1️⃣ 데이터 준비 & 전처리
from keras.datasets import mnist
(tr_x,tr_y),(tt_x,tt_y)=mnist.load_data()
👉 MNIST 데이터 로드
tr_x, tr_y: 훈련 데이터(이미지, 레이블)
tt_x, tt_y: 테스트 데이터(이미지, 레이블)
s_tr_x=tr_x.reshape(-1,28,28,1)/255.
s_tt_x=tt_x.reshape(-1,28,28,1)/255.👉 이미지 정규화 및 형상 변경
원래 MNIST 데이터는 (60000, 28, 28) 형식이지만 CNN을 쓰려면 (배치, 높이, 너비, 채널) 형태가 필요!
reshape(-1,28,28,1) → 마지막 1은 흑백 이미지(채널 1개)라는 의미.
/255. → 픽셀값(0255)을 01로 정규화해서 학습 효율을 높임.
from keras.utils import to_categorical
s_tr_y=to_categorical(tr_y)
s_tt_y=to_categorical(tt_y)👉 원-핫 인코딩 (One-hot Encoding)
MNIST의 숫자 라벨(0~9)을 원-핫 벡터로 변환해줌.
예) 3 → [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
2️⃣ CNN 모델 클래스 정의
class CNN:
def __init__(self,n_k=10,batch_size=32,units=10,lr=0.1):👉 CNN 모델을 만들기 위한 초기 설정
n_k=10 → 합성곱 커널(필터) 개수
batch_size=32 → 한 번에 학습할 데이터 개수
units=10 → 은닉층 뉴런 개수
lr=0.1 → 학습률
(1) 순전파(forward propagation)
👉 CNN의 기본 구조를 따른 순전파 과정
def forpass(self,x):
c_out=conv2d(x,self.c_w,strides=1,padding='SAME') # 합성곱 연산
r_out=relu(c_out) # 활성화 함수 (ReLU)
p_out=max_pool2d(r_out,ksize=2,strides=2,padding='VALID') # 풀링
f_out=tf.reshape(p_out,[x.shape[0],-1]) # 벡터화
z1=tf.matmul(f_out,self.w1)+self.b1 # 은닉층 연산
a1=relu(z1) # 은닉층 활성화
z2=tf.matmul(a1,self.w2)+self.b2 # 출력층 연산
return z2합성곱(Convolution) → 이미지 특징 추출
ReLU 활성화 함수 → 비선형성 추가
맥스 풀링(Max Pooling) → 특징 유지하면서 크기 축소
벡터화 (Flatten) → CNN 출력을 완전연결층으로 변환
은닉층(Dense Layer) → 뉴런을 거쳐 활성화
출력층(Dense Layer) → 최종 출력 계산
(2) 가중치 초기화
def init_w(self,input_shape,n_class):
g=tf.initializers.glorot_uniform(0) # Glorot 초기화
self.c_w=tf.Variable(g((3,3,1,self.n_k))) # 합성곱 가중치
self.c_b=tf.Variable(np.zeros(self.n_k),dtype=float) # 합성곱 절편
n_f=input_shape[1]//2*input_shape[2]//2*self.n_k # 벡터화 후 뉴런 수
self.w1=tf.Variable(g((n_f,self.units))) # 은닉층 가중치
self.b1=tf.Variable(np.zeros(self.units),dtype=float) # 은닉층 절편
self.w2=tf.Variable(g((self.units,n_class))) # 출력층 가중치
self.b2=tf.Variable(np.zeros(n_class),dtype=float) # 출력층 절편👉 모델의 가중치(Weight)와 절편(Bias) 초기화
Glorot 초기화 → 적절한 분포로 가중치를 생성하여 학습 안정화
합성곱, 은닉층, 출력층의 가중치와 절편을 설정
(3) 모델 학습 (Training)
def fit(self,x,y,epoch=100,val_x=None,val_y=None):
self.init_w(x.shape,y.shape[1]) # 가중치 초기화
self.optimizer = tf.optimizers.SGD(learning_rate=self.lr) # SGD 옵티마이저
