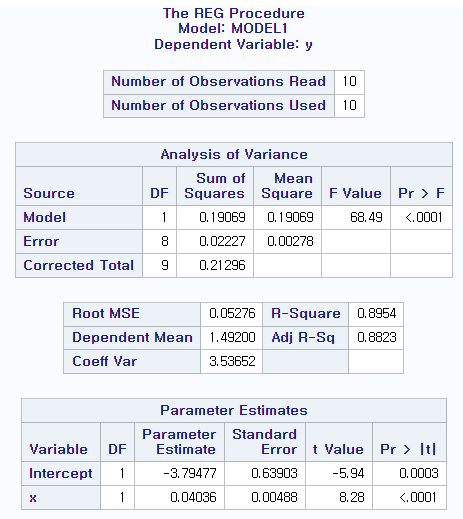
2.1 X와 Y간의 (1)산점도 그리고 (2)최소제곱법에 의한 회귀직선 적합시키고 (3)이 적합된 선을 산점도 위에 그리시오.
(1) 산점도 그리기
title 'Scatter Plot'; data max1; input y x; lines; 1.54 132.0 1.74 135.5 1.32 127.7 1.50 131.1 1.46 130.0 1.35 127.6 1.53 129.6 1.71 138.1 1.27 126.6 1.50 131.8 run; proc sort data=max1; by x; run; proc gplot data=max1; plot y*x / haxis=125 to 140 by 1 vaxis=1.2 to 1.8 by 0.1; symbol h=0.6 v=dot; run;
(2) 단순회귀모형 적합
title 'LINE FITTING'; proc reg data=max1; model y=x; run;
(3) 산점도 위에 적합선 그리기
title 'Scatter Plot and Fitted Line'; proc gplot data=max1; plot y*x / haxis=125 to 140 by 1 vaxis=1.2 to 1.8 by 0.1; symbol h=0.6 v=dot i=rl; /*여기가 겹쳐서 그리기의 핵심*/ run;
2.3 가설 H0:B1=0, H1:B1!=0의 검정을 하고 B1의 95% 신뢰구간을 구하시오
title 'T-VALUE AND CONFIDENCE INTERVAL'; proc reg data=max1; model y=x; run; data tvalue; alpha=0.05; df=8; t=tinv(1-alpha/2, df); #tinv함수가 t(p-value, df)구해줌. llimit=0.0407-t*0.00465 ulimit=0.0407+t*0.00465 run; proc print data=tvalue(keep=t llimit ulimit); run;
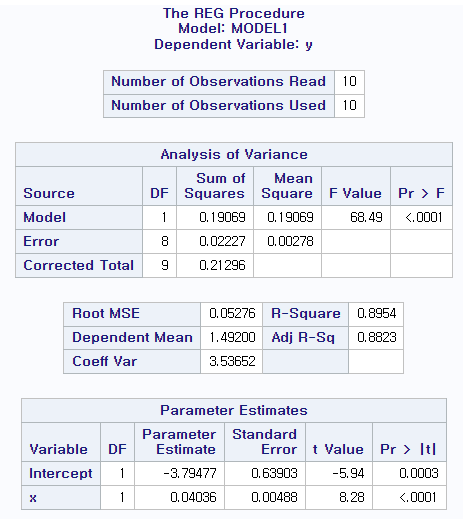
2.5 가설 H0:B1 = 0 VS H1:B1 != 0의 검정을 최대모형과 축소모형을 이용한 F검정으로 진행하시오
data max1; input y x; cards; 1.54 132.0 1.74 135.5 1.32 127.7 1.50 131.1 1.46 130.0 1.35 127.6 1.53 129.6 1.71 138.1 1.27 126.6 1.50 131.8 run; prog reg data=max1; model y=x; model y=; run;
https://pages.stat.wisc.edu/~yandell/software/sas/linmod.html

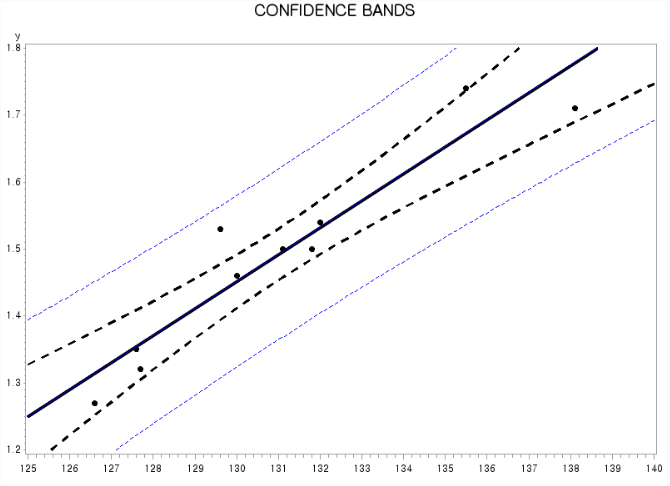
2.7 단순선형회귀모형이 성립한다고 가정하고 (1) 키가 135cm일 때의 평균 반응과 하나의 새로운 y의 예측값을 각각 구하고 (2) 두 경우의 95% 신뢰구간을 각각 구하고 (c) 이 두 경우의 신뢰대(confidence band)를 겹처서 그리시오.
