
#INTRO
이동하는 시간도 코드 돌리기 : )
결과 내는 것에 연연하지 말아야 하는데..
#코드카타 (09:00 ~ 10:00)
-
SQL
MAX와TRUNCATE함수 활용# 가장 큰 LAT_N 값의 소수점 4자리까지 잘라서 반환 # MAX(LAT_N)으로 찾은 최대 LAT_N 값을 소수점 이하 4자리까지 SELECT TRUNCATE(MAX(LAT_N), 4) FROM STATION #LAT_N 값이 137.2345보다 작은 레코드들만 선택 WHERE LAT_N < 137.2345
-
PYTHON
defaultdict는 기본값을 가지는 딕셔너리로,
키가 존재하지 않는 경우에도 자동으로 기본값을 반환하여
코드에서 추가적인 존재 여부 확인과 초기화를 할 필요가 없다.# 일반 딕셔너리 사용 parking_times = {} # 입차 시간 기록 및 누적 주차 시간 계산 for car_number in car_numbers: if car_number not in parking_times: parking_times[car_number] = 0 parking_times[car_number] += time_spent # defaultdict 사용 from collections import defaultdict # defaultdict를 사용하여 기본값이 0인 딕셔너리 생성 parking_times = defaultdict(int) # 입차 시간 기록 및 누적 주차 시간 계산 for car_number in car_numbers: parking_times[car_number] += time_spent00:00시간 형식을 분으로 변환하기# 시간을 "HH:MM" 형식에서 분 단위로 변환하는 함수 def convert_to_minutes(time_str): hh, mm = map(int, time_str.split(':')) return hh * 60 + mm
#프로젝트 진행 (10:00 ~ 22:00)
-
결과 정리
-
목표 : 여러 군집 분석 방법을 적용하고 최적의 군집 선택하기
여러 변수들의 추가, 삭제 / 주성분 갯수 조절 / K 값 조절 등
한 데이터로 전처리 ~ 군집 분석까지 해볼 수 있는 것은 거의 다 해본 것 같다..
무언가 이미 전처리가 되어 있는 듯한 (0~1값을 가진) 데이터의 특성과
표준화만 진행하고 군집화를 하는 것으로는
군집 성능 (실루엣 계수)을 높이는 데 한계가 있다고 판단했다.
- 사용 컬럼 :
cols = ['valence', 'acousticness', 'danceability',
'energy', 'instrumentalness', 'key', 'liveness',
'loudness', 'tempo', 'mode']
- 제거 컬럼 :
1. year (발매 연도)
음악의 발매 연도는 군집분석에서 음악의 특성보다는 시간적 흐름을 반영하는 변수
군집을 형성할 때 음악의 내용보다는 시대적 배경에 따라 군집이 형성될 수 있어,
음원 자체의 특성을 파악하는 데 적합하지 않을 것으로 판단.
2. artists (아티스트 리스트)
아티스트의 이름은 범주형 데이터로, 군집분석의 수치적 분석에 적합하지 않음.
아티스트마다 다양한 스타일이 존재하므로,
개별 아티스트의 특성을 모두 반영하기 어려울 것으로 판단.
3. explicit (음원에 부적절한 내용 여부)
explicit 변수는 0 또는 1의 이진 변수로,
음악의 특성보다는 가사의 내용에 집중된 변수로 판단.
4. id (고유 식별자)
id는 각 음원의 고유 식별자이므로,
군집분석에 의미 있는 정보를 제공하지 않을 것으로 판단.
5. release_date (발매일)
release_date는 year와 유사하게 시간적 흐름을 반영하는 변수로,
음악의 특성보다는 발매 시점에 중점을 둠.
군집분석에서 음원의 내용보다는 시대적 배경에
영향을 미칠 수 있을 것으로 판단.
6. popularity (인기도)
Popularity 는 트랙의 인기도를 나타내는 변수로,
음악의 특성보다는 시간적 흐름을 반영하는 변수
주로 외부 요인에 의해 결정, 특정 시기에 바이럴이 되거나,
유명 아티스트가 새로 발매한 음악이
순간적으로 높은 인기를 얻을 수 있을 것으로 판단.
7. speechiness (말의 비율)
speechiness 는 랩, 스포큰 워드 등의
특정 장르의 중요한 정보가 될 수 는 있지만,
음악의 특성을 반영하는 데 있어서는 제한적일 것으로 판단.