for i in range(epoch):
batch_loss=[]
for x_b , y_b in self.gen_barch(x,y):
self.training(x_b,y_b) # 배치별 학습
batch_loss.append(self.get_loss(x_b,y_b)) # 손실값 저장
tr_loss=np.mean(batch_loss) # 평균 훈련 손실
val_loss=self.get_loss(val_x,val_y) # 검증 손실
print(f"에포크:{i+1}:tr_loss:{tr_loss},val_loss:{val_loss}")
self.losses.append(tr_loss) # 훈련 손실 저장
self.val_losses.append(val_loss) # 검증 손실 저장👉 모델 학습 과정
init_w()를 호출해 가중치 초기화
SGD 옵티마이저 설정
배치 단위로 데이터를 학습시키며 손실 계산
손실 값(losses, val_losses)을 저장하고 출력
(4) 배치 생성
def gen_barch(self,x,y):
bins=len(x)//self.batch_size
idx=np.random.permutation(np.arange(len(x))) # 데이터 셔플링
x=x[idx]
y=y[idx]
for i in range(bins):
st=self.batch_size*i
end=self.batch_size*(i+1)
yield x[st:end],y[st:end]👉 배치 데이터 생성
랜덤하게 섞어서 미니배치를 만든 후, 모델에 입력
(5) 경사 하강법 적용
def training(self,x,y):
with tf.GradientTape() as taps:
z=self.forpass(x) # 순전파
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y,z)) # 손실 계산
w_l=[self.c_w,self.c_b,self.w1,self.b1,self.w2,self.b2]
g=taps.gradient(loss,w_l) # 가중치에 대한 그래디언트 계산
self.optimizer.apply_gradients(zip(g,w_l)) # 옵티마이저 적용👉 경사 하강법 적용
GradientTape()를 이용해 미분(기울기) 계산
가중치를 업데이트하여 학습 진행
3️⃣ 모델 실행
m=CNN(n_k=10,batch_size=128,units=100,lr=0.01)
m.fit(s_tr_x,s_tr_y,10,s_tt_x,s_tt_y) # 학습 실행👉 CNN 모델 생성 후 학습 진행 (에포크 10번)
4️⃣ 성능 평가 및 예측
m.score(s_tr_x,s_tr_y) # 훈련 데이터 정확도
m.score(s_tt_x,s_tt_y) # 테스트 데이터 정확도👉 정확도를 계산하여 모델의 성능 평가
plt.plot(m.losses[-3:])
plt.plot(m.val_losses[-3:])👉 손실 그래프를 그려 학습이 잘 진행됐는지 확인
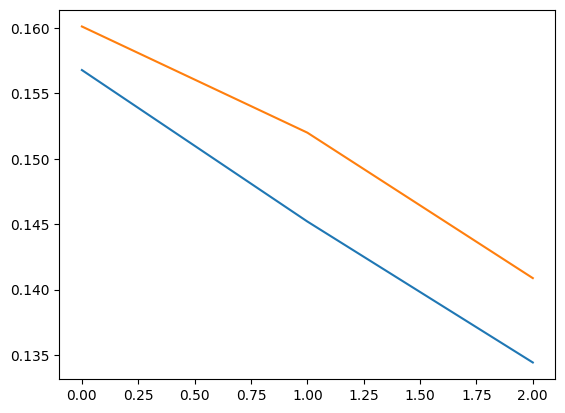
🔎 그래프가 나타내는 의미
- 파란색(훈련 손실) 선이 주황색(검증 손실) 선보다 아래에 있음
- 모델이 훈련 데이터에 대해 더 잘 학습하고 있음
- 이는 일반적인 결과로, 훈련 데이터는 모델이 직접 학습한 데이터이기 때문
- 두 손실 값이 점점 줄어들고 있음
- 모델이 점진적으로 학습을 잘하고 있고, 과적합(overfitting)이 발생하지 않은 상태일 가능성이 높음
- 검증 손실이 급격히 증가하지 않으므로, 모델이 검증 데이터에 대해서도 좋은 성능을 보이는 것으로 보임
📌 아래부터는 은닉층 개수를 다르게 설정한 모델들을 비교하며 성능 차이 분석해보기 (DNN)
1️⃣ 데이터 로드 및 전처리
from keras import Sequential, Input
from keras.layers import Dense, Dropout, Flatten, BatchNormalization👉 필요한 라이브러리 불러오기
Sequential : 레이어를 순차적으로 쌓는 모델
Input : 입력 크기 정의
Dense : 완전연결(Dense) 레이어
Flatten : 2D 데이터를 1D 벡터로 변환 (신경망에 넣기 위해 필요)
(tr_x, tr_y), (tt_x, tt_y) = mnist.load_data()
s_tr_x = tr_x.reshape(-1, 28, 28, 1) / 255.
