이전 포스팅에서 머신러닝은 분류를 위한 특징 추출을 주로 사람이 직접 정의(예: 색상, 모양, 크기 등)하며, 반면에 딥러닝은 모델이 스스로 특징을 학습한다는 점에서 차이가 있다고 언급했다!
📝딥러닝 학습 과정
1. 원본 이미지 → 특징 추출: 딥러닝 모델은 처음에는 원본 이미지를 입력으로 받고, 점점 더 구체적인 특징을 뽑아낸다. 예를 들어, 처음엔 단순한 선이나 모서리 같은 기본적인 모양을 인식한다.
2. 점점 더 추상적인 정보로 변환: 이미지가 신경망의 여러 층을 통과할수록, 단순한 특징(선, 색깔)에서 더 복잡한 특징(숫자 모양, 패턴 등)으로 변환된다. 이 과정에서 원본 이미지와는 다소 달라 보이는 "추상적인 표현"으로 바뀜!
- 이 때, 신경망의 여러 층을 통과하면서 추출된 추상적인 정보는 각 층의 가중치(weight)에 저장
=> 가중치는 입력 데이터에서 중요한 부분을 강조하거나 덜 중요한 부분을 무시하는 역할을 하는데, 학습 과정에서 가중치가 업데이트되면서, 각 층은 점점 더 복잡한 특징(예: 이미지의 모양, 패턴)을 인식하게 됨.
즉, 가중치가 데이터를 이해하고 변환하는 "규칙"을 저장한 메모리라고 생각하면 메모리라고 생각하면 쉽다!
3. 필요한 정보만 남기기: 여러 층에서 필터를 거치면서 불필요한 정보는 제거되고, 우리가 해결하려는 작업(예: 숫자 인식)에 유용한 정보만 점점 더 정제된다.
결론적으로, 딥러닝은 원본 데이터를 단계적으로 가공하여 우리가 원하는 답을 얻기 위해 필요한 핵심 정보만 추려내는 과정이라고 할 수 있다!
📝신경망에서 어떻게 결과를 예측하고 표현할지❓
1. 분류
- 데이터를 여러 카테고리 중 하나로 나누는 작업
- 예: "고양이" 또는 "강아지" (이진 분류) 또는 "빨강/파랑/노랑" (다중 분류).

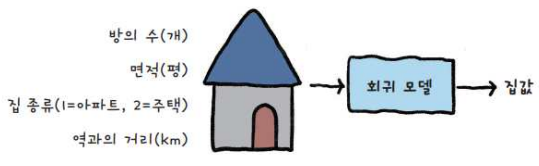
2. 회귀
- 데이터를 숫자 값으로 예측하는 작업
- 예: "내일 기온은 20.5°C일 것이다" 같은 연속적인 값.
3. 출력 계층의 활성화 함수
출력 계층은 최종 결과를 만드는 부분, 여기서 활성화 함수는 결과를 적절히 표현하기 위해 사용된다
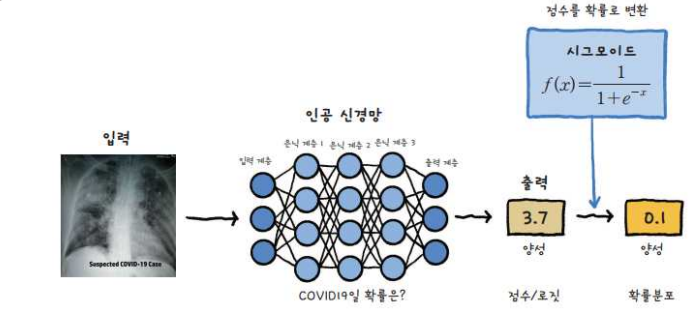
3-1. 시그모이드 함수
- 출력값을 0 ~ 1 사이로 만들어줌
- 이진 분류에서 사용함
- 예: 고양이일 확률이 0.8이라면 "고양이"로 예측.
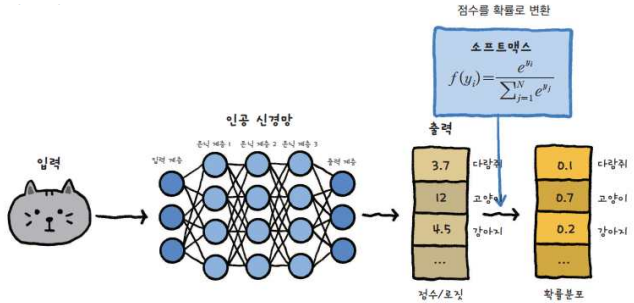
3-2. 소프트맥스 함수
- 출력값을 각 카테고리의 확률로 변환함
- 다중 분류(빨강/파랑/노랑)에서 사용
- 예: 빨강(0.7), 파랑(0.2), 노랑(0.1) → 확률이 가장 높은 "빨강"으로 예측
4. 요약
분류: 확률 기반 → 시그모이드(이진), 소프트맥스(다중)
회귀: 연속적인 값 → 활성화 함수 없이 숫자 출력
결국 난 잘될사람🍀 아자아자🥔