# 데이터 불러오기
sp_df = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/spotify_clustering/data.csv')
# 음악 특징과 관련이 있는 컬럼 선택
cols = ['valence', 'acousticness', 'danceability', 'energy', 'instrumentalness', 'key', 'liveness', 'loudness', 'tempo', 'mode']
# 데이터 스케일링 (스탠다드)
from sklearn.preprocessing import StandardScaler
sd = StandardScaler()
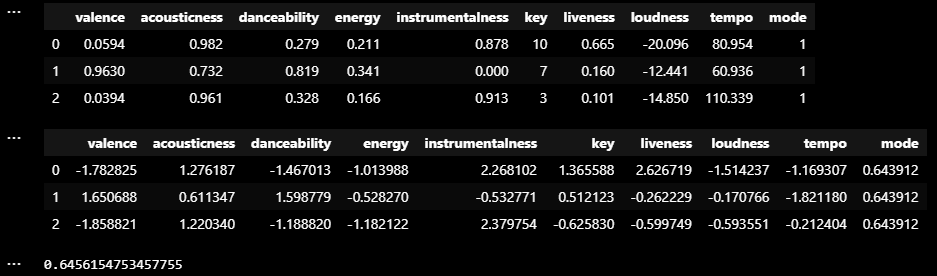
display(sp_df[cols].head(3))
sp_df[cols] = sd.fit_transform(sp_df[cols])
# sp_w_df[scale_cols] = rs.fit_transform(sp_w_df[scale_cols])
display(sp_df[cols].head(3))
df_scaled = sp_df[cols]
# 주성분 개수를 판단하기 위한 pca 임의 시행 (3 ~ 7)
pca = PCA(n_components = 4)
pca.fit(df_scaled)
# 설정한 주성분의 갯수로 전체 데이터 분산을 얼만큼 설명 가능한지
print(pca.explained_variance_ratio_.sum())
# pca 시행
pca_df = pca.fit_transform(df_scaled)
pca_df = pd.DataFrame(data = pca_df, columns = ['PC1','PC2','PC3', 'PC4'])
pca_df.head()
# KMEANS
# 군집개수(n_cluster) 4 ~ 7, 초기 중심 설정방식 랜덤
optimal_k = 4
kmeans = KMeans(n_clusters = optimal_k, random_state = 42, init = 'random')
# pca df 를 이용한 kmeans 알고리즘 적용
kmeans.fit(pca_df)
clusters = kmeans.fit_predict(pca_df)
# 클러스터 번호 가져오기
labels = kmeans.labels_
