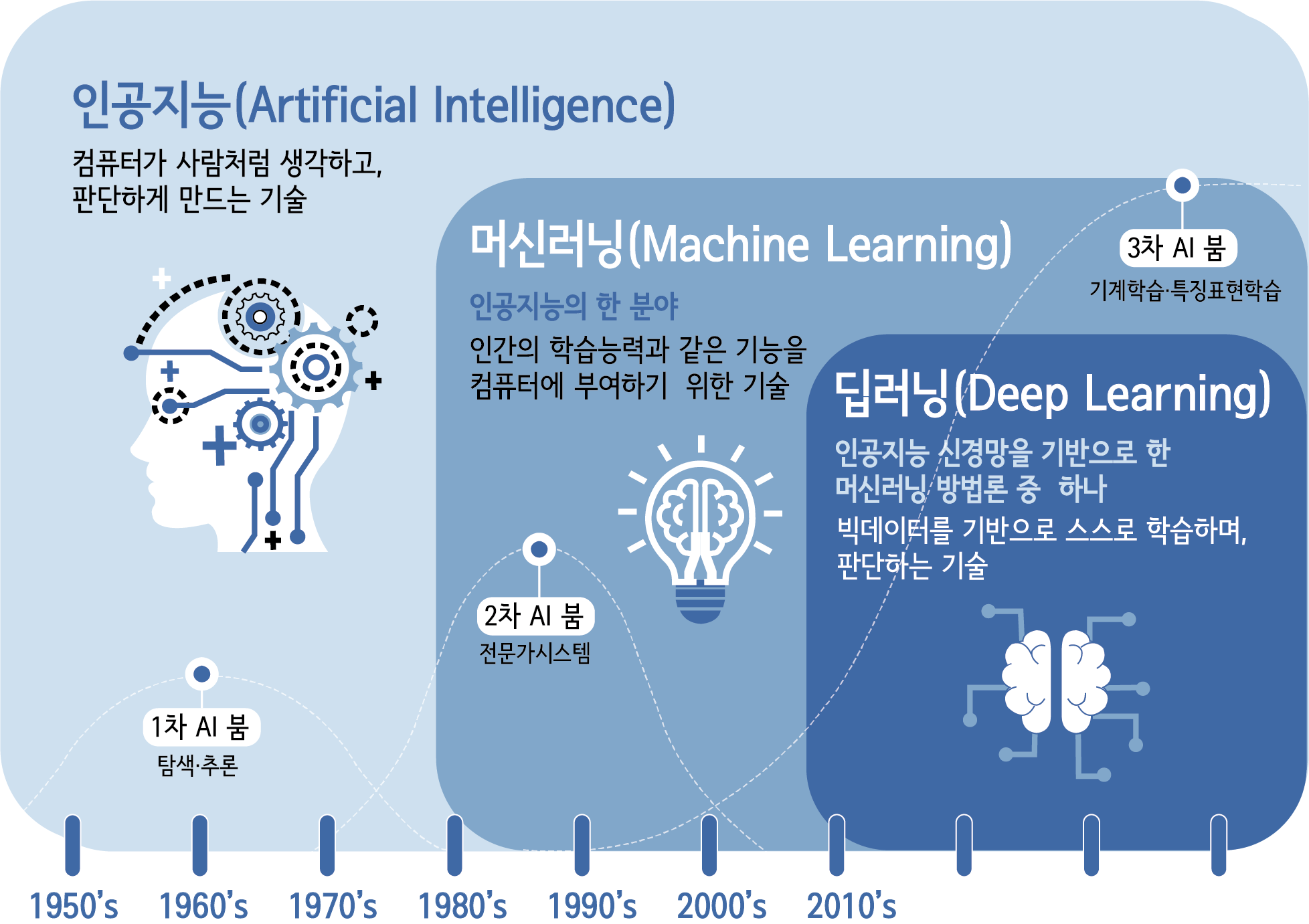
✍️ 인공지능
- 인간의 지능을 모방하여 사람이 하는 일을 컴퓨터(기계)가 할 수 있도록 하는 기술 -> 머신러닝과 딥러닝이 있음
- 관계를 따지자면 인공지능> 머신러닝> 딥러닝
=> 머신러닝과 딥러닝 모두 학습 모델을 제공하여 데이터를 분류할 수 있는 기술인데, 둘의 접근 방식에는 어떤 차이가 있는지?
