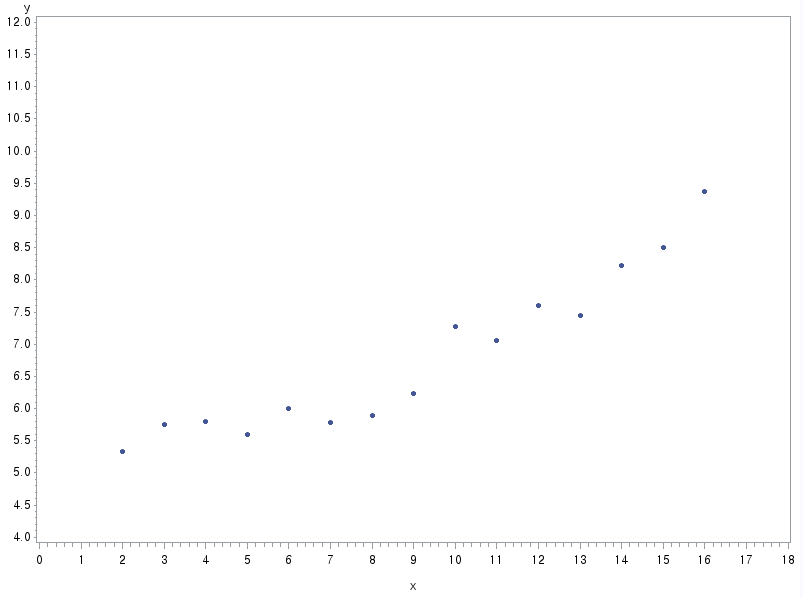
2.1 (a) 산점도 그리시오.
data EEG; input y x; cards; 5.33 2 5.75 3 5.80 4 5.60 5 6.00 6 5.78 7 5.90 8 6.23 9 7.28 10 7.06 11 7.60 12 7.45 13 8.23 14 8.50 15 9.38 16 run; proc gplot data=EEG; plot y*x / haxis= 0 to 18 by 1 vaxis= 4 to 12 by 0.5; symbol h=0.6, v=dot; run;
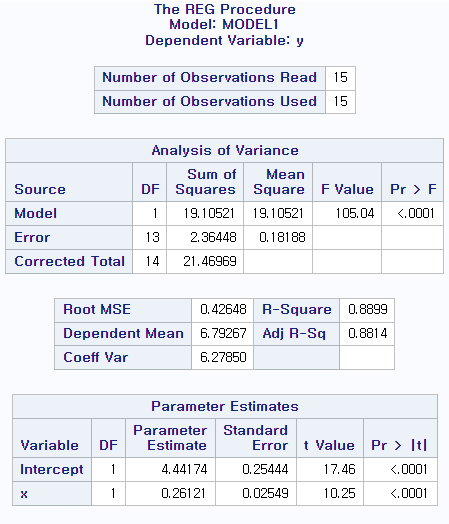
(b) 단순회귀모형 적합시키고 모형의 유의성 검정.
proc reg data=EEG; model y=x; run;
MSE/Sxx값이 0.02549임을 확인, b1값은 0.04072임을 확인, pr>F 확인을 통해 귀무가설 H1 = 0 기각한다.