s_tt_x = tt_x.reshape(-1, 28, 28, 1) / 255.
s_tr_y = to_categorical(tr_y)
s_tt_y = to_categorical(tt_y)👉 MNIST 데이터 전처리
reshape(-1, 28, 28, 1): CNN에서는 채널을 추가해야 하지만, 여기선 DNN이므로 사실상 필요 없음.
Flatten() 층이 있기 때문에 (28,28,1) 대신 (28,28)로 입력 가능.
to_categorical() : 숫자(0~9)를 원-핫 인코딩 변환.
2️⃣ 첫 번째 모델 (은닉층 1개)
m = Sequential()
m.add(Input(shape=(28, 28))) # 입력층
m.add(Flatten()) # 2D 데이터를 1D로 변환
m.add(Dense(100, activation='relu')) # 은닉층 (100개의 뉴런, 활성화 함수 ReLU)
m.add(Dense(10, activation='softmax')) # 출력층 (10개의 클래스)
m.compile(loss='categorical_crossentropy', optimizer='sgd')
hy = m.fit(s_tr_x, s_tr_y, epochs=10, batch_size=128, validation_data=(s_tt_x, s_tt_y))👉 DNN 모델 1
은닉층 1개 (100개 뉴런)
ReLU 활성화 함수 사용
softmax를 사용해 다중 분류 수행
SGD(확률적 경사 하강법) 최적화
categorical_crossentropy 손실 함수 적용
3️⃣ 두 번째 모델 (은닉층 2개)
m1 = Sequential()
m1.add(Input(shape=(28, 28)))
m1.add(Flatten())
m1.add(Dense(100, activation='relu'))
m1.add(Dense(100, activation='relu'))
m1.add(Dense(10, activation='softmax'))
m1.compile(loss='categorical_crossentropy', optimizer='sgd')👉 DNN 모델 2
은닉층 2개 (100개 뉴런씩)
더 깊은 네트워크로 학습이 더 잘될 가능성이 있음.
4️⃣ 세 번째 모델 (은닉층 3개)
m2 = Sequential()
m2.add(Input(shape=(28, 28)))
m2.add(Flatten())
m2.add(Dense(100, activation='relu'))
m2.add(Dense(100, activation='relu'))
m2.add(Dense(100, activation='relu'))
m2.add(Dense(10, activation='softmax'))
m2.compile(loss='categorical_crossentropy', optimizer='sgd')👉 DNN 모델 3
은닉층 3개 (100개 뉴런씩)
네트워크가 더 깊어지므로 더 복잡한 패턴을 학습할 가능성이 높음.
