
PodDisruptionBudget에 대해 공부한 내용을 정리한 글입니다.
쿠버네티스 공식 홈페이지 Specifying a Disruption Budget for your Application를 참고하여 진행하였습니다.
또한, 마스터 노드1, 워커노드 2로 실습 진행하였습니다.
🤣🤩😊CKA 자격증 준비 및 쿠버네티스 공부 정리입니다.
서론
cordon과 drain에 대해 작성하려고 했으나, 공식 document에서..

PodDisruptionBudget에 대한 개념을 요구하기 때문에 먼저 선행학습을 진행하려고 합니다.
PodDisruptionBuget(PDB)
PodDisruptionBudget (파드 중단 예산)
Pod수를 일정 수 를 유지하지 못하면 노드 다운이나 오토스케일러에 의한 스케일 다운등을 막고, Pod 수를 일정 수준으로 유지할 수 있을때 다시 그 동작을 하도록 한다.
참고: Kubernetes 서버는 버전 v1.21 이상이어야 합니다.
pod 중단
Pod의 개수는 replica 수 만큼을 항상 유지하도록 되어있습니다.
Pod의 수가 replica 수를 유지 못하고 줄어드는 경우가 있는데,
- 자발적 중단(Voluntary disruptions)
- 비자발적 중단(InVoluntary disruptions)
- 자발적 중단의 예
- 관리자가 pod를 관리하는 배포 또는 컨트롤러 삭제 및 pod 직접 삭제
- 배포의 포드 템플릿 업데이트로 인한 재시작
- 수리 또는 업그레이드를 위해 노드를 drain할 때
- 비자발적 중단의 예
- 노드를 지원하는 물리적 시스템의 하드웨어 오류
- 클러스터 관리자가 실수로 VM을 삭제
- 클러스터 네트워크 분할로 노드가 사라졌을 때
- 노드의 리소스 부족
- 커널 패닉
PDB 동작 원리
PDB는 자발적 중단으로 인해 동시에 다운되는 복제된 애플리케이션의 포드 수를 제한합니다.
어플리케이션에서는 로드를 처리하는 복제본 수가 전체의 특정 비율 미만으로 떨어지지 않도록 할 수 있습니다.
의문이 드는점,
deployment에서도 replicas를 통해 pod를 유지하지 않습니까?
여기서 PDB를 사용해야 하는 이유를 찾을 수 있었습니다.
사전에 Deployment의 replicas 값을 2로 둔 상황입니다.
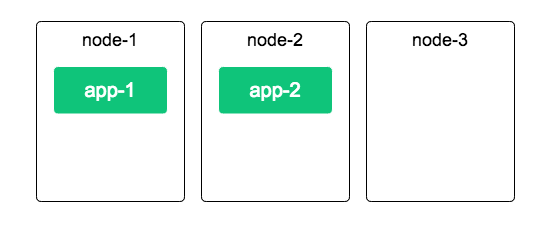
사진처럼 노드 3개가 존재하고, pod는 app-1,2 2개가 돌아가고 있습니다.
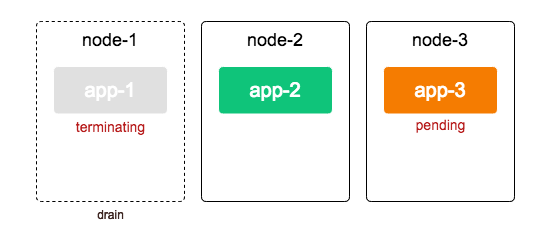
클러스터 관리자가 node-1을 업그레이드하기 위해 drain작업을 시작합니다.
drain이란 node안의 pod들을 모두 다른 node들로 방출하는 것입니다.
따라서 app-1은 다른 노드 즉, node-3으로 할당됩니다. 새로 생성되기 때문에 app-3으로 생성되었습니다. 아직 옮겨가고 있는 중이기 때문에 pending상태입니다.
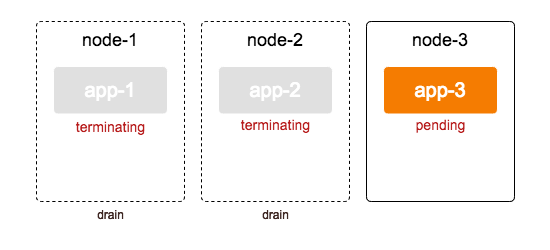
하지만 여기서, app-3이 생성되기 전에 node-2를 또다시 drain하게 된다면?
이 순간, 결국 동작하게 되는 pod가 존재하지 않습니다.
만약, PDB를 사용해서 pod가 최소 1개가 유지되도록 설정해 둔다면..?
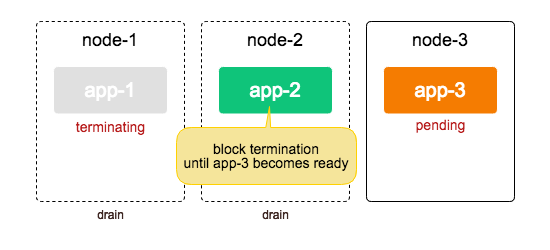
클러스터 관리자가 node-2를 drain하려고 한다면 그 행위가 block되는 원리입니다.
PDB 정의
PDB는 Yaml 파일을 통해 리소스로서 정의됩니다.
PDB를 정의하는 방법 중 pod 수를 지정하는 방법은 2가지가 존재합니다.
minAvailable: 최소한 유지해야하는 Pod 수 정의maxUnavailable: 최대로 허용할 수 있는 Unhealthy한 Pod 수 정의
이 두 방법은 Pod의 숫자로 정의할 수도 있고, 백분율(%)를 사용할 수 있습니다.
하지만, 백분율은 정확하게 매핑되지 않을 수 있습니다.
따라서 이 값은 반올림으로 숫자가 정해집니다.
예) pod 숫자가 7인데 minavailable이 50%일 경우, 3인지 4인지 모름
따라서 반올림되어 4가 됨
PDB를 만든 후에 PDB안에 label selector를 정의해서 PDB를 적용할 POD를 선택할 수 있습니다.
PDB는 하나씩 사용할 수 있습니다.
# minAvailable 사용
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zookeeper# maxUnavailable 사용
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
maxUnavailable: 1
selector:
matchLabels:
app: zookeeperapp=zookeeper인 라벨을 갖는 pod들에 대한 PDB입니다.
둘 중, minavailable 방법을 사용해보겠습니다.
minavailable 시나리오
시나리오는 다음과 같습니다.
node 2개에서 app=zookeeper인 pod를 할당하는데, node01에는 1개, node02에는 2개를 할당하겠습니다.
그리고, PDB를 만들어 최소 유지되야하는 pod 개수를 2개로 잡아두겠습니다.
그런 다음에 node02에 있는 pod(deployment)를 삭제한다면, 재 생성되는 동안
PDB의 minavailable 2 를 만족하지 못할 것입니다.
제 생각에는 그 명령어가 block될 것 같은데, 한 번 시도해보겠습니다.
안되면, drain진행하겠습니다.
nodeAffinity를 통해 node01에 pod 1개, node02에 pod 2개를 배치할 것이기 때문에 node에 먼저 label을 부여하겠습니다.
node01 -> key=worker1
node02 -> key=worker2