# 클러스터 번호가 할당된 데이터셋 생성
kmeans_df = pd.concat([pca_df, pd.DataFrame({'Cluster' : labels})], axis = 1)
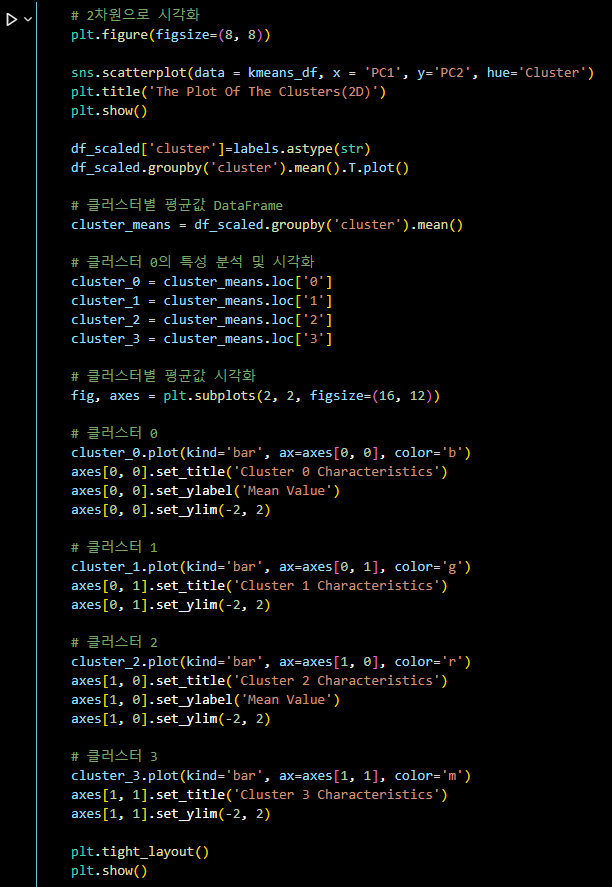
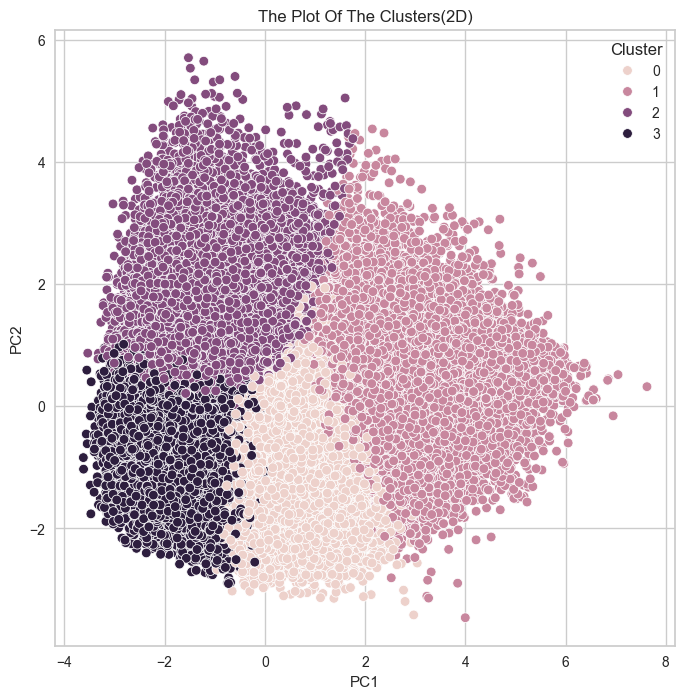
# 2차원으로 시각화
plt.figure(figsize=(8, 8))
sns.scatterplot(data = kmeans_df, x = 'PC1', y='PC2', hue='Cluster')
plt.title('The Plot Of The Clusters(2D)')
plt.show()
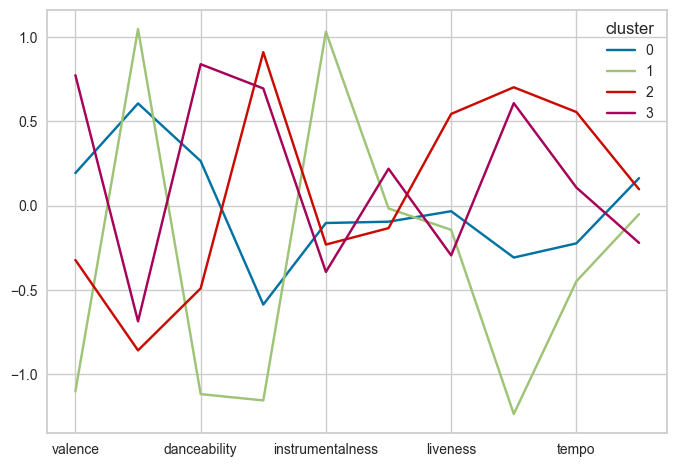
df_scaled['cluster']=labels.astype(str)
df_scaled.groupby('cluster').mean().T.plot()
# 클러스터별 평균값 DataFrame
cluster_means = df_scaled.groupby('cluster').mean()
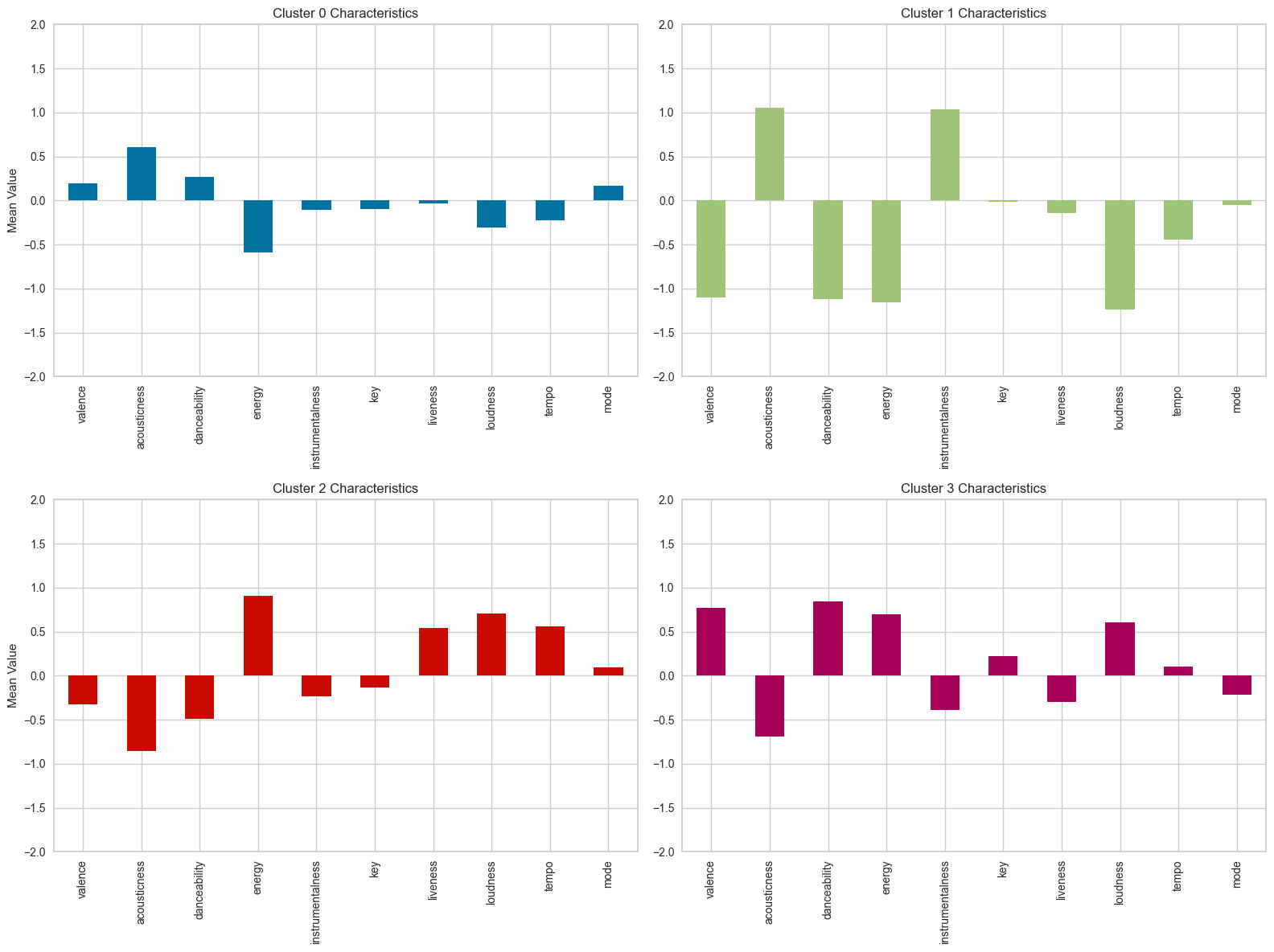
# 클러스터 0의 특성 분석 및 시각화
cluster_0 = cluster_means.loc['0']
cluster_1 = cluster_means.loc['1']
cluster_2 = cluster_means.loc['2']
cluster_3 = cluster_means.loc['3']
# 클러스터별 평균값 시각화
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
# 클러스터 0
cluster_0.plot(kind='bar', ax=axes[0, 0], color='b')
axes[0, 0].set_title('Cluster 0 Characteristics')
axes[0, 0].set_ylabel('Mean Value')
axes[0, 0].set_ylim(-2, 2)
# 클러스터 1
cluster_1.plot(kind='bar', ax=axes[0, 1], color='g')
axes[0, 1].set_title('Cluster 1 Characteristics')
axes[0, 1].set_ylim(-2, 2)