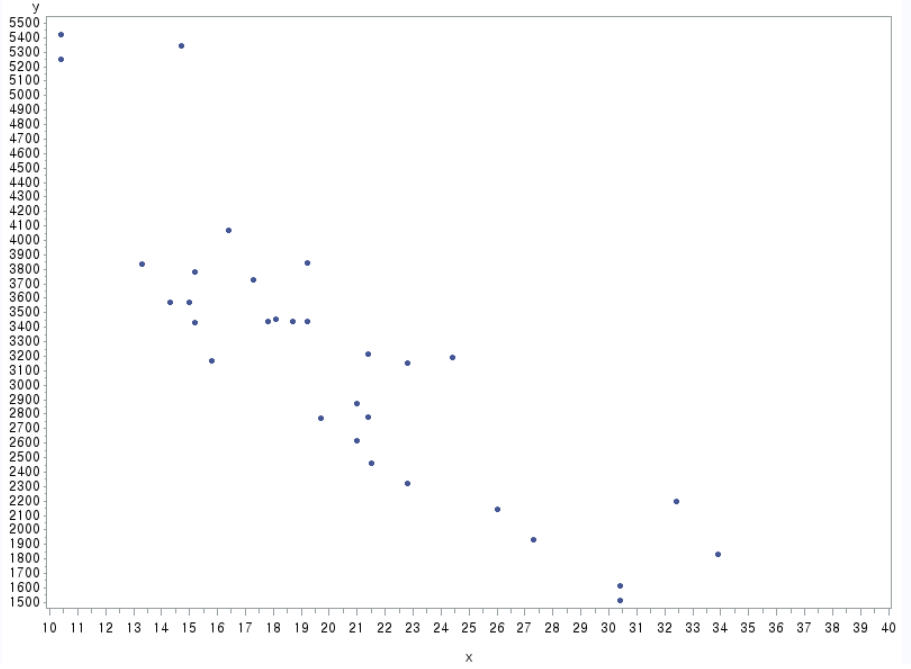
2.2 (a) 산점도를 그리고 단순회귀모형 적합시키시오.
data car; input y x; cards; 2620 21.0 2875 21.0 2320 22.8 3215 21.4 3440 18.7 3460 18.1 3570 14.3 3190 24.4 3150 22.8 3440 19.2 3440 17.8 4070 16.4 3730 17.3 3780 15.2 5250 10.4 5424 10.4 5345 14.7 2200 32.4 1615 30.4 1835 33.9 2465 21.5 3435 15.2 3840 13.3 3845 19.2 1935 27.3 2140 26.0 1513 30.4 3170 15.8 2770 19.7 3570 15.0 2780 21.4 run; proc sort data=car; by x; run; proc gplot data=car; plot y*x / haxis=10 to 40 by 1 vaxis=1500 to 5500 by 100; symbol h=0.6 v=dot; run;
proc reg data=car; model y=x; run;
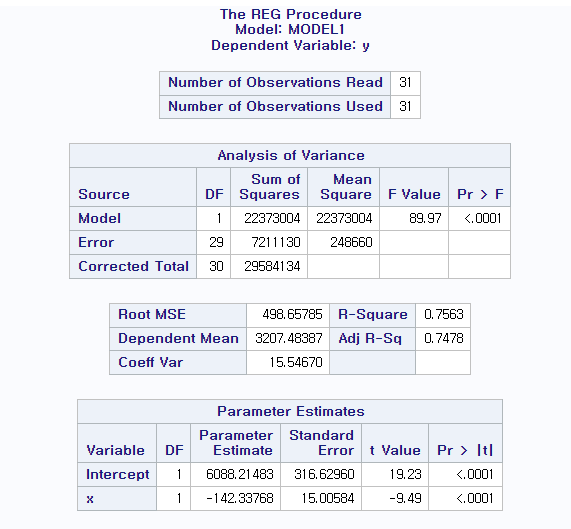
(b) 전체 변동에서 이 회귀선에 의해 설명되는 변동의 비율은 얼마인가?
R-Square값인 0.7563, 즉 75.63%임을 알 수 있다.
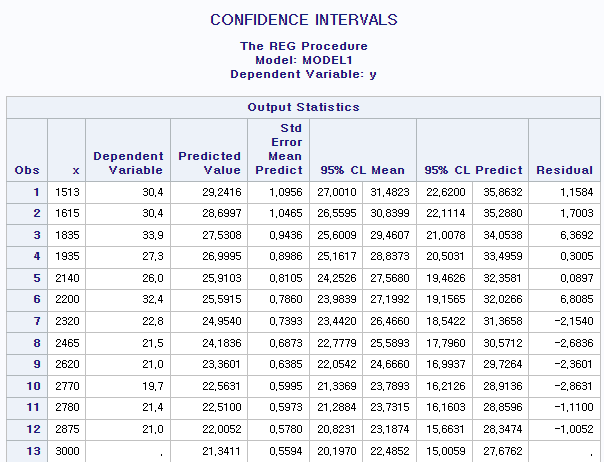
(c) 무게가 3000인 차의 평균 연비의 신뢰구간을 구하시오.
