
#INTRO
먹어본 닭갈비 중 최고..(📍 춘천 장군봉 박사마을 닭갈비)

#SQL Quiz
-
CODEKATA SQL하고 싶은데.... 무료 문제를 다 풀었다 : )
유료 문제를 프로젝트 기간에 구독해서 풀기는 아까울 것 같아서,
방법을 찾아봐야겠다ㅋㅋ -
오늘은 찾다 찾다 SQL Quiz 를 풀어봤다.
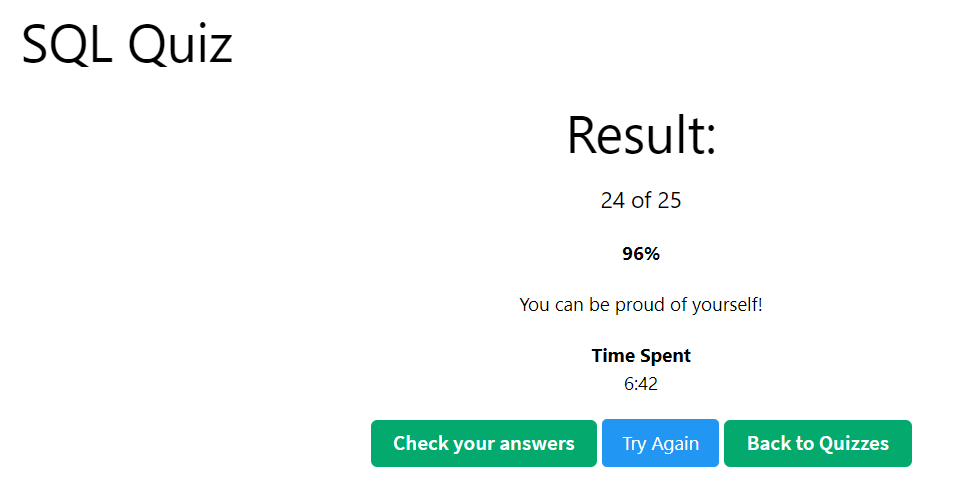
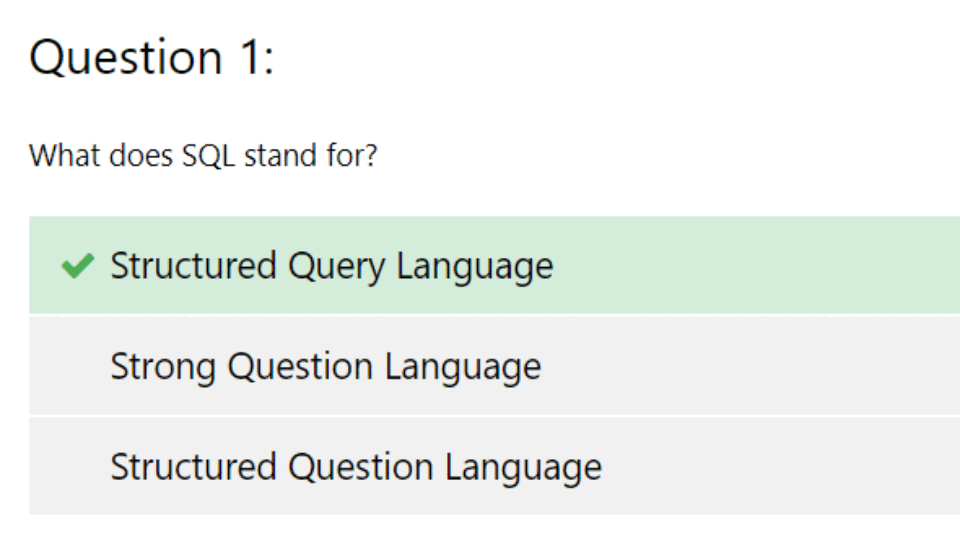