# 클러스터 2
cluster_2.plot(kind='bar', ax=axes[1, 0], color='r')
axes[1, 0].set_title('Cluster 2 Characteristics')
axes[1, 0].set_ylabel('Mean Value')
axes[1, 0].set_ylim(-2, 2)
# 클러스터 3
cluster_3.plot(kind='bar', ax=axes[1, 1], color='m')
axes[1, 1].set_title('Cluster 3 Characteristics')
axes[1, 1].set_ylim(-2, 2)
plt.tight_layout()
plt.show()-
분석 플로우
-
변수 선정
-
전처리(Standard Scaling ; 표준화만 진행)
-
PCA 분석을 통한 차원 축소 (PCA = 4개 ; 설명력 0.65 %)
-
군집 갯수 설정 (4개)
-
결국 군집 결과를 평가해야 한다.
데이터 전처리 과정에서 일부러 배제했던 과정이 이상치 제거였다.
이상치를 어떤 기준으로 판단하고 제거할 지에 대한 논리가 나 스스로 설득이 되지 않아서, 이상치 제거하는 것을 꺼려했던 것인데,
팀원 중 Isolation Forest 기법을 활용한 이상치 제거로 17만 개 데이터 중 4만 개 (약 25%) 의 이상치를 제거 후 군집을 시도한 결과가
군집 실루엣 계수도 높을 뿐더러 군집화가 잘 되어 보였다.
튜터님들께 튜터링을 받은 결과,
이상치 제거에 대한 과정에서 문제가 없다면, (이상치가 좀 많이 제거된 경향은 없지않지만)
이상치가 제거된 후의 군집 성능이 좋은 것이 활용하기에 더 좋을 것이다.
라는 결론을 내렸다.
따라서 우리는 이상치를 제거하고 표준화를 진행한 후,
군집이 잘 된 (실루엣 계수의 분포도 잘 이루어진) 군집을 활용해
군집별 특성을 파악하고 음원 추천 서비스에 적용하는 결론을 내릴 것이다.- 5일차 스크럼 정리
변수 선택 - 이상치 제거 - 표준화 - 주성분 분석 - 군집화
가장 좋은 군집 시각화와 실루엣 계수, 분포를 보여주는 군집을 활용해
군집별 특성을 분석하고 음원 추천 서비스에 적용하는 방안 탐색하기 !
이제 보고서에 잘 녹이는 일만 남았다.
화이팅!#OUTRO
오늘의 한 줄.
경험과 과정에도 의의를 두자 !

커피 좋아하는 데이터 꿈나무