5️⃣ 네 번째 모델 (은닉층 4개)
m3 = Sequential()
m3.add(Input(shape=(28, 28)))
m3.add(Flatten())
m3.add(Dense(100, activation='relu'))
m3.add(Dense(100, activation='relu'))
m3.add(Dense(100, activation='relu'))
m3.add(Dense(100, activation='relu'))
m3.add(Dense(10, activation='softmax'))
m3.compile(loss='categorical_crossentropy', optimizer='sgd')👉 DNN 모델 4
은닉층 4개 (100개 뉴런씩)
모델이 깊어질수록 학습이 잘 될 수도 있지만, 과적합(overfitting)의 위험도 있음.
6️⃣ 모델 학습
hy1 = m1.fit(s_tr_x, s_tr_y, epochs=10, batch_size=128, validation_data=(s_tt_x, s_tt_y), verbose=2)
hy2 = m2.fit(s_tr_x, s_tr_y, epochs=10, batch_size=128, validation_data=(s_tt_x, s_tt_y), verbose=2)
hy3 = m3.fit(s_tr_x, s_tr_y, epochs=10, batch_size=128, validation_data=(s_tt_x, s_tt_y), verbose=2)👉 각 모델 학습 실행
epochs=10 → 10번 반복 학습
batch_size=128 → 한 번에 128개 샘플을 학습
validation_data=(s_tt_x, s_tt_y) → 테스트 데이터로 검증
verbose=2 → 학습 로그를 깔끔하게 출력
7️⃣ 손실 그래프 그리기
plt.plot(hy1.history['loss'])
plt.plot(hy1.history['val_loss'])👉 훈련 손실과 검증 손실 비교
훈련 손실이 계속 감소하면서 과적합 여부 확인
검증 손실이 증가하면 모델이 학습 데이터를 과하게 외우고 있는 것 (즉, 일반화 성능이 떨어짐)
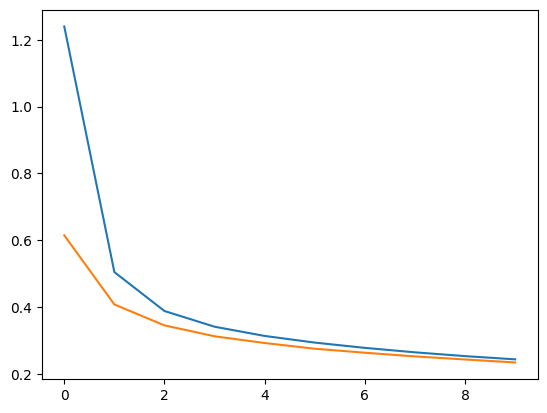
🔎 그래프가 나타내는 의미
파란색 선: 훈련 손실 값 (hy1.history['loss'])
주황색 선: 검증 손실 값 (hy1.history['val_loss'])
- 초기 훈련 손실이 매우 높음
- 모델이 학습을 시작하면서 초기에는 데이터에 대해 거의 알지 못하므로 손실 값이 큼.
- 빠른 손실 감소 (1~3 에포크 사이)
- 모델이 학습하면서 손실 값이 급격히 감소함.
- 학습률(learning rate)이 적절하고, 모델이 데이터를 잘 학습하고 있다는 것을 보여줌.
- 훈련 손실과 검증 손실의 유사한 경향
- 두 손실 값이 모두 감소하며, 그래프 모양이 비슷하게 유지됨.
- 이는 과적합(overfitting)이 발생하지 않고, 모델이 훈련 데이터와 검증 데이터에 대해 균형 잡힌 학습을 하고 있다는 것을 의미.