data car; input x y; cards; 2620 21.0 2875 21.0 2320 22.8 3215 21.4 3440 18.7 3460 18.1 3570 14.3 3190 24.4 3150 22.8 3440 19.2 3440 17.8 4070 16.4 3730 17.3 3780 15.2 5250 10.4 5424 10.4 5345 14.7 2200 32.4 1615 30.4 1835 33.9 2465 21.5 3435 15.2 3840 13.3 3845 19.2 1935 27.3 2140 26.0 1513 30.4 3170 15.8 2770 19.7 3570 15.0 2780 21.4 3000 . run; proc reg data=car; model y=x/p clm cli alpha=0.05; /*cl(mean), cl(i)-개별치*/ id x; run;
무게가 3000일 때 연비의 신뢰구간은 20.1970 이상 22.4852 이하임을 알 수 있다.
2.3 (a) 최종 평균점수 예측할 수 있는 추정식 구하려 한다, 일반 단순회귀모형과 원점을 지나는 단순회귀모형 중 어떤 것을 선택하겠는가?
data score; input x y; cards; 82 76 73 83 95 89 66 76 84 79 89 73 51 62 82 89 75 77 90 85 60 48 81 69 34 51 49 25 87 74 run; proc reg data=score; model y=x; model y=x / noint run;
일반 단순회귀모형의 결정계수는 0.5989, 원점 지나는 모형의 결정계수는 0.9761로 원점 지나는 모형 선택.
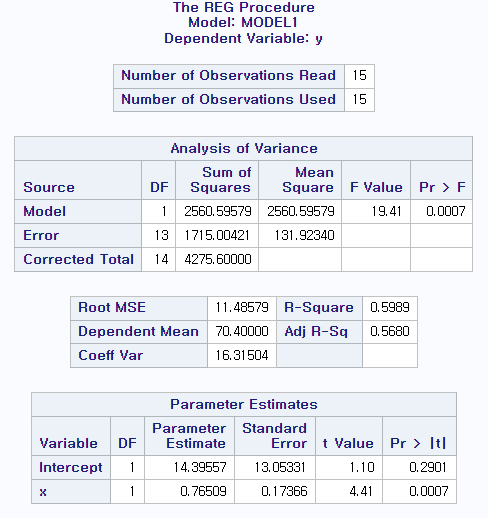
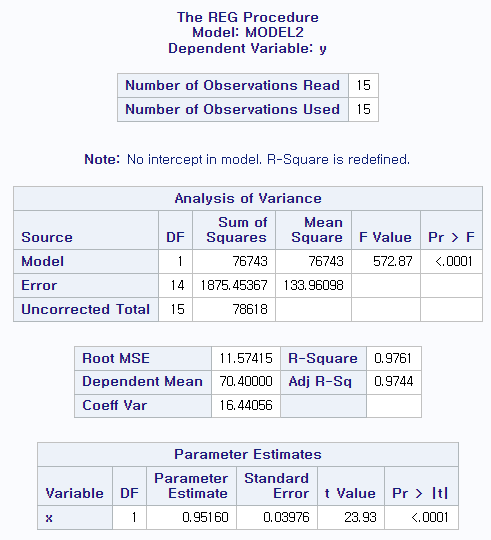
(b) 두 가지 모형을 모두 적합시키고 결정계수 비교하시오. 원점을 지나는 결정계수가 일반 모형의 결정계수보다 훨씬 크게 나오는 이유를 설명하시오.
원점을 지나는 모형은 상수항이 없으며,
이로 인해 더 많은 자유도를 가지기 때문에 결정계수가 더 크게 나올 수 있다.