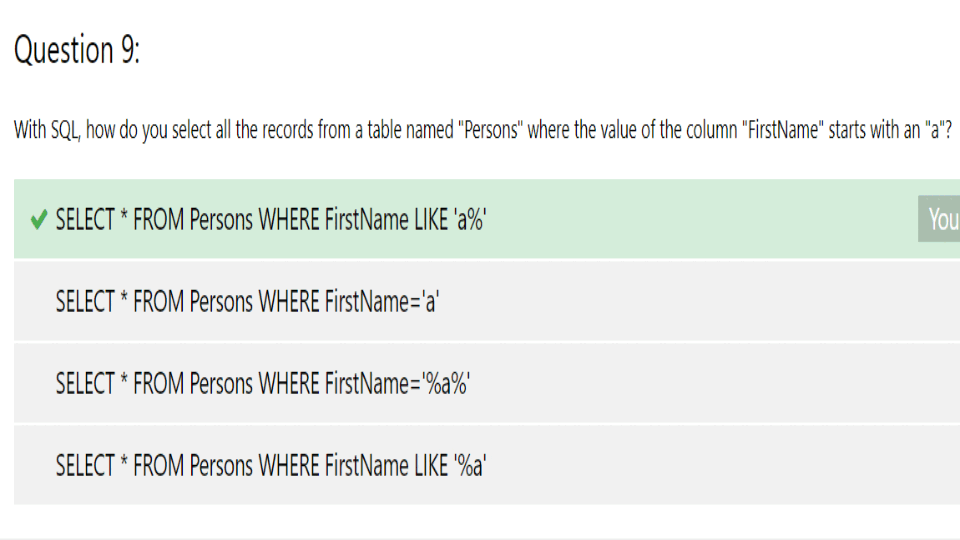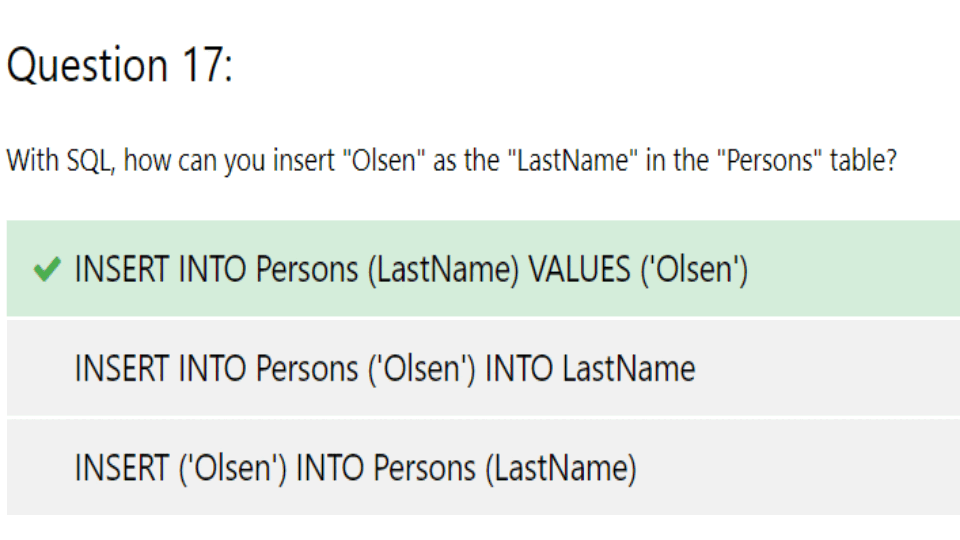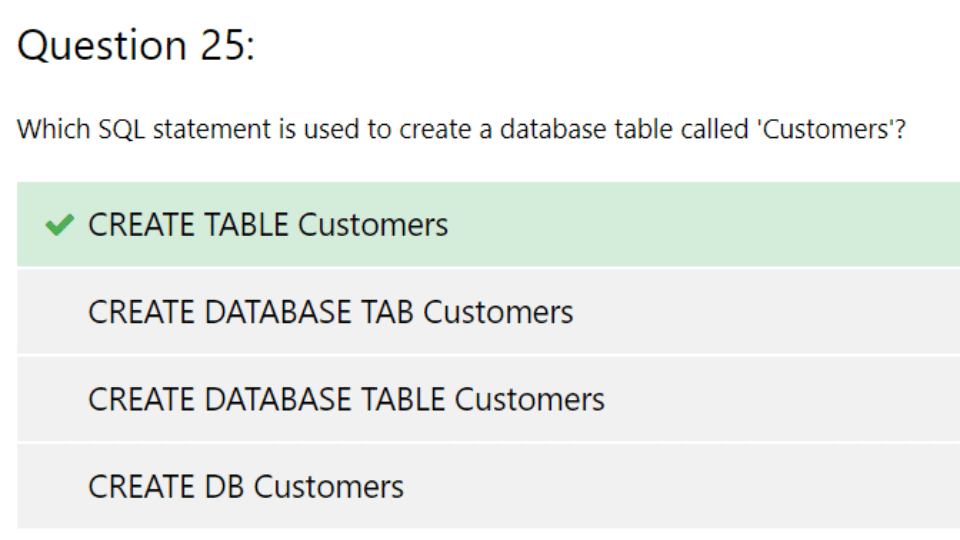
쿼리를 작성하기보다 SQL 기본 개념을 물어보는 문제.ㅋㅋ
#최종 프로젝트 진행
로지스틱 회귀 모델 & 랜덤 포레스트 모델
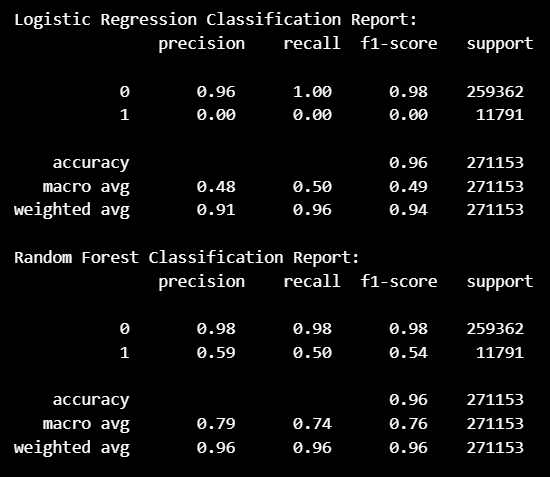
두 모델 모두 이탈 고객 예측 ( =
1) 에 대한
성능이 떨어지는 것을 확인할 수 있다.