plt.plot(hy2.history['loss'])
plt.plot(hy2.history['val_loss'])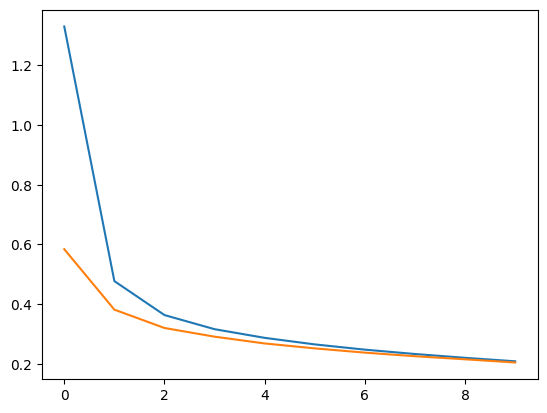
🔎 그래프가 나타내는 의미
- 초기 손실 값의 차이
- 모델이 학습을 시작하면서 초기에는 데이터에 대해 거의 알지 못하므로 손실 값이 큼
- 이는 모델이 훈련 데이터를 아직 학습하지 못한 초기 상태를 반영
- 빠른 손실 감소 (1~3 에포크 사이)
- 검증 손실도 함께 감소하며, 훈련 손실과 유사한 추이를 보임
- 이는 학습률이 적절하고 모델이 복잡한 패턴을 잘 학습하고 있다는 증거.
- 훈련 손실과 검증 손실의 유사한 경향
- 검증 손실도 함께 감소하며, 훈련 손실과 유사한 추이를 보임
- 이는 모델이 훈련 데이터뿐만 아니라 검증 데이터에도 잘 일반화(generalization)되고 있음을 의미.
- 훈련 손실과 검증 손실 간의 격차
- 두 손실 값 간 차이가 점점 줄어들고, 마지막에는 거의 동일하게 수렴하는 것으로 보임
- 이는 과적합(overfitting)이 발생하지 않은 상태를 나타냄
plt.plot(hy3.history['loss'])
plt.plot(hy3.history['val_loss'])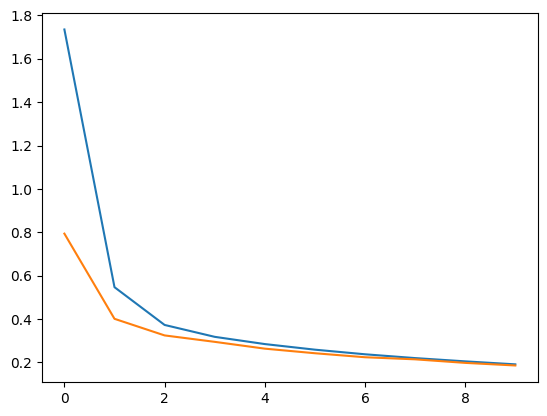
🔎 그래프가 나타내는 의미
-
초기 손실 값이 높음
- 훈련 손실과 검증 손실 모두 초기에 매우 높음
- 이는 모델이 아직 데이터를 학습하지 못한 상태를 보여줌
-
빠른 손실 감소
- 에포크 초반(1~3) 동안 훈련 손실과 검증 손실이 급격히 감소
- 이는 모델이 데이터의 패턴을 빠르게 학습하고 있다는 것을 의미
-
손실 값의 수렴
- 에포크가 진행될수록 훈련 손실과 검증 손실이 모두 완만하게 감소
- 두 선이 비슷하게 수렴하는 것은 모델이 훈련 데이터와 검증 데이터 모두에 잘 일반화(generalization)되고 있다는 것을 보여줌
-
검증 손실과 훈련 손실의 차이
- 검증 손실(주황색)이 훈련 손실(파란색)보다 낮게 유지되는 경향이 보임
- 이는 검증 데이터가 상대적으로 더 간단하거나, 훈련 데이터에 잡음(noise)이 포함되어 있을 가능성을 시사함
8️⃣ 모델 평가
m1.evaluate(s_tr_x, s_tr_y), m1.evaluate(s_tt_x, s_tt_y)
m2.evaluate(s_tr_x, s_tr_y), m2.evaluate(s_tt_x, s_tt_y)
m3.evaluate(s_tr_x, s_tr_y), m3.evaluate(s_tt_x, s_tt_y)
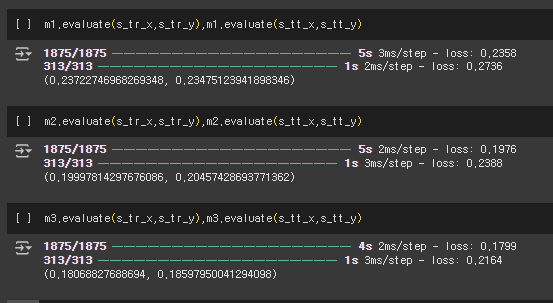
