Neural Fields in Visual Computing and Beyond 요약 - Part I(1)

Google에 NeRF라 검색하면 가장 먼저 등장하는 그것....
Neural Fields라는 용어가 Computer Vision에서 정말 유명해진 계기는 아마 Neural Radiance Field라는 논문이 ECCV 2020에 등장했을 무렵 이후일 것이다. NeRF라고도 불리는데 이번에 CVPR 2022에서 NeRF와 관련하여 Review Paper가 나왔고, 굉장히 좋은 내용들을 담고 있어서 이번 기회에 정리하려고 한다.
Abstract
Neural Fields에 대한 정의
Coordinate-based neural networks를 Neural field라고 한다.
저자는 Neural field에서 매우 빠른 기술적인 진보가 진행되었지만, 아직 consolidation of knowledge 측면에서 부족하여 해당 기술에 대한 정보를 제공하고자 paper를 작성하였다고 언급한다.
이 Paper는 크게 Part I, Part II로 나뉜다.
Part I에서는 주로 neural field techniques에 대해 이야기하고
Part II에서는 application of neural fields을 다룬다.
Introduction
Computer vision뿐만 아니라, Robotics와 같은 분야에서 fields의 개념을 자주 사용한다고 한다. 주로 현실세계에 존재하는 물리적인 양을 computer가 알아들을 수 있게 fields와 같은 연속적인 장을 사용하는 느낌인 것 같다.
'Fields are widely used to continuously parameterize an underlying physical quantity of an object or scene over space and time.'
Visual computing task의 opimization problem에 많은 방법론이 존재해왔는데, 2019년 coordinate-based neural network의 등장이 많은 주목을 받았다.
주어진 Parameter에서(위에서 언급한 physical quantity를 computation 세계에서의 parameter로 변환한 것을 말하는 것 같다.) fully connected networks는 continuous signal을 encode할 수 있음을 보여주었다.
이처럼 Neural fields는 많은 주목을 받아왔지만, techniques들과 관련된 여러 수학적인 formulation이 공유되지 못한다고 저자는 말한다.
이러한 이유 때문에, 저자는 이 paper를 통해서 Part I 과 Part II로 나누어 Neural field의 Mathematical formulation을 제공하고, applications of neural fields 정보를 제공한다고 말한다.
Background
친절하게도, Paper Reading에 필요한 큰 맥락의 배경지식을 짚어준다.
1. Fields
Definition 1. A field is a quantity defined for all spatial and/or temporal coordinates.
 저자의 정성이 보통이 아님을 알 수 있다. Table을 제공해가며 field에 대해 설명한다. Field는 말 그대로 '양' 이라고 한다. Gravitational Field에서 Field quantity는 Force per unit mass, 즉, 중력이고 2D circle에서는 원의 반지름이 field quantity이다.
저자의 정성이 보통이 아님을 알 수 있다. Table을 제공해가며 field에 대해 설명한다. Field는 말 그대로 '양' 이라고 한다. Gravitational Field에서 Field quantity는 Force per unit mass, 즉, 중력이고 2D circle에서는 원의 반지름이 field quantity이다.
2. Neural Network
Neural network는 Artificial Neurons을 많은 층으로 연결하여 고정된 입력과 고정된 출력 사이의 비선형 mapping을 학습하게 하는 것을 의미한다.
3. Neural Fields
Definition 2. A neural field is as field that is parameterized fully or in part by a neural network
4. Terminology
Visual computing에서는
Neural field = neural implicits = coordinate-based neural networks.
Part 1
- Process overview
Visual computing 부분에서 전형적인 neural fields의 process는 다음과 같다.
