
#INTRO
6주년 축하 !

아웃백 : )
#코드카타 (09:00 ~ 10:00)
-
SQL
TRUNCATE함수 : 소수점 N번째 자리까지만 출력, 이후 소수점 절삭# 소수점 4번째까지만 출력 SELECT TRUNCATE(SUM(LAT_N), 4) FROM STATION WHERE LAT_N BETWEEN 38.7880 AND 137.2345
-
PYTHON
-
문제를 단계별로 나누어 큰 틀을 잡고 코딩하는 습관 들이기
문제 단계별 진행 # 1. n을 k진수로 변환 : 정수 n을 k진수로 변환 # 2. k진수 문자열을 0 기준으로 분리 : # 변환된 k진수 문자열을 '0'을 기준으로 분리하여 소수 후보들 추출 # 3. 소수 판별 함수 작성 : 각 후보 숫자가 소수인지 판별하는 함수 작성 # 4. 소수 갯수 계산 : 조건에 맞는 소수의 갯수 카운팅 def is_prime(num): # 숫자가 소수인지 판별하는 함수 if num <= 1: return False # 1 이하의 숫자는 소수가 아님 if num == 2: return True # 2는 소수 if num % 2 == 0: return False # 짝수는 소수가 아님 sqr = int(num**0.5) + 1 # 숫자의 제곱근을 구함 for divisor in range(3, sqr, 