👉 각 모델의 훈련 데이터 & 테스트 데이터 성능 평가
evaluate() → 손실 값(loss)과 정확도(accuracy)를 반환
9️⃣ 예측 수행
py1 = m1.predict(s_tt_x) > 0.5
py2 = m2.predict(s_tt_x) > 0.5
py3 = m3.predict(s_tt_x) > 0.5
👉 모델이 테스트 데이터에서 예측한 결과
predict() → 모델이 클래스 확률 예측
0.5 → 0.5보다 크면 해당 클래스로 판별
📌 정리
🔹 주요 목표
은닉층 개수를 다르게 한 모델을 비교하여 MNIST 분류 성능 평가
층이 많아질수록 학습 성능이 어떻게 변하는지 실험
🔹 모델 차이점
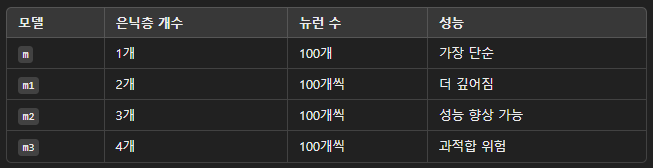
🔹 기대 결과
-
일반적으로 은닉층이 깊어질수록 성능이 향상되지만,
너무 깊어지면 과적합이 발생할 수도 있음 -
손실 그래프를 통해 훈련 손실과 검증 손실의 차이를 확인하면서 과적합 여부를 판단해야 함.
👉 딥러닝에서 층을 추가하면 무조건 성능이 좋아지는 것이 아니라, 적절한 균형이 필요하다는 점을 확인하는 테스트! 🚀
📌 신경망의 깊이에 따른 성능 비교와 배치 정규화 (Batch Normalization)의 효과를 실험하는 코드
1️⃣ 모델 성능 평가 (Classification Report)
from sklearn.metrics import classification_report
print(classification_report(s_tt_y, py1))
print(classification_report(s_tt_y, py2))
print(classification_report(s_tt_y, py3))👉 각 모델(m1, m2, m3)의 성능을 평가
classification_report()는 정확도, 정밀도(Precision), 재현율(Recall), F1-score를 출력하는 함수.
s_tt_y(실제 값)과 py1, py2, py3(예측 값)를 비교해서 성능을 확인.
2️⃣ 매우 깊은 신경망(12개의 은닉층) 실험
ck_m = Sequential()
ck_m.add(Input(shape=(28,28)))
ck_m.add(Flatten())
for _ in range(10):
ck_m.add(Dense(100, activation='sigmoid'))
ck_m.add(Dense(10, activation='softmax'))
ck_m.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['acc'])👉 은닉층 10개, 출력층 포함 총 12개 층을 가진 신경망
모든 은닉층은 sigmoid 활성화 함수 사용.
