.isnull().sum()
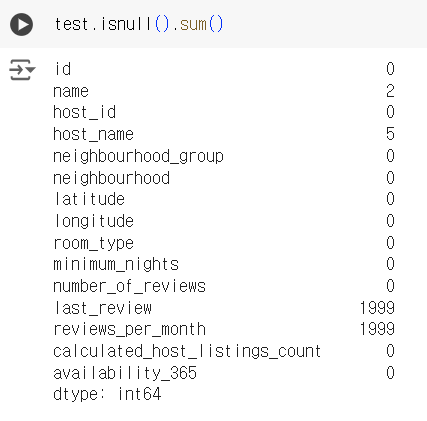
# 결측치 확인 test.isnull().sum()
# 간단한 시각화 train['price'].hist()
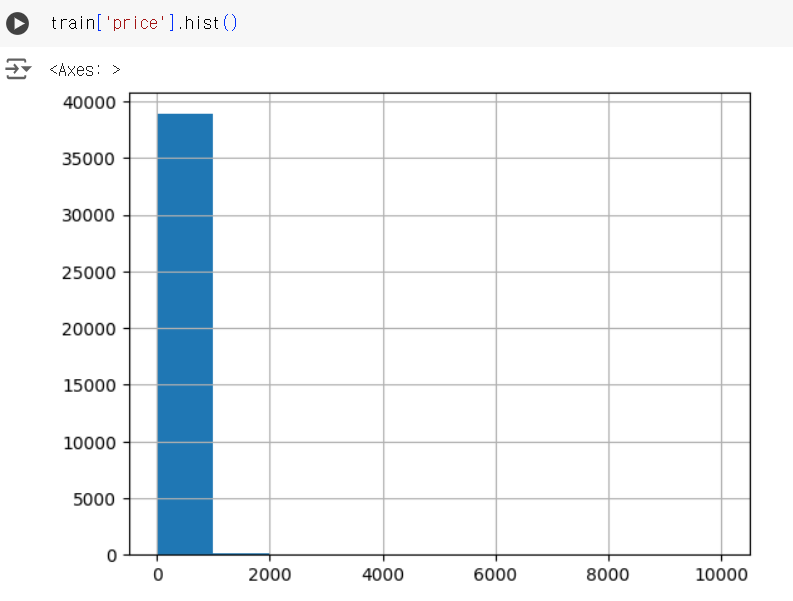
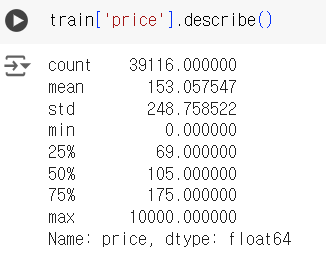
# 시험에서는 시각화를 할 수 없기 때문에 기초통계량으로 값 확인 train['price'].describe()
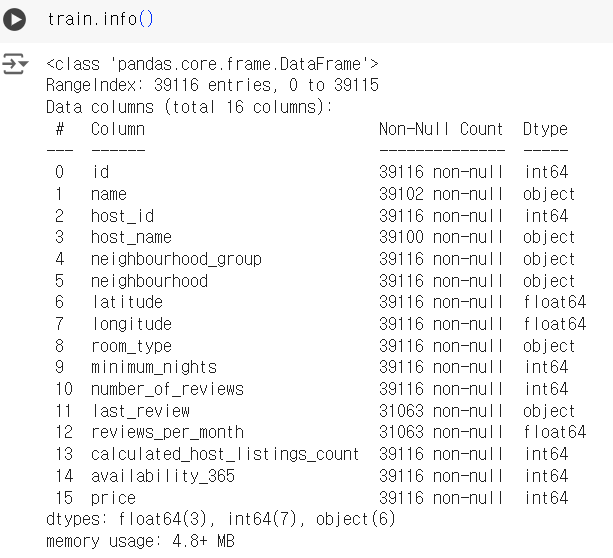
# 데이터 타입 확인 # 회귀 모델을 활용해 예측을 할 것이기 때문에, # 수치형으로 변환하거나 범주형 데이터를 삭제하는 등의 전처리를 진행해야 한다. train.info()
📌 데이터 전처리 및 & 피처엔지니어링
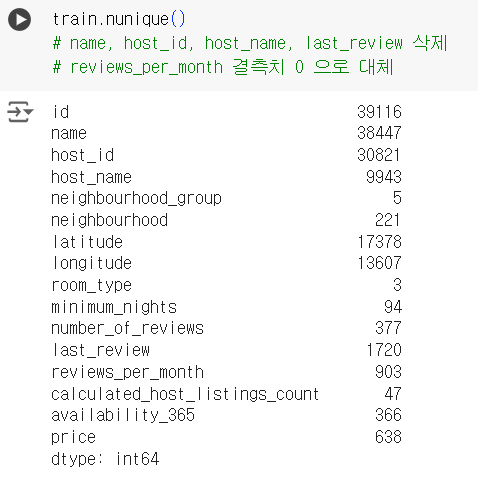
train.nunique() # name, host_id, host_name, last_review 삭제 # reviews_per_month 결측치 0 으로 대체
# 컬럼 삭제 cols = ['name', 'host_id', 'host_name', 'last_review'] print(train.shape) train = train.drop(cols, axis = 1) test = test.drop(cols, axis = 1) print(train.shape)

# 결측치 대체 train['reviews_per_month'] = train['reviews_per_month'].fillna(0) test['reviews_per_month'] = test['reviews_per_month'].fillna(0) train.isnull().sum()
# 훈련용 데이터에서는 타겟이 되는 id 값을 삭제하고, # 테스트 데이터에서는 .pop() 메서드를 활용해서 test_id에 저장해두기 train = train.drop('id', axis = 1) test_id = test.pop('id') test.head()
# 처리가 잘 되었는지 중간중간 확인하기 # 이제 범주형 데이터들을 처리해야 한다. train.info()
# .select_dtypes() 메서드 활용해서 범주형 데이터들 cols에 담기 cols = train.select_dtypes(include = "object").columns # 범주형 데이터 갯수가 200개가 넘어가는 컬럼이 있기 때문에, # 레이블 인코딩 진행 (*컬럼이 여러 개일 경우 반복문으로 한 컬럼씩 진행해줘야 한다.) from sklearn.preprocessing import LabelEncoder for col in cols: le = LabelEncoder() train[col] = le.fit_transform(train[col]) test[col] = le.transform(test[col]) train[cols]
📌 검증 데이터 분리
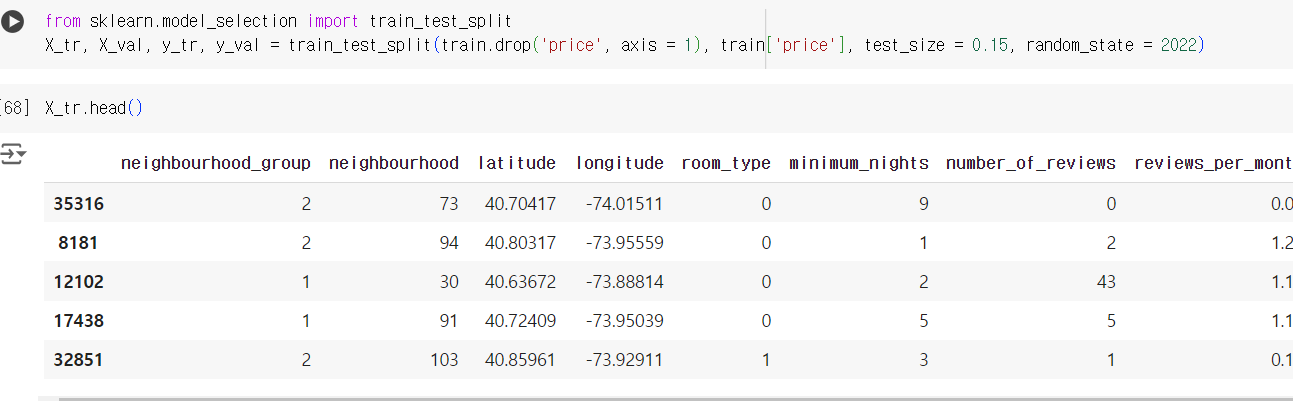
# 훈련, 검증 데이터 분리 # test_size = 0.15 (15 : 85 로 데이터를 나눈다는 의미) # random_state = 2022 (랜덤성을 제어하기 위해 값을 부여) from sklearn.model_selection import train_test_split X_tr, X_val, y_tr, y_val = train_test_split( train.drop('price', axis = 1), train['price'], test_size = 0.15, random_state = 2022 ) X_tr.head()
📌 회귀 평가지표
# 평가 # r2, mae, mse 는 사이킷런 라이브러리에서 제공 # rmse, rmsle, mape 는 아래 계산식을 활용해 직접 계산해야 한다. import numpy as np from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error def rmse(y_test, y_pred): #RMSE return np.sqrt(mean_squared_error(y_test, y_pred)) def rmsle(y_test, y_pred): #RMSLE return np.sqrt(np.mean(np.power(np.log1p(y_test) - np.log1p(y_pred), 2))) def mape(y_test, y_pred): #MAPE return np.mean(np.abs((y_test - y_pred) / y_test)) * 100

📌 모델 및 평가
- 선형회귀, 릿지, 라쏘, 랜덤포레스트, xgboost