전체 데이터 (135만 개) 중 이탈 고객 1 값이
6만 개가 채 되지 않아서 생기는 문제인 것으로 판단.
SMOTE를 활용한 오버 샘플링
-
SMOTE(Synthetic Minority Over-sampling Technique) :
데이터셋에서 클래스 불균형 문제를 해결하기 위해 사용되는 기술 중 하나 -
SMOTE의 원리
-
소수 클래스 샘플 선택 :
먼저 소수 클래스의 데이터를 선택한다. -
최근접 이웃 찾기 :
선택된 소수 클래스 샘플의 최근접 이웃(k-Nearest Neighbors)을
찾는다. 기본적으로 k=5를 사용 -
새로운 샘플 생성 :
선택된 샘플과 그 최근접 이웃들 사이에 새로운 샘플 생성
새로운 샘플은 선택된 샘플과 이웃 샘플 사이의
선형 보간(Linear Interpolation)을 통해 생성된다.
-
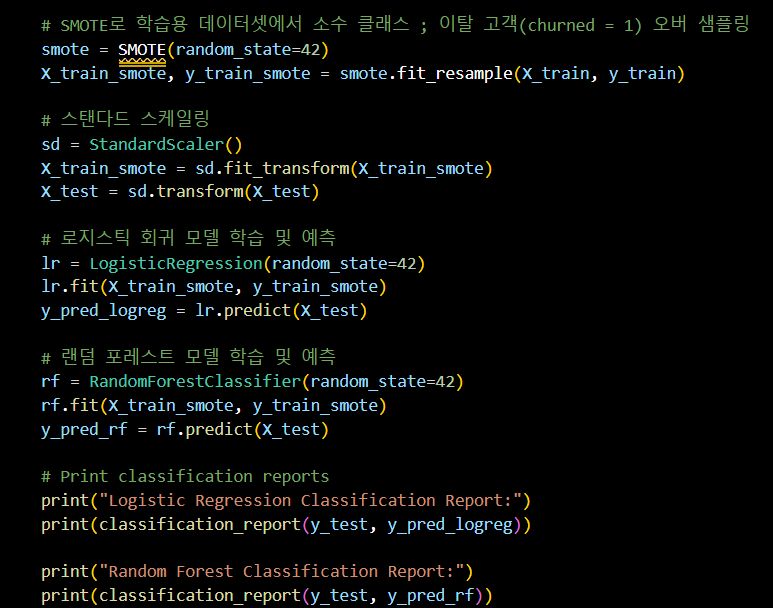
from imblearn.over_sampling import SMOTE
# SMOTE로 학습용 데이터셋에서 소수 클래스 ; 이탈 고객(churned = 1) 오버 샘플링
smote = SMOTE(random_state=42)
X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)
# 스탠다드 스케일링
sd = StandardScaler()
X_train_smote = sd.fit_transform(X_train_smote)
X_test = sd.transform(X_test)
# 로지스틱 회귀 모델 학습 및 예측
lr = LogisticRegression(random_state=42)
lr.fit(X_train_smote, y_train_smote)
y_pred_logreg = lr.predict(X_test)
# 랜덤 포레스트 모델 학습 및 예측
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train_smote, y_train_smote)
y_pred_rf = rf.predict(X_test)
# Print classification reports
print("Logistic Regression Classification Report:")
print(classification_report(y_test, y_pred_logreg))
print("Random Forest Classification Report:")
print(classification_report(y_test, y_pred_rf))결과
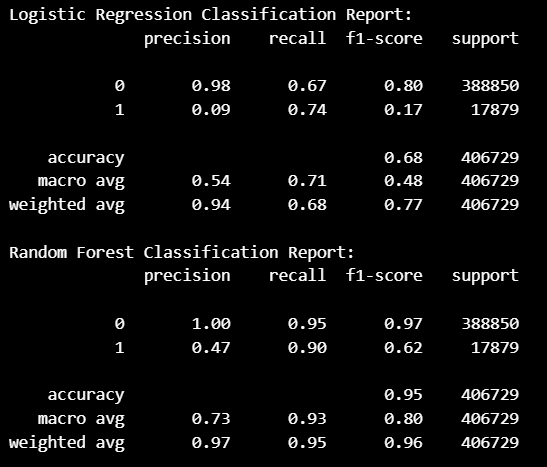
Recall과 F1-score에서 수치가 향상되기는 했지만,
만족스러운 성능은 아닌 듯..
#OUTRO
오늘의 한 줄.
알찬 주말 끝 !

커피 좋아하는 데이터 꿈나무
leetcode 넘어와여ㅎㅎ