2.4 (a) TEEN을 설명변수로 하여 MORT를 추정하는 회귀를 수행하시오. 이 결과는 앞의 일반적인 가정을 확증하는가?
data teen; input x y; cards; 17.4 13.3 19.0 10.3 13.8 9.4 10.9 8.9 10.2 8.6 8.8 9.1 13.2 11.5 13.8 11.0 17.0 12.5 9.2 8.5 10.8 11.3 12.5 12.1 14.0 11.3 11.5 8.9 17.4 9.8 16.8 11.9 8.3 8.5 11.7 11.7 11.6 8.8 12.3 11.4 7.3 9.2 13.4 10.7 20.5 12.4 10.1 9.6 8.9 10.1 15.9 11.5 8.0 8.4 7.7 9.1 9.4 9.8 15.3 9.5 11.9 9.1 9.7 10.7 13.3 10.6 15.6 10.4 10.9 9.4 11.3 10.2 10.3 9.4 16.6 13.2 9.7 13.3 17.0 11.0 15.2 9.5 9.3 8.6 12.0 11.1 9.2 10.0 10.4 9.8 9.9 9.2 17.1 10.2 10.7 10.8 run; proc reg data=teen; model y=x; run;
회귀 결과 Pr>F가 <.0001임을 통해 TEEN과 MORT의 관계가 있다는 가정을 확증한다.
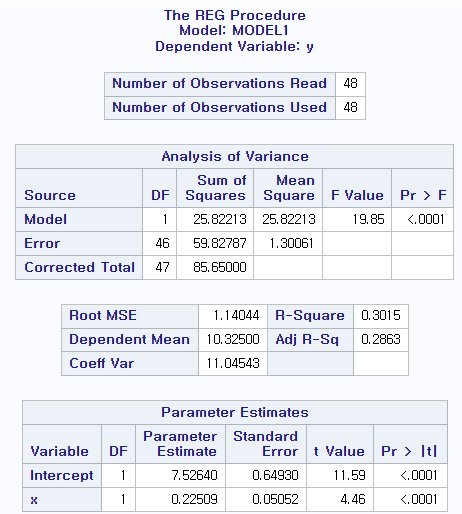
(b) 이 모형은 유의수준 0.05에서 유의한가?
앞의 Pr>F가 <.0001인 것과 x의 게수의 t-value또한 4.46으로 Pr>|t| 도 <.0001임을 확인하여 유의하다.
(c) 모수 B1에 대한 95% 신뢰구간을 구하고 또한 해석하시오.
proc reg data=teen; model y=x; run; data tvalue; alpha=0.05; df=46; t=tinv(1-alpha/2,df); llimit = 0.22509 - t*0.05052; ulimit = 0.22509 + t*0.05052; run; proc print data=tvalue(keep=t llimit ulimit); run;
주어진 결과는 t값이 2.01290이며, 이 값의 신뢰구간이 [0.12340, 0.32678]임을 알려준다. 또한 t값이 양수임을 통해 십대 임산부들의 출산율이 유아사망률에 양의 상관관계 가지는 것을 확인할 수 있다.
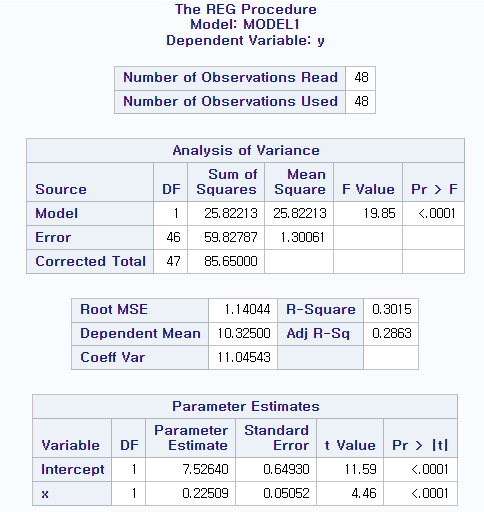
2.5 (a) 에너지와 수송의 상관계수를 구하고 상관 관계의 유무를 검정하시오.
data energy; input x y; cards; 22.4 29.8 22.5 30.1 22.6 30.8 22.5 31.4 22.9 31.9 23.3 32.3 23.8 33.3 24.2 34.3 24.8 35.7 25.5 37.5 26.5 39.5 27.2 39.9 29.4 41.2 38.1 45.8 42.1 50.1 45.1 55.1 49.4 59.0 52.5 61.7 65.7 70.5 86.0 83.1 97.7 93.2 99.2 97.0 99.9 99.3 100.9 103.7 101.6 106.4 88.2 102.3 88.6 105.4 89.3 108.7 94.3 114.1 102.1 120.5 102.5 123.8 103.0 126.5 104.2 130.4 104.6 134.3 run; proc corr data=energy; var x y; run;
에너지와 수송의 상관계수는 0.97766으로 강한양의 상관계수를 가진다.