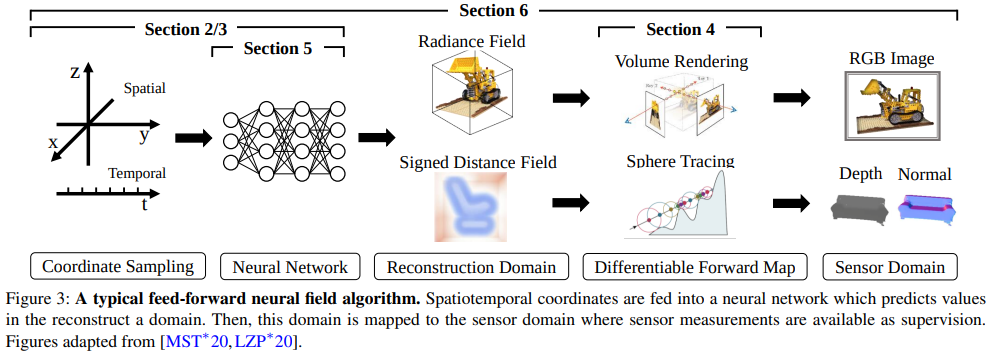
- Coordinate sampling을 진행하고, 결과를 Neural Network에 넣어서 field quantities를 얻는다. (Field quantities는 Desired reconstruction이다. 즉, network를 통해 얻고자 하는 output 이다.
- Supervise가 가능하게 하기 위해, forward map을 적용하여 recon된 결과와 sensor domain값(GT)를 연관시켜준다.(그냥 일반적인 neural net에 input을 넣고 output 뽑는것과 동일한 셈)
- reconstruction signal과 sensor measurement사이의 비교를 통해 recon error 또는 loss를 구해준다.
- 해당 Loss를 통해서 network optimization을 진행한다.
통상적으로 이런 process를 따른다고 하는데, 저자는 많은 문제들이 reconstruction 결과에 영향을 끼친다고 한다. 이러한 문제를 뛰어넘고 좀 더 나은 결과를 얻기 위해 저자는 총 5개의 section으로 나누어 technique을 알려준다.
- Technique overview

1. Prior Learning and Conditioning : 불완전한 sensor signal에서 부터 reconstruction을 도와주기 위해 prior learning, conditioning을 적용한다고 한다.
2. Hybrid Representation : 메모리와 계산적인 부분, neural network의 효율성을 위해 hybrid representation을 사용한다고 한다.
3. Forward map : recon 결과를 supervise하기 위해 미분 가능한 forward map을 사용한다.
고 한다.
4. Network architecture : neural network의 spectral biases문제(blurriness)와 효율적인 미분,적분 계산을 위해 적절한 network architecture를 선정한다고 한다.
5. Manipulate neural field : editable representation을 얻기 위해 neural field에 constraint와 regularization을 추가한다고 한다.
2. Prior Learning and Conditioning
상단에서 언급하였듯이, Prior Learning, Conditioning은 불완전한 sensor signal에서 부터 reconstruction을 도와주기 위해 적용한다고 한다.
여기서 다룰 내용은 다음과 같다고 한다.
- How to pose optimization problems that learn variables z
- How to infer z given a set of imcomplete observations
- How to condition the neural field on z
2.1 Conditional Neural Fields
2.1.1 Encoding the conditioning Variable Z
대전제는 Obervation O를 latent variable z로 mapping 하는 것
여기서 Z는 관찰을 통해 얻은 센서값(Image, 3D point cloud 등등....)을 encoding하여 함축된 정보로 나타낸 것을 말한다!!!
- Feed-forward Encoders/Amortized Inference
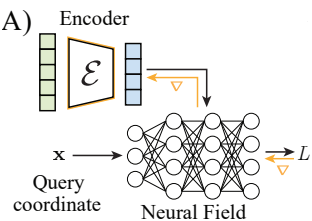
z = ε(O)를 통해서 observation O를 latent variable인 z로 mapping한다.
ε가 encoder인 셈이고, decoder는 neural field이다. 여기서 neural field를 통해서 latent code를 condition 한다고 한다.
이러한 Conditioning method는 encoder decoder 구조를 통해서 single forward pass가 가능하기 때문에 빠르다고 한다. 이러한 method의 예로 PointNet, ResNet, VoxNet이 있다.
