
개요
이커머스 분야에서 사용하는 데이터를 수집하는 방법과 전처리하는 방법에 대한 학습
📌 이커머스 데이터 수집과 전처리
📌 이커머스 데이터 수집 도구법
-
API (Application Programming Interface)
-
정의: 특정 서비스나 플랫폼에서 제공하는 프로그래밍 인터페이스를 통해 데이터에 접근하는 방식
-
예시: Amazon, e-Bay, Shopify 등에서 제공하는 API key를 통해 데이터에 접근하여 사용
-
장점: 구조화된 데이터 제공, 비교적 쉬운 접근
-
import requests
api_url = 'https://api-gateway.coupang.com/v2/providers/affiliate_open_api/apis/openapi/v1/products'
params = {
'keyword': '식품',
'limit': 10
}
headers = {
'Authorization': 'Bearer YOUR_API_KEY'
}
response = requests.get(api_url, headers=headers, params=params)
data = response.json()
for product in data['data']:
print(product['productName'], product['price'])
Product Name 1, 10000
Product Name 2, 20000
Product Name 3, 15000
Product Name 4, 5000
Product Name 5, 25000
Product Name 6, 12000
Product Name 7, 30000
Product Name 8, 4500
Product Name 9, 7000
Product Name 10, 18000-
웹 크롤링(Web Crawling)
-
정의: 웹사이트의 데이터를 크롤링이라는 자동화된 방법으로 수집하는 방법
-
도구 및 라이브러리: BeautifulSoup, Requests, Scrapy, Selenium 등을 사용
-
과정: 웹 페이지의 HTML 구조 및 태그를 파악하여 필요한 데이터를 추출하는 방식 사용
-
import requests
from bs4 import BeautifulSoup
url = 'https://www.coupang.com/np/search?component=&q=라면'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
products = soup.find_all('div', class_='name')
for product in products:
print(product.get_text())-
데이터베이스 쿼리(Database Query) - 트랜잭션 데이터
-
정의: 내부 데이터베이스에서 직접 SQL 쿼리를 통해 데이터 수집하는 방식
-
필요 조건: 데이터베이스 접근 권한, SQL 쿼리 작성 능력
-
-
로그 데이터 (Log)
-
정의: 웹 서버, 애플리케이션 서버에서 발생하는 로그 파일을 분석하여 데이터를 수집하는 방식
-
활용 예시: 페이지 뷰, 클릭, 구매 등의 활동
-
import re
from collections import defaultdict
# 로그 파일의 경로
log_file_path = 'path/to/your/logfile.log'
# 로그 항목을 저장할 딕셔너리
log_data = defaultdict(lambda: {'page_view': 0, 'click': 0, 'purchase': 0})
# 로그 파일에서 로그 항목을 분석하는 정규 표현식
log_pattern = re.compile(
r'(?P<ip>\S+) \S+ \S+ \[(?P<datetime>[^\]]+)\] "(?P<method>\S+) (?P<url>\S+) \S+" \d+ \d+ "(?P<referrer>[^"]+)" "(?P<user_agent>[^"]+)"'
)
# 로그 파일을 읽고 분석
with open(log_file_path, 'r') as file:
for line in file:
match = log_pattern.match(line)
if match:
log_entry = match.groupdict()
url = log_entry['url']
# URL을 기반으로 페이지 뷰, 클릭, 구매 활동을 집계
if 'page_view' in url:
log_data[url]['page_view'] += 1
elif 'click' in url:
log_data[url]['click'] += 1
elif 'purchase' in url:
log_data[url]['purchase'] += 1
# 결과 출력
for url, counts in log_data.items():
print(f"URL: {url}")
print(f" Page Views: {counts['page_view']}")
print(f" Clicks: {counts['click']}")
print(f" Purchases: {counts['purchase']}")
print()-
소셜 미디어 데이터: 고객의 리뷰, 댓글, 좋아요 등을 분석하여 고객의 선호도와 피드백을 수집
-
고객 설문조사: 설문조사를 통해 직접적으로 고객의 의견 수집
📌 데이터 수집 도구
Google Analytics :
웹사이트 방문자 수, 페이지 뷰, 전환율 등의 데이터를 수집
Amplitude :
모바일/웹 사용자들을 분석하는 분석 도구
Mixpanel :
서비스에서 사용자가 어떻게 행동하는지 분석해주는, 사용자 행동기반의 제품 데이터 분석 툴
SurveyMonkey : 설문조사를 통해 고객의 피드백을 수집
📌 로그 데이터의 이해와 활용
로그 데이터란?