(b) 에너지를 설명변수로 하고 수송을 반응변수로 하여 단순회귀모형을 적합시키고 기울기가 영인지 아닌지를 검정하시오.
proc reg data=energy; model y=x; model y=; run;
model y=x에서 Pr>F가 <.0001로 유의미하므로 기울기가 영이 아니라고 결론 내릴 수 있다.
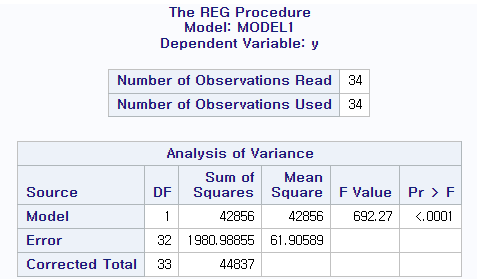
(C) 문제 (a)와 (b)의 관계를 확인하시오.
(a)에서 상관 계수가 0이 아니고 (b)에서 기울기가 0이 아니라면, 에너지와 수송 간에는 선형적인 관계가 있으며, 에너지가 수송을 설명하는 데 유의미한 영향을 미친다.
따라서 (c)를 해석하면, 에너지와 수송 사이에는 선형적인 관계가 있으며, 에너지가 수송을 설명하는 데 유의미한 영향을 미칩니다.
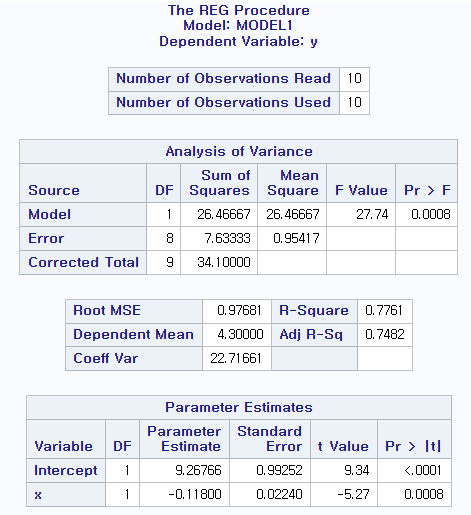
2.6 (a) 제시한 공약의 수와 이행한 공약의 수 사이의 상관관계를 구하고, 상관관계의 유무를 검정하고 해석하시오.
data energy; input x y; cards; 21 7 40 5 31 6 62 1 28 5 50 3 55 2 43 6 61 3 30 5 run; proc corr data=energy; var x y; run;
공약 수와 이행한 공약의 수는 -0.88099의 음의 상관관계를 가진다, 공약 수가 증가할 수록 이행한 공약 수는 오히려 감소하는 경향이 있음을 알 수 있다.
(b) 제시한 공약의 수를 바탕으로 하여 이행할 공약의 수를 예측하는 단순 회귀식을 구하고, 모수 B1에 대한 95% 신뢰구간을 구하고 해석하시오. (a)의 결과와 비교하시오.
proc reg data=energy; model y=x; run;
proc reg data=energy; model y=x; run; data tvalue; alpha=0.05; df=7; t=tinv(1-alpha/2,df); llimit = -0.118-t*0.0224; ulimit = -0.118+t*0.0224; run; proc print data=tvalue(keep=t llimit ulimit); run;
신뢰구간은 [-0.17097, -0.065032]임을 확인할 수 있고 t값은 2.36462로 (a)에서 b1이라는 계수의 Pr>|t|가 0.0008로 유의미 하지 않음을 (a)와 (b)모두 공통적으로 도출해낼 수 있다.
