1️⃣ LeNet (1998, Yann LeCun)
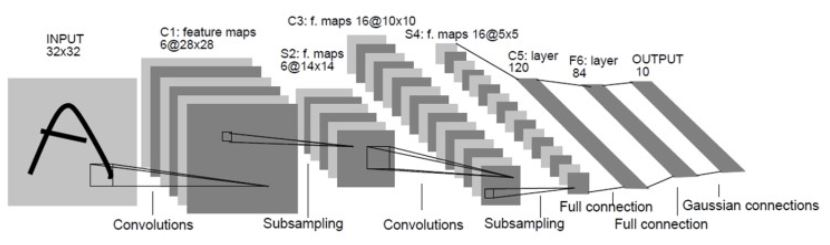
목표: 숫자 필기체(MNIST) 인식
입력 크기: 32×32 (MNIST 이미지를 32×32로 확장해서 사용)
구성: Conv → Pool → Conv → Pool → FC → FC → Output
특징
- 아주 작은 구조
- 7개 레이어(Convolution, Subsampling, Fully connected 포함)
- 최초의 CNN 모델 중 하나로, CNN의 기본 구조를 정의
🧠 핵심 개념: "Convolution(특징 추출)"과 "Pooling(요약)"을 번갈아 사용해 이미지의 의미를 점점 추출한다.
LeNet5 모델 설계
-> MNIST 숫자 이미지를 불러오고, LeNet에 맞춰 28x28 → 32x32로 패딩합니다.
1. MNIST 데이터 로딩
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 이미지 전처리: 28x28 MNIST 이미지를 32x32로 패딩 + Tensor로 변환
transform = transforms.Compose([
transforms.Pad(2), # 28x28 -> 32x32
transforms.ToTensor(), # [0,255] → [0.0,1.0]
])
# 학습용 데이터셋 다운로드
train_dataset = datasets.MNIST(
root='./data', train=True, download=True, transform=transform
)
# 테스트 데이터셋 다운로드
test_dataset = datasets.MNIST(
root='./data', train=False, download=True, transform=transform
)
# DataLoader: 배치 단위로 데이터를 처리할 수 있게 해줌
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)2. LeNet-5 모델 정의
import torch
import torch.nn as nn
import torch.nn.functional as F
class LeNet5(nn.Module):
def __init__(self, num_classes=10):
super(LeNet5, self).__init__()
# Convolutional layers
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0)
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2)
self.conv3 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5, stride=1)
# Fully connected layers
self.fc1 = nn.Linear(120, 84)
self.fc2 = nn.Linear(84, num_classes)
def forward(self, x):
x = F.tanh(self.conv1(x)) # ✅ Convolution 1 (5x5 필터, 채널 1 → 6)
x = self.pool1(x) # ✅ Pooling 1 (2x2 평균풀링)
x = F.tanh(self.conv2(x)) # ✅ Convolution 2 (5x5 필터, 채널 6 → 16)
x = self.pool2(x) # ✅ Pooling 2
x = F.tanh(self.conv3(x)) # ✅ Convolution 3 (5x5 필터, 채널 16 → 120)
x = x.view(-1, 120) # Flatten
x = F.tanh(self.fc1(x))
x = self.fc2(x) # No activation (CrossEntropyLoss includes Softmax)
return x
| 단계 | 역할 | 코드 | 설명 |
|---|---|---|---|
| Conv1 | 특징 추출 | self.conv1 | 입력 이미지에서 가장 기본적인 모양(선, 점 등)을 감지 |
| Pool1 | 요약 | self.pool1 | 중요한 특징만 요약, 이미지 크기 ↓ 연산량 ↓ |
| Conv2 | 더 복잡한 특징 추출 | self.conv2 | 이전보다 조합된 특징 감지 (예: 곡선, 모서리 등) |
| Pool2 | 요약 | self.pool2 | 요약 반복 |
| Conv3 | 고차원 추출 | self.conv3 | 분류에 필요한 고급 정보 추출 |
3. 학습
import torch.optim as optim