- Auto-decoders
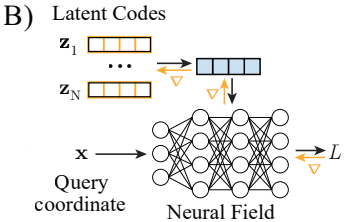
Encoder는 없고 decoder만 존재하는 구조이다. encoding은 stochastic optimization을 통해서 이루어진다고 간략하게 말한다. latent code는 '수식'을 통해서 얻어지며, 모든 training 과정에서 observation은 각자의 latent code z에 의해 initialized 된다. latent code z를 optimize하는 방법은 z를 neural field에 mapping을 통해 loss를 계산하고, back-prop와 gradient descent를 통해서 z가 optimize된다.
test mode에서는 neural field의 parameter를 고정한 채로, 새로운 Observation O'에 대해 reconstruction error를 통해서 latent code z'를 optimize한다. Optimization을 진행하는 부분이 상단에서 소개한 feed-forward encoder부분의 encoder와 같은 기능을 한다고 생각하면 된다. 결과적으로 Observation O에서 latent variable z를 mapping 해준다.
| Encoding 종류 | Feed-forward | Auto-decoder |
|---|---|---|
특징 | Faster Constrained by addtional parameter | slower Additional parameter ✖️ Assumption about O ✖️ |
Example1(2D image) | 2D CNN encoder assume O to be on a 2D pixel | No need to assume O (Observation) Can ingest tuples of pixel coordinate and color independently |
Example2(3D recon) | Convolutional encoder is constrained by the 2D geometry of its kernel | Free from additional parameter such as 2D geometry |
- Hybrid Approaches
Hybrid approach도 존재하는데, 이 방법은 처음 z 를 초기화 하는 단계에서 forward pass의 Encoder ε를 사용하고, z 를 optimize 하는 과정에서는 auto-decoding을 사용하는 방식이다.
2.1.2 Global and Local Conditioning
- Global conditioning
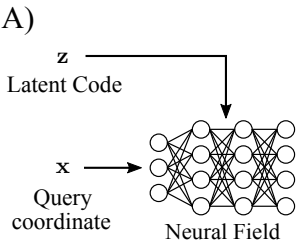 Single latent code z 로 전체 neural field를 결정한다고 한다. Single로 처리한다는 뜻은, 공간 영역 정보 Encoding할때, 하나의 공간을 작은 3D voxel 단위로 쪼개서 표현하는 것이 아니라, 전체 공간 하나를 퉁 쳐서 encoding 한다는 뜻이다. 단 하나의 z 를 통해서 정보를 encoding하기 때문에, 여러 물체가 등장하고, 큰 공간을 다루는 task에 대해서는 부적합하다고 말한다. 단순하게 하나의 object나 human body의 정보를 다루는 task에서는 적합하다고 한다.
Single latent code z 로 전체 neural field를 결정한다고 한다. Single로 처리한다는 뜻은, 공간 영역 정보 Encoding할때, 하나의 공간을 작은 3D voxel 단위로 쪼개서 표현하는 것이 아니라, 전체 공간 하나를 퉁 쳐서 encoding 한다는 뜻이다. 단 하나의 z 를 통해서 정보를 encoding하기 때문에, 여러 물체가 등장하고, 큰 공간을 다루는 task에 대해서는 부적합하다고 말한다. 단순하게 하나의 object나 human body의 정보를 다루는 task에서는 적합하다고 한다.
- Local Conditioning
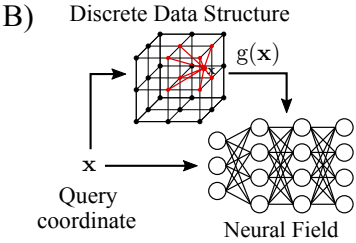 말 그대로, 전체에 대한 정보를 encoding하는 것이 아니라, 전체에서 쪼개어진 local한 정보를 통해 conditioning을 진행한다. 예를 들면, 공간 영역 정보를 encoding할 때, 전체 공간을 3D Voxel로 나누어, feature extraction을 진행한 후에 neural field를 통해서 learning을 진행하는 것을 생각할 수 있다.