(c) 어떤 한 후보가 45개의 공약을 걸었을 때 이행할 공약의 수의 점추정을 하고 또한 95% 구간추정을 하시오.
data energy; input x y; cards; 21 7 40 5 31 6 62 1 28 5 50 3 55 2 43 6 61 3 30 5 45 . run; proc reg data=energy; model y=x / p; id x; run;
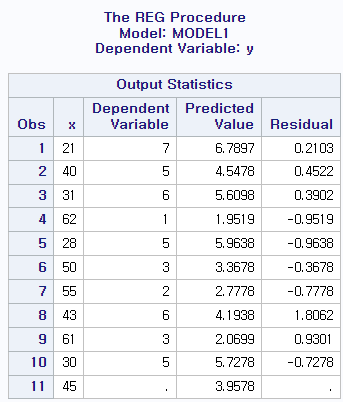
proc reg data=energy; model y=x / p clm cli alpha=0.05; id x; run;
점추정 결과 3.9578의 값을 예측했고 그 구간은 [1.5906, 6.3250]임을 확인할 수 있다.
2.7 (a) 산점도를 그리고 단순회귀모형을 적합시키시오.
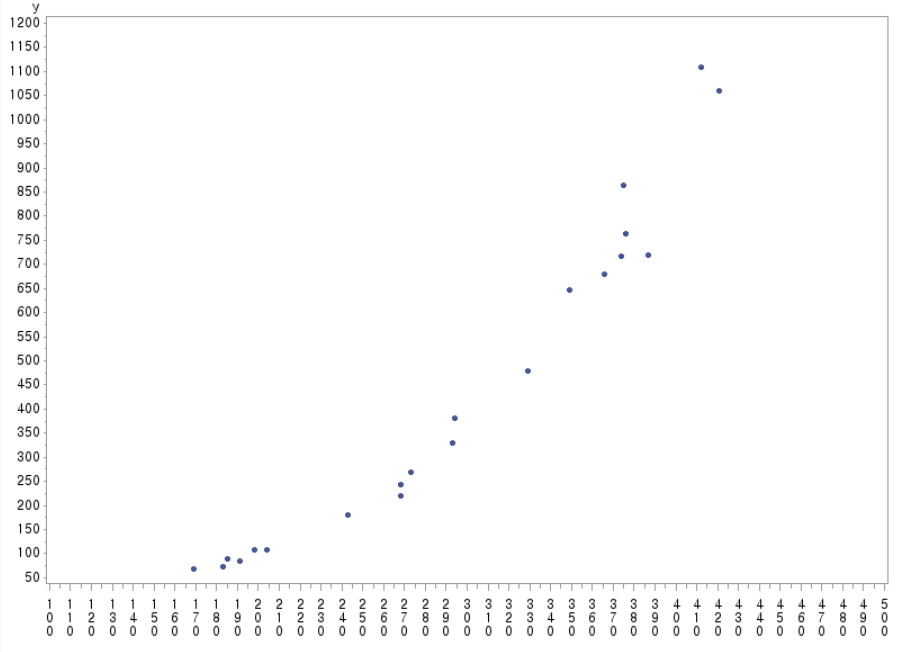
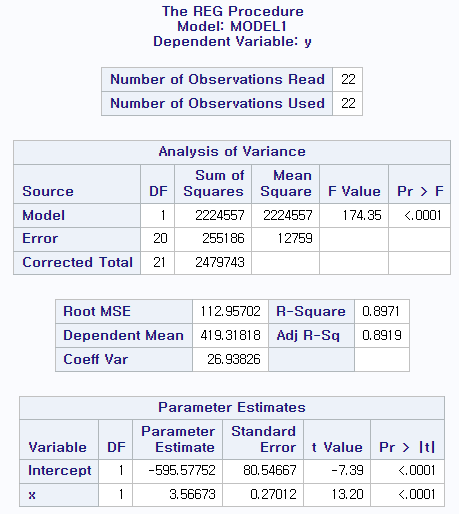
data fish; input x y; cards; 387 720 366 680 421 1060 329 480 293 330 273 270 268 220 294 380 198 108 185 89 169 68 102 28 376 764 375 864 374 718 349 648 412 1110 268 244 243 180 191 84 204 108 183 72 run; proc sort data=fish; by x; run; proc gplot data=fish; plot y*x /haxis=100 to 500 by 10 vaxis=50 to 1200 by 50; symbol h=0.6 v=dot; run; proc reg data=fish; model y=x; run;
(b) y를 lny로 변환하여 산점도를 그리고 단순회귀모형을 적합시키시오.