💡 일단 그 전에, 학습 모델을 제공해야 하는 이유는?
데이터를 분석해 규칙이나 패턴을 자동으로 학습하고, 이를 바탕으로 새로운 데이터에 대한 정확한 예측이나 분류를 수행하기 위함.
💡그렇다면 두 기술의 가장 차이점은?
- 특징 추출 방식
- 머신러닝은 사람이 데이터를 분석해 직접 특징(features)을 설계해야 하지만(=인간이 먼저 전처리를 해야하지만), 딥러닝은 대량의 데이터를 신경망이라는 곳에 적용하면 컴퓨터가 스스로 분석하여 자동으로 특징을 추출하고 학습하도록 함 (이를 통해 인간이 하던 작업을 생략함).
❓ 그럼 머신러닝에서 인간이 먼저 전처리를 해야 하는 이유는? 그러한 경우는?
➡️ 예를 들어, 강아지와 고양이의 이미지 데이터가 있다고 할 때, "강아지는 귀가 동그랗다" 또는 "고양이는 귀가 뾰족하다"와 같은 특징을 사람이 직접 추출해 모델에 입력해야함.
이유는, 머신러닝은 주어진 데이터를 그대로 이해하지 못하기 때문에 사람이 어떤 특징이 중요한지 정의해줘야 하기 때문임.
🧐 예시:
1. 데이터 분석 및 특징 정의
사람이 데이터를 보고, "귀의 모양"이 강아지와 고양이를 구분하는 중요한 특징이라고 판단.
2. 특징 수치화
귀의 모양을 수치로 표현:
예) "귀의 끝이 둥글면 0, 뾰족하면 1" 같은 식으로 데이터를 변환.
3. 구조화된 데이터 생성
각 이미지 데이터를 특정한 형태로 구조화:
예) [귀 모양 = 0, 크기 = 20px, 색상 = 밝음]
이런 형식으로 데이터를 배열화
4. 모델에 입력
위와 같이 수치화된 데이터를 머신러닝 모델에 입력하여 학습을 진행.
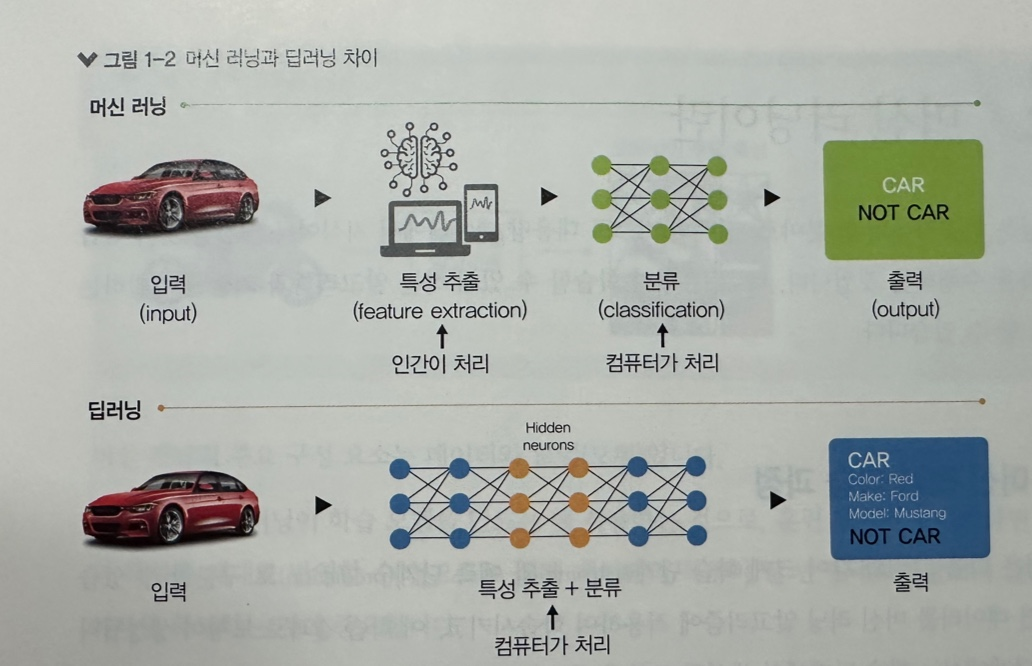
위에 그림을 참고하면 훨씬 보기 수월하다!

결국 난 잘될사람🍀 아자아자🥔