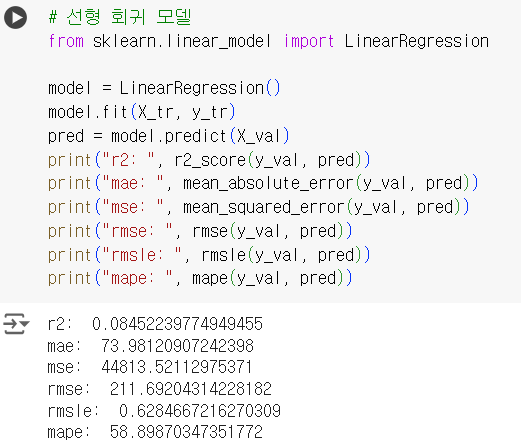
# 선형 회귀 모델 from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_tr, y_tr) pred = model.predict(X_val) print("r2: ", r2_score(y_val, pred)) print("mae: ", mean_absolute_error(y_val, pred)) print("mse: ", mean_squared_error(y_val, pred)) print("rmse: ", rmse(y_val, pred)) print("rmsle: ", rmsle(y_val, pred)) print("mape: ", mape(y_val, pred))
# 릿지 모델 from sklearn.linear_model import Ridge model = Ridge() model.fit(X_tr, y_tr) pred = model.predict(X_val) print("r2: ", r2_score(y_val, pred)) print("mae: ", mean_absolute_error(y_val, pred)) print("mse: ", mean_squared_error(y_val, pred)) print("rmse: ", rmse(y_val, pred)) print("rmsle: ", rmsle(y_val, pred)) print("mape: ", mape(y_val, pred))

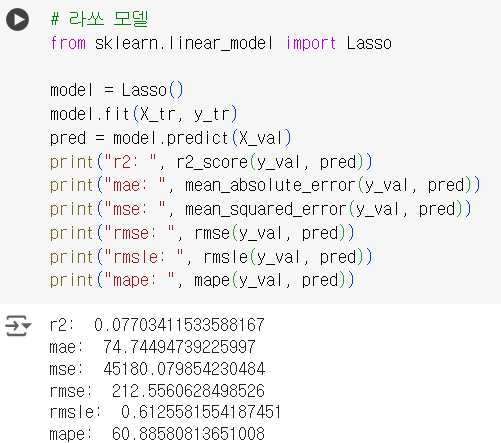
# 라쏘 모델 from sklearn.linear_model import Lasso model = Lasso() model.fit(X_tr, y_tr) pred = model.predict(X_val) print("r2: ", r2_score(y_val, pred)) print("mae: ", mean_absolute_error(y_val, pred)) print("mse: ", mean_squared_error(y_val, pred)) print("rmse: ", rmse(y_val, pred)) print("rmsle: ", rmsle(y_val, pred)) print("mape: ", mape(y_val, pred))
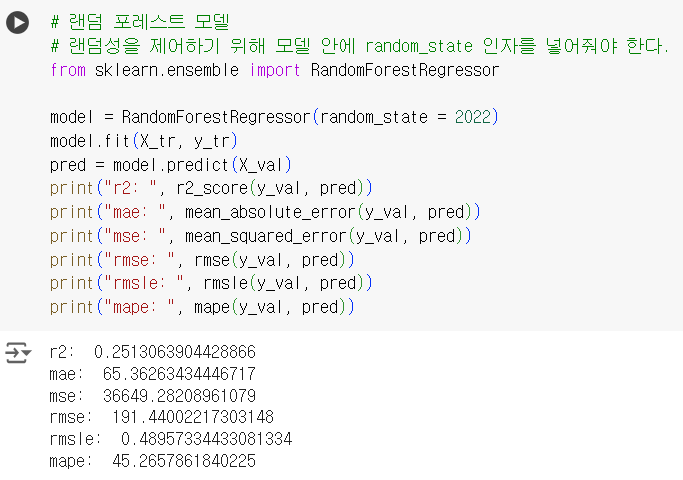