# 모델, 손실함수, 옵티마이저 정의
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = LeNet5().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_losses = []
train_accuracies = []
# 학습 루프
epochs = 5
for epoch in range(epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
# forward
outputs = model(images)
loss = criterion(outputs, labels)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 통계
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
acc = 100 * correct / total
train_losses.append(running_loss)
train_accuracies.append(acc)
print(f"[Epoch {epoch+1}] Loss: {running_loss:.4f}, Accuracy: {acc:.2f}%")
# 테스트 루프
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
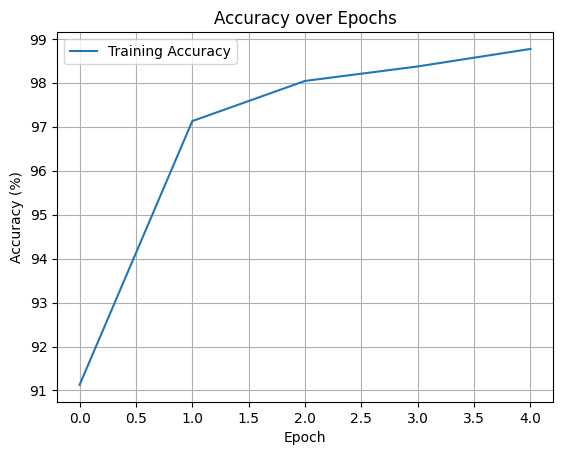
print(f"Test Accuracy: {100 * correct / total:.2f}%")[Epoch 1] Loss: 281.2023, Accuracy: 91.13%
[Epoch 2] Loss: 89.0535, Accuracy: 97.13%
[Epoch 3] Loss: 61.6542, Accuracy: 98.04%
[Epoch 4] Loss: 47.8118, Accuracy: 98.37%
[Epoch 5] Loss: 37.6856, Accuracy: 98.77%
Test Accuracy: 98.39%
4. 평가코드
import matplotlib.pyplot as plt
# Loss 시각화
plt.plot(train_losses, label='Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Loss over Epochs')
plt.legend()
plt.grid(True)
plt.show()
# Accuracy 시각화
plt.plot(train_accuracies, label='Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Accuracy over Epochs')
plt.legend()
plt.grid(True)
plt.show()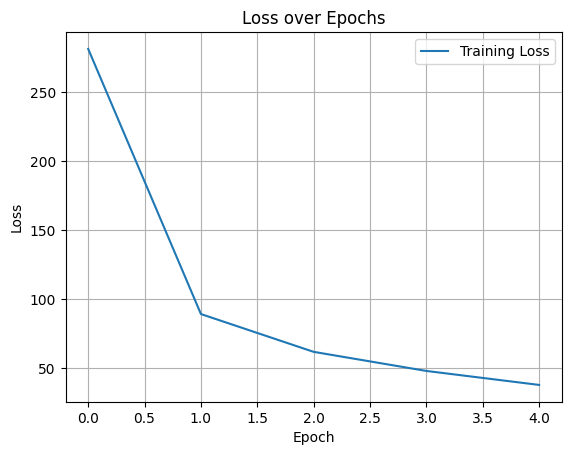
2️⃣ 2. AlexNet (2012, ImageNet 챌린지 우승)
목표: 고해상도 이미지 분류 (ImageNet 데이터셋, 1000종 분류)
입력 크기: 227×227×3 (RGB 이미지)
구성:: Conv (ReLU 포함) → Pool → Conv... → FC → FC → FC
특징
-
ReLU 활성화 함수 사용 (Sigmoid보다 빠르고 성능 좋음)
-
Dropout 도입 (과적합 방지)
-
GPU 2개 사용해서 학습
-
커널 사이즈가 큼 (예: 첫 Conv는 11x11 필터)
-
총 8개 레이어 (Conv 5개 + FC 3개)
🧠 핵심 개선: CNN이 대규모 이미지에도 통할 수 있음을 증명한 첫 모델
자세한 건 위 포스팅을 참고하시라!
3️⃣ 3. VGGNet (2014, Oxford)
목표: 더 깊고 단순한 구조로 정확도 향상
입력 크기: 224×224×3
구성 Conv(3×3, stride 1) 여러 개 → Pool(2×2) → 반복 → FC → FC → Output
특징:
Conv 레이어만 쌓아서 간단하고 일관된 구조
3×3 필터만 사용 (작지만 깊게!)
VGG-16: Conv 13개 + FC 3개
파라미터 수는 많지만 설계가 단순
🧠 핵심 아이디어: “필터는 작게, 네트워크는 깊게”
(깊은 네트워크가 좋은 표현력을 가질 수 있음)
| 모델 | 발표 연도 | 주요 특징 | 입력 크기 | 깊이 |
|---|---|---|---|---|
| LeNet-5 | 1998 | 최초의 CNN, 숫자 인식용 (MNIST), 간단한 구조 | 32×32×1 | 7층 |
| AlexNet | 2012 | 대규모 이미지 처리 (ImageNet), ReLU/Dropout 도입, GPU 활용 | 227×227×3 | 8층 |
| VGGNet | 2014 | 3×3 필터 반복, 깊은 구조, 단순한 아키텍처, 성능 향상 | 224×224×3 | 16~19층 |