출력층은 softmax 사용 (10개의 숫자 분류)
hy = ck_m.fit(s_tr_x, s_tr_y, epochs=10, batch_size=128, validation_data=(s_tt_x, s_tt_y))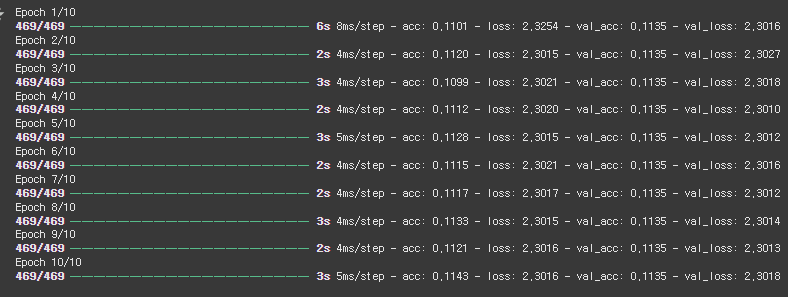
👉 10번의 에포크 동안 학습
batch_size=128 → 한 번에 128개 데이터 학습
validation_data → 검증 데이터로 성능 체크
plt.plot(hy.history['loss'])
plt.plot(hy.history['val_loss'])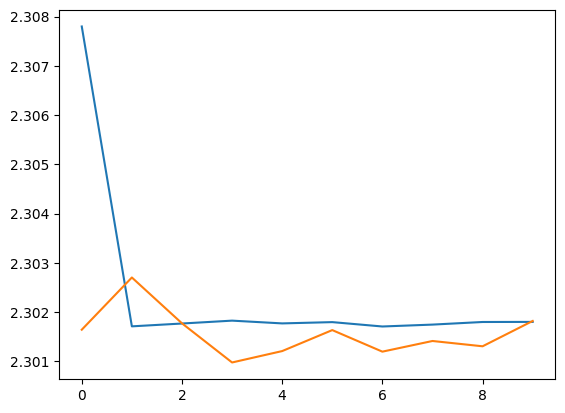
👉 손실값(훈련/검증) 그래프 그리기
과적합(overfitting) 여부 확인 가능 (검증 손실이 증가하면 과적합일 가능성이 높음).
🔎 그래프가 나타내는 의미
-
초기 손실 값
- 초반에 훈련 손실(loss)이 2.308에서 시작하여 급격히 감소.
- 검증 손실(val_loss)은 초기에는 훈련 손실보다 약간 낮은 값에서 시작함.
-
손실 값의 변동
- 훈련 손실은 빠르게 감소한 후 거의 일정한 값을 유지함.
- 검증 손실은 훈련 손실보다 약간 낮게 유지되지만, 에포크가 진행되며 약간의 진동을 보임.
-
손실 값의 수렴
- 훈련 손실과 검증 손실이 모두 2.30 근처로 수렴하며, 손실 감소가 크게 일어나지 않음.
- 이는 모델이 데이터를 충분히 학습하지 못하고 있는 상태일 가능성이 높음.
✍ 제대로 학습을 못하고 있는 이유 추측
- 활성화 함수와 초기화의 영향
- 모델에서 sigmoid 활성화 함수를 사용했는데, 이는 기울기 소실(Vanishing Gradient) 문제를 유발하여 학습이 제대로 이루어지지 않을 수 있음.
- 층이 깊은 모델에서 ReLU 또는 Leaky ReLU 같은 활성화 함수를 사용하면 성능 개선 가능.
검증 손실의 진동
- 검증 손실이 진동하는 것은 모델이 학습 중 약간 불안정하다는 신호.
- 배치 정규화(Batch Normalization)나 적절한 하이퍼파라미터 튜닝(학습률 조정)이 필요할 수 있음.
3️⃣ 배치 정규화(Batch Normalization) 추가한 모델
ck_m1 = Sequential()
ck_m1.add(Input(shape=(28,28)))
ck_m1.add(Flatten())
for _ in range(10):
ck_m1.add(Dense(100, activation='sigmoid'))
ck_m1.add(BatchNormalization()) # 배치 정규화 추가
ck_m1.add(Dense(10, activation='softmax'))
ck_m1.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['acc'])👉 배치 정규화를 적용한 신경망
- BatchNormalization()을 추가하여 각 층의 출력을 정규화.