# 랜덤 포레스트 모델 # 랜덤성을 제어하기 위해 모델 안에 random_state 인자를 넣어줘야 한다. from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor(random_state = 2022) model.fit(X_tr, y_tr) pred = model.predict(X_val) print("r2: ", r2_score(y_val, pred)) print("mae: ", mean_absolute_error(y_val, pred)) print("mse: ", mean_squared_error(y_val, pred)) print("rmse: ", rmse(y_val, pred)) print("rmsle: ", rmsle(y_val, pred)) print("mape: ", mape(y_val, pred))
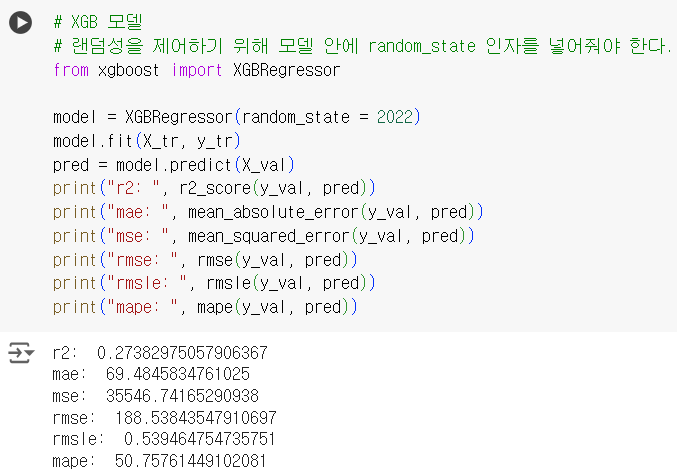
# XGB 모델 # 랜덤성을 제어하기 위해 모델 안에 random_state 인자를 넣어줘야 한다. from xgboost import XGBRegressor model = XGBRegressor(random_state = 2022) model.fit(X_tr, y_tr) pred = model.predict(X_val) print("r2: ", r2_score(y_val, pred)) print("mae: ", mean_absolute_error(y_val, pred)) print("mse: ", mean_squared_error(y_val, pred)) print("rmse: ", rmse(y_val, pred)) print("rmsle: ", rmsle(y_val, pred)) print("mape: ", mape(y_val, pred))
📌 예측 및 csv 제출
pred = model.predict(test)

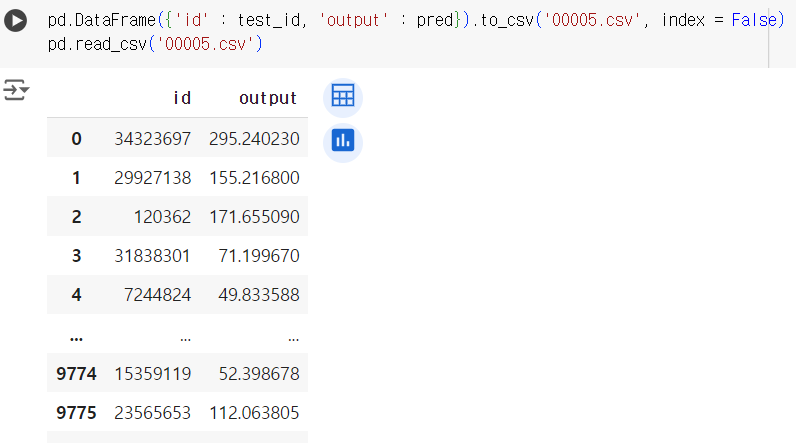
pd.DataFrame({'id' : test_id, 'output' : pred}).to_csv('00005.csv', index = False) pd.read_csv('00005.csv')

커피 좋아하는 데이터 꿈나무