2): if num % divisor == 0: return False # 약수가 존재하면 소수가 아님 return True # 위 조건을 모두 통과하면 소수 def solution(n, k): # 주어진 n을 k진수로 변환하고 조건에 맞는 소수의 개수를 세는 함수 # 1. : n을 k진수로 변환 k_base_str = "" while n > 0: k_base_str = str(n % k) + k_base_str # n을 k로 나눈 나머지를 문자열에 추가 n //= k # n을 k로 나눈 몫으로 갱신 # 2 : k진수 문자열을 0 기준으로 분리 candidates = k_base_str.split('0') # '0'을 기준으로 문자열 분리 # 3: 소수 판별 함수 prime_count = 0 for candidate in candidates: if candidate and is_prime(int(candidate)): # 빈 문자열이 아니고 소수이면 prime_count += 1 # 소수 개수 증가 return prime_count # 최종 소수 개수 반환
-
# 프로젝트 진행 (10:00 ~ 23:00)
-
군집 분석 시도
목표 : 17만 개 데이터셋으로 군집 분석 후 군집 결과가 좋은 모델 찾기
군집 분석에 대한 코드와 방법은 어느정도 정리가 된 것 같다.
하지만 17만 개 데이터셋으로 실루엣 계수가 높은 군집을 찾아내는 것..
반복적인 시도에도 원하는 결과를 얻어낼 수 없었다.
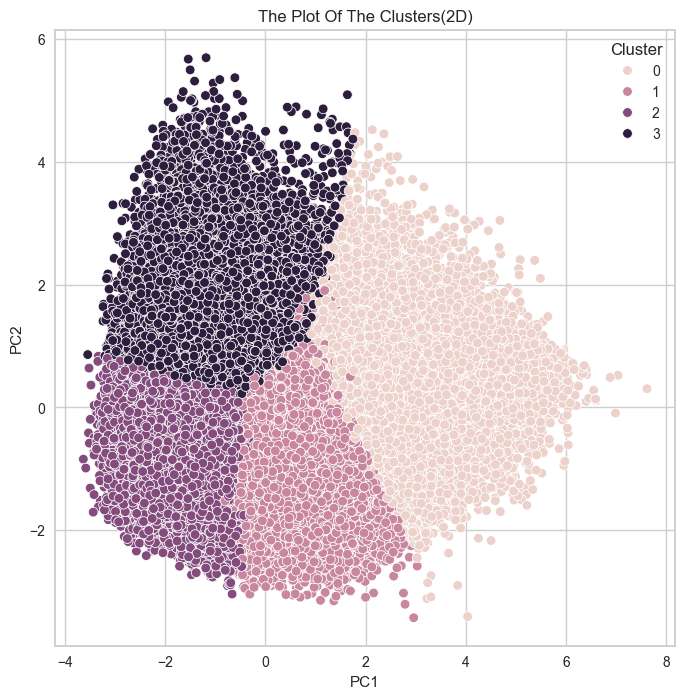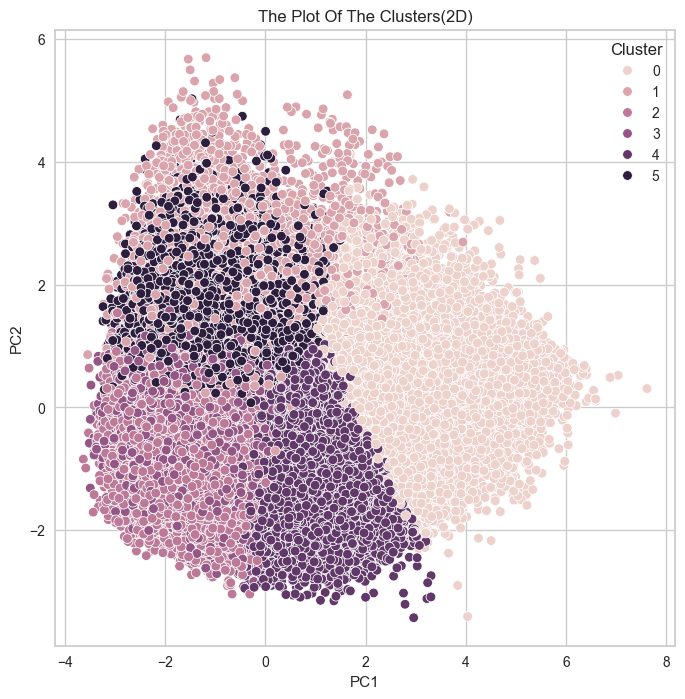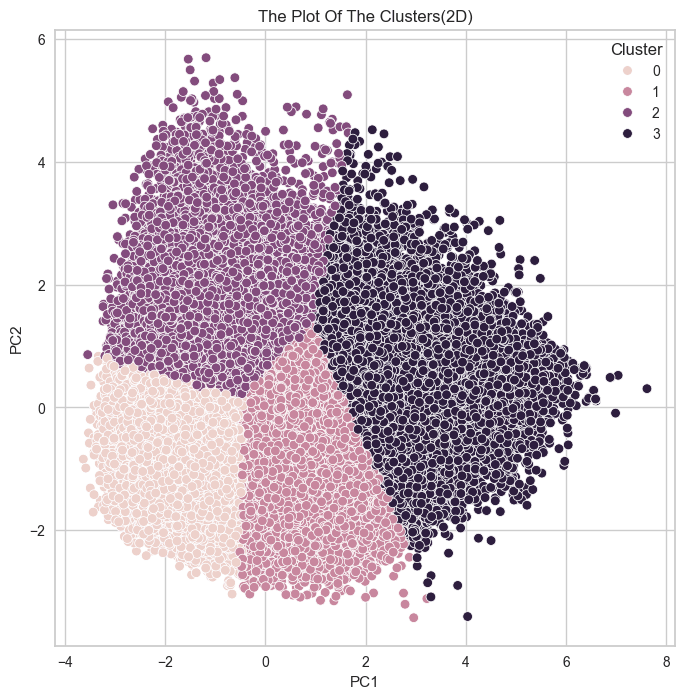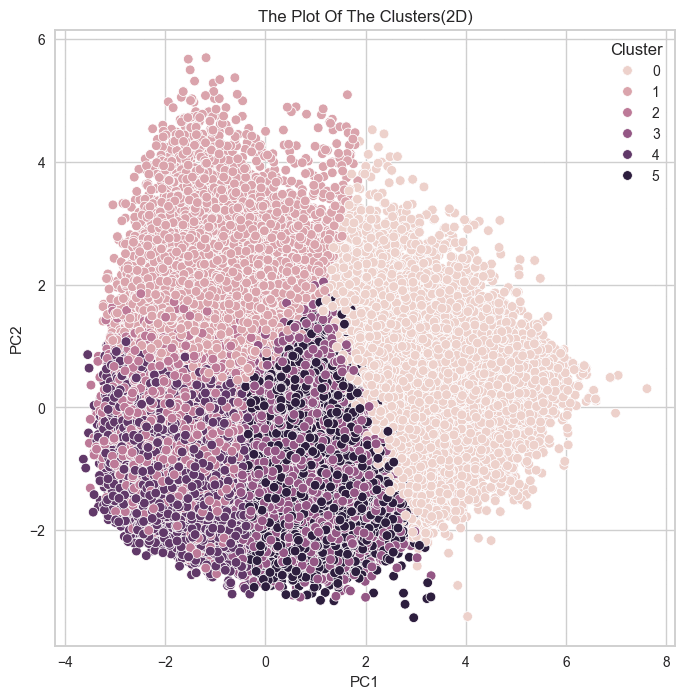
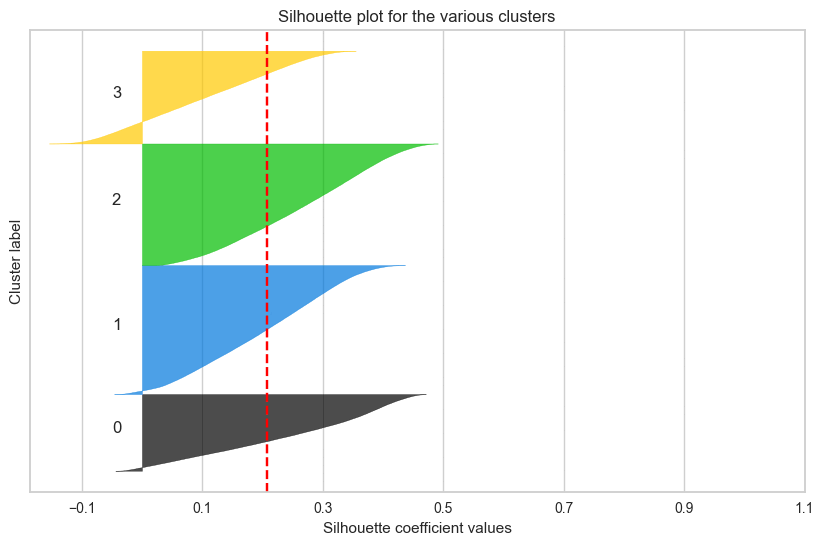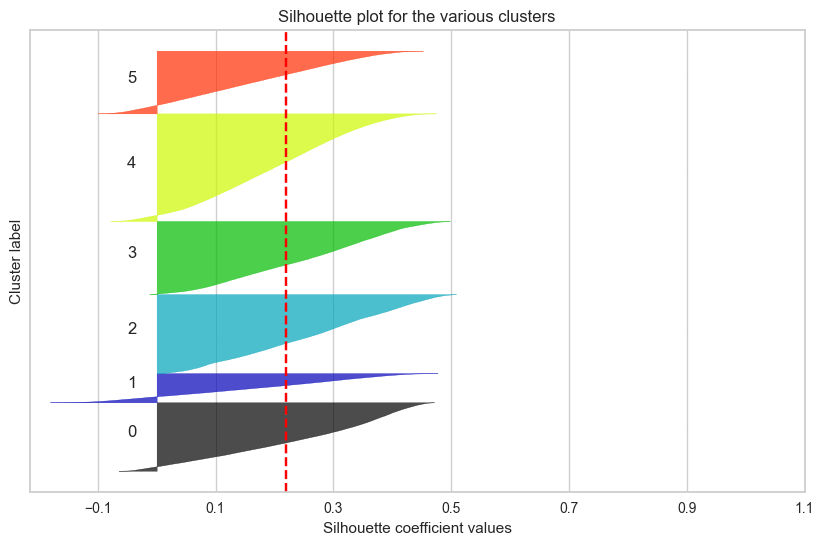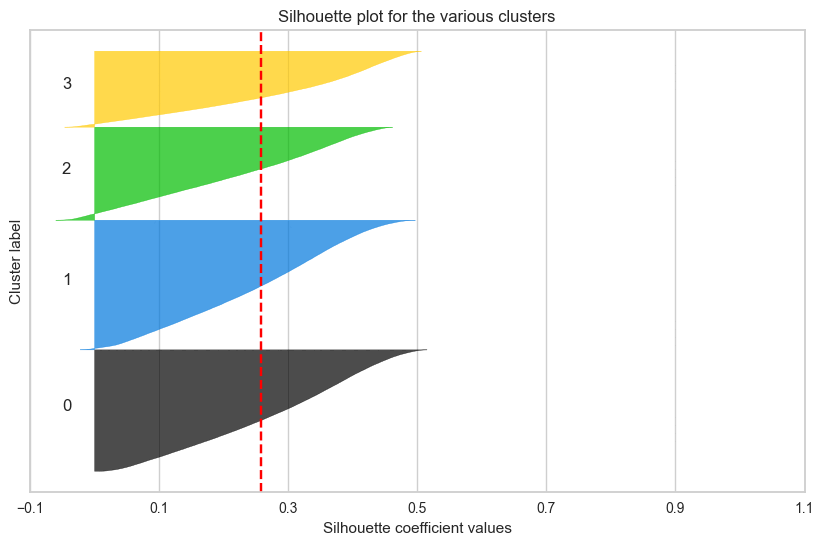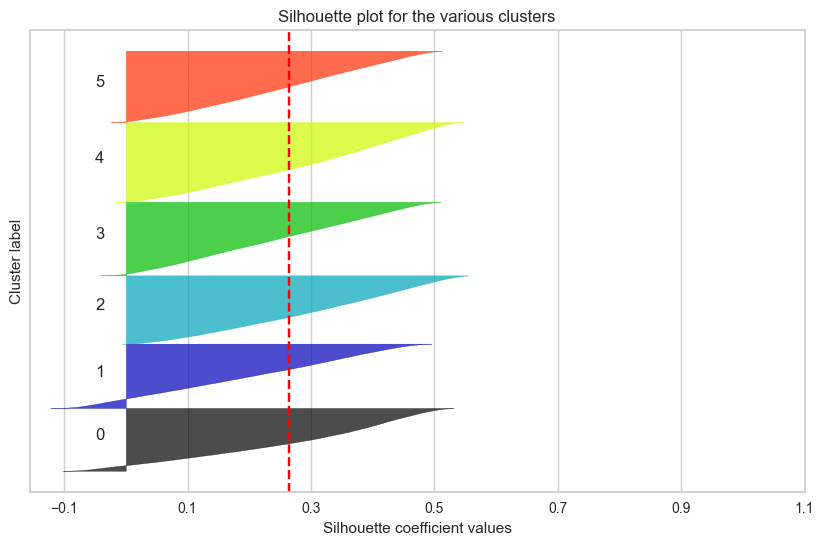
군집 결과를 실루엣 계수로만 확인했던 것이
옳은 방향이 아니었다는 것을 깨닳았다.
정리하자면, 우리가 지금 하려고 하는 군집 분석의 목적은
음원들을 우리가 알지 못하는 어떤 특성들끼리 묶이는 (군집 되는) 그룹들을 발견하고
그 군집들의 특성을 파악하여 서비스에 (추천 시스템) 적용하는 것인데,
실루엣 계수가 높다는 것은 각 데이터 간의 거리가 밀도있게 응집되어 있다는 뜻이고,
군집별로 실루엣 계수가 높아서 잘 뭉쳐져 있다면,