- 배치 정규화의 효과:
1. 학습 속도 증가
2. 기울기 소실(Vanishing Gradient) 문제 완화
3. 과적합 방지
hy = ck_m1.fit(s_tr_x, s_tr_y, epochs=10, batch_size=128, validation_data=(s_tt_x, s_tt_y))👉 배치 정규화 모델 학습
plt.plot(hy.history['loss'])
plt.plot(hy.history['val_loss'])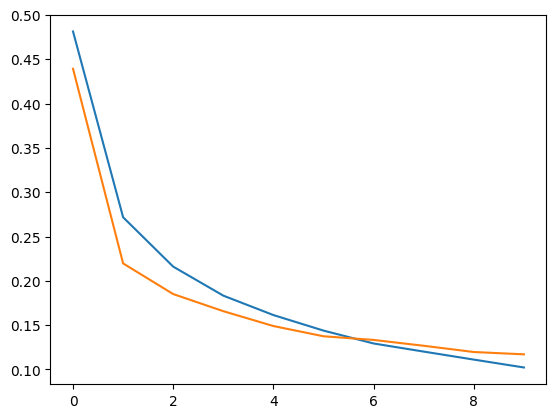
🔎 그래프가 나타내는 의미 (손실[Loss] 그래프)
-
초기 손실 값
- 훈련 손실과 검증 손실 모두 초반에 높게 시작하지만, 에포크가 진행되면서 급격히 감소.
- 이는 모델이 데이터를 빠르게 학습하고 있다는 것을 보여줌.
-
손실 감소
- 훈련 손실과 검증 손실이 함께 감소하며 점점 수렴하는 모습을 보임.
- 이는 모델이 과적합 없이 안정적으로 학습하고 있음을 나타냄.
-
검증 손실과 훈련 손실의 수렴
- 마지막 에포크 근처에서 훈련 손실과 검증 손실이 거의 비슷한 값을 유지.
- 이는 모델이 훈련 데이터와 검증 데이터에 대해 잘 일반화(generalization)되고 있음을 의미.
plt.plot(hy.history['acc'])
plt.plot(hy.history['val_acc'])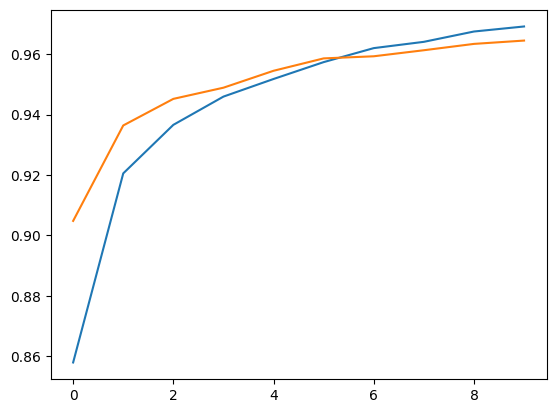
🔎 그래프가 나타내는 의미 (정확도[Accuracy] 그래프)
-
초기 정확도
- 훈련 데이터의 정확도는 초반에 낮게 시작하여 급격히 증가.
- 검증 데이터의 정확도는 훈련 데이터보다 약간 높게 시작하지만, 이후 비슷한 경향을 보임.
-
정확도 수렴
- 훈련 정확도와 검증 정확도가 모두 0.96 이상에서 수렴.
- 이는 모델이 높은 정확도로 데이터의 패턴을 학습하고, 검증 데이터에도 잘 일반화되고 있음을 보여줌.
-
과적합 없음
- 훈련 정확도와 검증 정확도 간에 큰 차이가 없으므로 과적합이 발생하지 않음.
👉 손실 & 정확도 그래프 비교
배치 정규화를 적용한 모델이 학습 속도가 더 빠르고, 검증 성능이 더 좋아질 가능성이 높음.
📌 정리
🔹 주요 핵심
- 층을 깊게 하면 성능이 좋아질까?
- sigmoid 활성화 함수 사용 시, 깊어질수록 기울기 소실(Vanishing Gradient) 문제가 발생할 수 있음.
- 즉, 깊다고 무조건 좋은 것은 아님!
- 배치 정규화를 적용하면?
- 배치 정규화는 신경망 학습을 빠르게 하고, 과적합을 방지하는 효과가 있음.
- 깊은 신경망에서도 성능이 유지될 가능성이 높음.