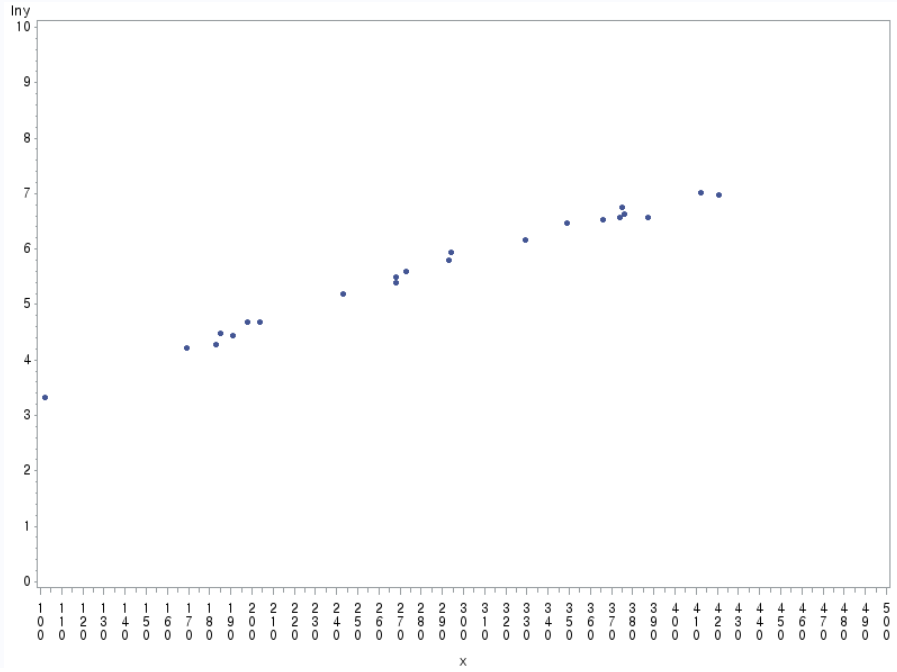
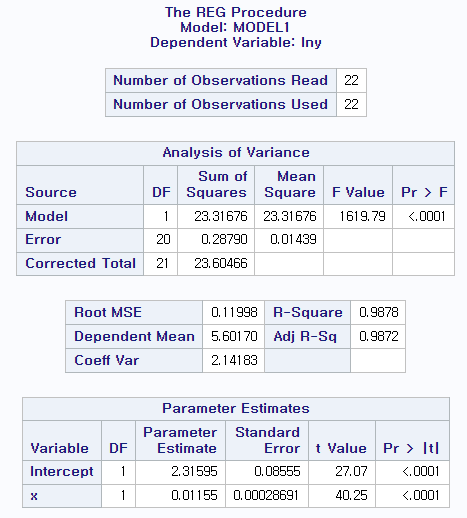
data fish; input x y; lny=log(y); cards; 387 720 366 680 421 1060 329 480 293 330 273 270 268 220 294 380 198 108 185 89 169 68 102 28 376 764 375 864 374 718 349 648 412 1110 268 244 243 180 191 84 204 108 183 72 run; proc sort data=fish; by x; run; proc gplot data=fish; plot lny*x /haxis=100 to 500 by 10 vaxis=0 to 10 by 1; symbol h=0.6 v=dot; run; proc reg data=fish; model lny=x; run;
(c) 두 모형을 비교하시오. 어느 모형을 선택하겠는가?
(a)에서의 모형은 직선형태가 아닌 굴곡을 진 모형이었다.
(b)의 lny 변환 과정을 통해 산점도가 직선에 가깝게 변환되었으므로 (b)가 적절.
실제로 결정계수 또한 굉장히 증가했다.