음악이라는 특성상 같은 노래? 같은 느낌? 을 나타내는 음악이 될 것이고,
추천 서비스에서 추천을 받는 고객 입장에서 비슷한 음악 추천을 받는 것이
어떤 의미인지에 대해 다시 고민해볼 필요가 있다는 것이었다.
(비슷하지만 새로운 음악을 추천 받고 싶지 않을까?)
따라서 단순히 실루엣 계수가 높은 군집을 찾기보다는
음악의 특성을 잘 나타낼 수 있는 변수들을 잘 선택하고,
그 변수들을 최대한 효율적으로 전처리, 군집화하여
그 군집들의 특성을 정성적으로 평가하는 것이 중요할 것이다. 라는 결론.- 4일차 스크럼 정리
튜터님의 튜터링 후 방향성을 다시 잡았다.
서비스에 필요한 군집이 무엇인지 다시 고민,
음악의 특성을 나타내는 변수(컬럼)들을 추가하고 제거해보면서,
이상치 제거, 표준화 등의 전처리를 수행하고,
PCA 분석을 통한 차원 축소로 효율을 높이고,
K-means, 계층 군집, GWMM(가우시안혼합모델), DBSCAN 등의 군집 알고리즘을 활용해서
최대한 잘 군집화가 된 군집을 찾아낸 후,
군집 간의 특성을 확인 !
(군집 간의 특성을 정성적으로 평가하면서, 음악을 잘 묶어낼 수 있는지를 확인)
- 내일까지 해야할 내용 :
추가적인 군집화 시도, 군집 간 특성 확인, 유의미한 군집 찾아내기
#OUTRO
오늘의 한 줄.
화이팅 ......... !

커피 좋아하는 데이터 꿈나무