(1) 키가 135cm일 때의 평균반응(점추정값)
data max1; input y x; cards; 1.54 132.0 1.74 135.5 1.32 127.7 1.50 131.1 1.46 130.0 1.35 127.6 1.53 129.6 1.71 138.1 1.27 126.6 1.50 131.8 . 135 run; proc reg data=max1; model y=x / p; id x; run;(2) 두 경우 각각의 95% 신뢰구간
title 'CONFIDENCE INTERVALS'; proc reg data=max1; model y=x / clm cli alpha=0.05; /*cl(mean), cl(i)-개별치*/ id x; run;(3) 두 경우의 신뢰대(confidence band) 겹쳐서 그리기
proc gplot data=max1; plot y*x=1 y*x=2 / haxis=125 to 140 by 1 vaxis=1.2 to 1.8 by 0.1 overlay; run;V(Mu)의 값이 X-XBAR에서 가장 작아지는 것을 생각,
각각 어떤 것이 '신뢰대'일지 '예측대'일지 판단해보기
2.9 분산분석표(ANOVA)를 작성하고 결정계수 R^2를 구하시오.
proc reg data=max1; model y=x; run;기본적인 회귀 코드만 작성하면 SST, SSE, SSR각각을 확인할 수 있으므로,
R^2 = SSR/SSTO임을 기억
r(상관계수) vs R^2(결정계수) 비교
Q 결정계수와 상관계수의 차이에 대해서 설명해 주세요.
상관계수(r)
- 두 변수의 상관성을 나타내는 척도임.
- 항상 -1과 1 사이에 있음 ( -1 ≤ r ≤ +1)
- 상관 계수 값이 -1 또는 1일 경우 이는 두 변수가 완전한 직선 관계임을 뜻함.
- 점들이 직선에 얼마나 모여 있는가를 나타냄.
- 이상점이 있을 경우, 이에 영향을 받음
- │r│ ≥ 0.65 일때 의미가 있음
결정계수(Coefficient of Determination,R2)
- 총변동중에서 회귀선에 의해 설명이 되는 변동이 차지하는 비율
- R2(R-Sq)의 범위는 0≤ R2 ≤ 1
- X와 Y간의 상관관계가 클수록 R2(R-Sq)의 값은 1에 가까와짐
- R2(R-Sq)의 값이 0에 가까워 질수록 회귀선은 쓸모가 없고, R2(R-Sq)의 값이
클수록 (R2≥0.65) 쓸모있는 회귀식이 된다
인자가 하나일때는 상관계수의 제곱값과 결정계수값이 같습니다.
수정결정계수
- 결정계수는 상향편의 된 추정치 이므로 표본 결정계수의 값은 항상 모집단의
결정계수보다 클 수 밖에 없음. 따라서, 보다 정확한 추정치를 얻기 위해서는
수정결정계수를 사용해야 함.- 수정결정계수의 값은 결정계수보다는 작고 때에 따라서는 음의 값도 나타날 수 있음
- 표본의 크기가 200개 이상일 때는 두 결정계수의 차이가 미미함.
- 표본이 200개 미만일 때는 반드시 수정결정계수를 보고서에 포함해야 함
(독립변수가 2개 이상이면 수정결정계수를 본다)
2.11 표본상관계수 r을 구하고 가설 H0 : 상관계수=0, H1 : 상관계수 !=0 검정하시오.
- 그냥 proc reg data=max1; 과정으로 R-square(결정계수) 값 확인하고 제곱근 씌우기
- proc corr 사용
proc corr data=max1 nosimple; var y x; run;
2.13 절편이 영인 단순회귀모형으로 가정할 때 기본 분산분석을 보이고 x값이 135cm일 때의 평균 반응과 점추정과 구간추정을 하시오.
noint(절편 지나지 않게), p가 없어도 돌아가는데 왜 있는건가?
proc reg data=max1; model y=x / noint p clm cli; id x; run;
2.15 꾸불꾸불한 자료를 선형화 (Transformation using ln)
data sales; input y x; lny=log(y); cards; 2.5 1.0 2.6 1.6 2.7 2.5 5.0 3.0 5.3 4.0 9.1 4.6 14.8 5.0 17.5 5.7 23.0 6.0 28.0 7.0 run; proc reg data=sales; model y=x; model lny=x; run;실제로 결정계수(R^2)의 유의미한 증가
