✍️ 머신러닝 학습 과정 (1)
머신러닝은 학습 단계(learning)와 예측 단계(prediction)으로 나뉨.
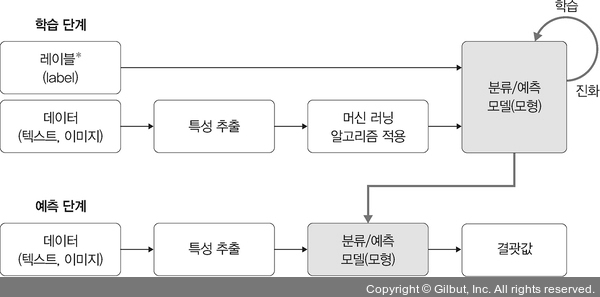
🤔 개인적으로 위에 표를 보면서 궁금했던 건,
(1) 학습단계에서 분류/ 예측 모델이 예측 단계에서 어떻게 쓰이는건지?
➡️ 학습 단계에서 만들어진 분류/예측 모델은 데이터와 라벨(정답)을 바탕으로 패턴을 학습한 결과
➡️ 예측 단계에서는 이 모델을 활용해 새로운 데이터의 결과값(예측값)을 계산하는 데 사용된다고 함
💡정리하면,
학습 단계에서는 모델을 만드는 과정이고, 예측 단계는 만들어진 모델로 새 데이터를 처리하는 것이라고 한다...
(2) 예측 단계에서 데이터와 특성 추출을 왜 또 따로 하는지?
학습 단계의 이미지에서 (크기, 색상) 같은 특징을 추출했다면 예측 시에도 동일한 특성(크기, 색상)을 추출해야 학습된 모델과 일관성이 유지되기 때문임!
=> 학습 단계와 동일한 특성을 추출하지 않으면, 모델이 올바르게 예측하지 못함.
❓또 다시 나의 궁금증.. 그럼 일을 두번 하는게 아닌가? 라는 궁금증이 들었는데, 알고보면 그렇지 않다고 합니다.
💡 사실상 학습 단계에서의 특성 추출 규칙은 이미 정해져 있기 때문에, 예측 단계에서는 이 규칙을 반복 적용하는 것에 불과하다고...
즉, 학습 단계에서 한번 규칙을 정한 뒤, 예측 단계에서는 자동화된 과정을 통해 동일한 규칙을 적용하는 것..! (어렵다..ㅠㅠ)
➕ (추가적으로..)
이를 자동으로 처리하기 위해, 머신러닝 파이프라인(예: Scikit-learn의 Pipeline)이나 딥러닝 모델은 학습 단계와 동일한 전처리 과정을 저장하고 재활용함..!!
✍️ 머신러닝 학습 과정 (2)
머신러닝의 주요 구성 요소는 데이터와 모델(모형)인데,
- 데이터
- 학습 모델을 사용하기 위해 (=훈련시키기 위해) 꼭 필요한 것이다.
- 그렇기 때문에 훈련데이터의 질이 나쁘면 당연히 모델의 질도 떨어질 수 밖에 없다
- 모델
- 머신러닝의 학습단계에서 얻은 최종 결과물인 모델은 데이터와 라벨 간의 관계를 나타내는 일종의 가설(hypothesis)이라고도 한다.
- 이 가설은 주어진 데이터 패턴에 따라 출력(예측값)을 만들어내는 역할을 함.
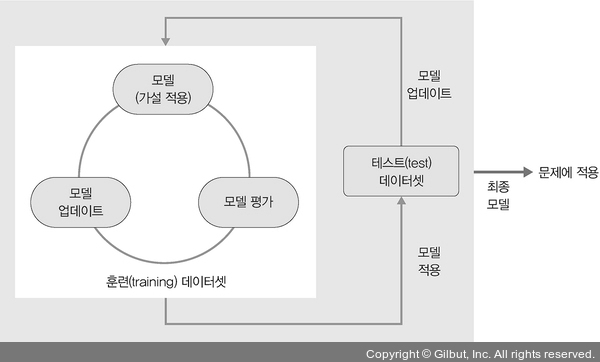
실제로는 복잡하고 (찾아보면 7단계로까지 자세히 포스팅하신 분들이 많지만..!) 간단하게만 언급하자면,
- 모델(또는 가설) 선택
- 모델 학습 및 평가
- 평가를 바탕으로 모델 업데이트 수행.
✍️ 머신러닝 학습 알고리즘 (3)
1. 지도 학습
정답(라벨)이 있는 데이터를 학습해 새로운 데이터를 예측
2. 비지도 학습
정답(라벨) 없이 데이터를 그룹화하거나 패턴을 찾음
3. 강화 학습
에이전트가 환경과 상호작용하며 보상을 최대화하는 방법을 학습
4. 반지도 학습
일부 데이터는 라벨이 있고, 나머지는 라벨이 없는 경우를 학습.
5. 주요 알고리즘 비교
| 학습 유형 | 라벨 여부 | 주요 목적 | 주요 알고리즘 |
|---|---|---|---|
| 지도 학습 | 라벨 있음 | 분류/예측 | 선형 회귀, 결정 트리, SVM 등 |
| 비지도 학습 | 라벨 없음 | 군집화/패턴 탐색 | K-평균, PCA 등 |
| 강화 학습 | 보상 기반 | 최적 행동 학습 | Q-러닝, 심층 강화 학습 |