말 그대로, 전체에 대한 정보를 encoding하는 것이 아니라, 전체에서 쪼개어진 local한 정보를 통해 conditioning을 진행한다. 예를 들면, 공간 영역 정보를 encoding할 때, 전체 공간을 3D Voxel로 나누어, feature extraction을 진행한 후에 neural field를 통해서 learning을 진행하는 것을 생각할 수 있다.
2.1.3 Mapping to Neural Field Parameters
앞에서는 latent code 를 어떻게 구성할 것인가에 대해 논하였다면, 이번 장에서는 어떻게 를 neural field에 parameterize하여 사용할 것인지 논할 것이다. 이 section을 꿰뚫는 중요한 원리는 다음과 같다.
latent variable인 를 neural network parameter의 subset인 에 mapping 하는 function 를 정의하는 것.
Neural field를 conditioning 하는 방법
1. Concatenation을 통한 conditioning
- coordinate input x와 latent code z를 directly concatenate하는 방법
- ex)
- neural field: R^2-> R^3 (2D pixel coordinate -> RGB colors)
- latent code z -> R^n
이때 conditioning은 R^(2+n)->R^3
- 기존의 2D pixel coordinate의 2차원과 latent code z의 n차원을 합한 것
Conditioning via concatenation은 affine transformation ''를 정의하는 것이다.
2. Hypernetworks
- Function 를 neural network로 parameterize하는 것.
- Latent code 를 input으로 사용하고, output을 parameter인 를 forward pass로 뱉어낸다.
- 이게 General form이다.
- 왜냐하면, Other form of conditioning은 parameter 의 subset(부분집합)을 출력함으로 conditioning이 이루어지기 때문이다.
- example) concatenation으로 conditioning하는 경우에는 () biases of the first layer of Φ 이기 때문에. 아마 이거 일까...?? 명확한 명제는 아니다.
3. FiLM and Other Conditioning
FiLM(feature-wise transformations)를 통해서 conditioning을 진행한다.
Network Ψ를 사용해서 per-lay, per-neuron 단위로 scale vector γ와 bias β vector를 latent code z를 통해서 예측한다. 자세한 설명은 모르겠음
2.2 Gradient-based Meta-learning
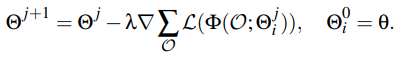 2.1에서 등장한 conditinoal neural field를 대신할 수 있는 approach라고 한다.
2.1에서 등장한 conditinoal neural field를 대신할 수 있는 approach라고 한다.
모든 Neural fields를 specializations of an underlying meta-network with parameters Θ라고 본단다. 각각의 Instance들은 Observation O에서 recon loss인 L를 minimizing하는 meta-network fitting을 통해 얻어진다고 한다. auto-decoder와 비슷하게, encoder ε의 역할을 optimization과정이 대신한다.
- Conditional neural field 에서는 Ψ의 parameter를 통해서 prediction값을 얻을 수 있었는데, 이러한 방식은 Φ의 parameter들이 low dimension space에 머무르게 한다고 한다.
- 반면에, gradient-based meta-learning에서는 optimization 과정을 통해서 neural field의 parameter Θ^를 meta network parameter인 Θ에서 멀리 떨어지게 하기 때문에, fast inference가 가능하게 하고, few gradient descent step에서 Θ^를 얻을 수 있다고 한다. Low-dimension의 latent variable을 가정하지 않았기 때문에, neural field Φ의 full expressivity를 유지할 수 있다고 한다. 이 내용은 Original NeRF paper의 Positional Encoding에서 등장하는 내용과 겹치는 듯 하다. neural network에서 데이터를 고차원으로 보냄으로써, 정보 손실을 줄이고 학습속도를 상승시키는 효과를 여기서도 동등하게 누리는 듯..??