-
정의 : 로그 데이터는 웹사이트나 애플리케이션에서 사용자의 행동을 기록한 데이터
예를 들어, 페이지 방문, 클릭, 검색 등의 활동이 포함 -
구성 요소 : 로그 데이터는 주로 타임스탬프, 사용자 ID, 이벤트 유형, 페이지 URL 등의 정보를 포함
로그 데이터 활용
-
고객 행동 분석 : 고객이 어떤 경로를 통해 구매에 이르는지 분석
-
마케팅 캠페인 효율성 측정 : 특정 캠페인이 얼마나 많은 트래픽과 전환을 유도했는지 평가
-
웹사이트 성능 최적화 : 페이지 로딩 시간, 오류 발생 등을 모니터링하여 웹사이트 성능 개선
JSON 형태
[
{
"user_id": "user123",
"timestamp": "2024-07-24T12:34:56",
"action": "visit",
"page": "homepage"
},
{
"user_id": "user456",
"timestamp": "2024-07-24T12:35:00",
"action": "click",
"page": "product_page",
"product_id": "prod789"
},
{
"user_id": "user123",
"timestamp": "2024-07-24T12:36:10",
"action": "search",
"query": "laptop"
}
]- JSON → TABLE 코드
import pandas as pd
import json
# JSON 데이터
json_data = [
{
"user_id": "user123",
"timestamp": "2024-07-24T12:34:56",
"action": "visit",
"page": "homepage"
},
{
"user_id": "user456",
"timestamp": "2024-07-24T12:35:00",
"action": "click",
"page": "product_page",
"product_id": "prod789"
},
{
"user_id": "user123",
"timestamp": "2024-07-24T12:36:10",
"action": "search",
"query": "laptop"
}
]
# JSON을 DataFrame으로 변환
df = pd.json_normalize(json_data)
print(df)TABLE 형태
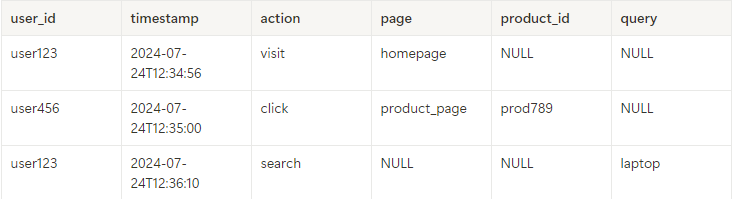
- JSON → TABLE 코드
# DataFrame을 JSON으로 변환
json_result = df.to_json(orient="records", date_format="iso")
parsed = json.loads(json_result)
print(json.dumps(parsed, indent=4))📌 이커머스 데이터 정제 및 전처리 기법
데이터 정제 및 전처리 기법
- 데이터 정제(Cleaning):
- 결측값 처리: 삭제, 대체 등 방법을 통해 누락된 데이터를 처리.
- 이상값 처리: 비정상적으로 큰 값이나 작은 값을 처리.
- 데이터 변환(Transformation):
- 형식 변환: 필요한 분석에 맞게 데이터 형식을 변환.
- 스케일링: 데이터 범위를 일정하게 조정.
- 피처 엔지니어링(Feature Engineering):
- 새로운 피처 생성: 기존 데이터를 바탕으로 새로운 분석 지표 생성.
- 피처 선택: 분석에 중요한 피처만 선택하여 데이터셋을 단순화.
- 데이터 통합(Integration):
- 여러 출처의 데이터를 통합하여 하나의 일관된 데이터셋을 만듦.
📌 데이터 정제 / 전처리 기법
정제 기법
-
중복 제거: 동일한 데이터가 여러 번 기록된 경우 이를 제거
-
오타 수정: 텍스트 데이터에서 발생하는 오타를 수정
-
불필요한 데이터 제거: 분석에 필요하지 않은 데이터를 제거
전처리 기법
-
데이터 변환: 범주형 데이터를 숫자로 변환하거나, 날짜 형식을 통일
-
정규화: 데이터 값을 일정한 범위로 조정하여 분석을 용이하게 한다.
- 데이터 정제
중복 제거
# 중복 제거
df_cleaned = df.drop_duplicates()
print("\\nAfter Removing Duplicates:")
print(df_cleaned)오타 수정
# 예시로 'prod789'에 오타가 있는 경우 수정
df_cleaned['product_id'] = df_cleaned['product_id'].replace({'prod789': 'product789'})
print("\\nAfter Correcting Typos:")
print(df_cleaned)불필요한 데이터 제거
# 분석에 필요하지 않은 열 제거 (예시로 'price' 열 제거)
df_cleaned = df_cleaned.drop(columns=['price'])
print("\\nAfter Removing Unnecessary Columns:")
print(df_cleaned)- 데이터 전처리
데이터 변환
# 범주형 데이터를 숫자로 변환 (예시로 'action' 열 변환)
df_cleaned['action'] = df_cleaned['action'].map({'visit': 0, 'click': 1, 'search': 2})
print("\\nAfter Converting Categorical Data:")
print(df_cleaned)정규화
# 정규화 (예시로 'action' 열 정규화)
df_cleaned['action'] = (df_cleaned['action'] - df_cleaned['action'].min()) / (df_cleaned['action'].max() - df_cleaned['action'].min())
print("\\nAfter Normalization:")
print(df_cleaned)📌 결측치 처리 / 이상치 탐지
결측치 처리
-
삭제: 결측치가 있는 행을 삭제
-
대체: 평균값, 중앙값, 최빈값 등으로 결측치를 대체
-
예측: 머신러닝 모델을 사용해 결측치를 예측하여 채운다.
이상치 탐지
-
기술 통계 활용: 평균, 표준편차 등을 활용해 데이터 분포를 파악하고 이상치 탐지
-
시각화 기법: 박스 플롯, 산점도 등을 사용해 이상치를 시각적으로 탐지
- 결측치 처리 및 이상치 탐지
결측치 처리
# 결측치가 있는 행 삭제
df_dropped = df_cleaned.dropna()
print("\\nAfter Dropping Rows with Missing Values:")
print(df_dropped)# 결측치를 특정 값으로 대체 (예시로 평균값으로 대체)
df_filled = df_cleaned.fillna(df_cleaned.mean(numeric_only=True))
print("\\nAfter Filling Missing Values with Mean:")
print(df_filled)이상치 탐지
# 기술 통계 활용
print("\\nDescriptive Statistics:")
print(df_cleaned.describe())import matplotlib.pyplot as plt
# 박스 플롯으로 이상치 탐지
plt.boxplot(df_cleaned['action'])
plt.title("Box Plot of 'action'")
plt.show()📌 레퍼런스 & QnA
📌 레퍼런스
📌 QnA
NPS 점수는 어떻게 수집 가능하나요❓
- 설문조사 / 구글 리뷰
업계 평균 지표는 어떻게 알 수 있나요❓