deployment에 nodeaffinity를 입력하여 배치해보겠습니다.
# node01에 pod 1개 배치
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: zoo-keeper
name: zoo-nginx1
spec:
replicas: 1
selector:
matchLabels:
app: zookeeper
template:
metadata:
labels:
app: zookeeper
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: key
operator: In
values:
- worker1
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80# node02에 pod 2개 할당
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: zoo-keeper
name: zoo-nginx2
spec:
replicas: 2
selector:
matchLabels:
app: zookeeper
template:
metadata:
labels:
app: zookeeper
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: key
operator: In
values:
- worker2
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80


pdb도 생성해보겠습니다. 이 pdb는 app=zookeeper의 라벨을 가진 pod들을 관찰합니다. 그리고 적용하겠습니다.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zookeeper

네 이제 node02에 적용되어있는 deployment를 지워보겠습니다.

deploy를 지우니.. 하나씩 지워지고 생성되기 때문에 2개를 만족해서 그런걸까요..? 지워집니다.
그러면 이제 위의 예시처럼 drain을 진행해보겠습니다.
$ kubectl drain [노드_이름]
scheduling은 막혔지만, cannot delete DaemonSet-managed Pods하다네요.. DaemonSet Pod들이 존재하기 때문에 drain이 안되는 것 같습니다. 친절하게 명령어도 알려주는 군요. --ignore-daemonsets 다시 진행하겠습니다.
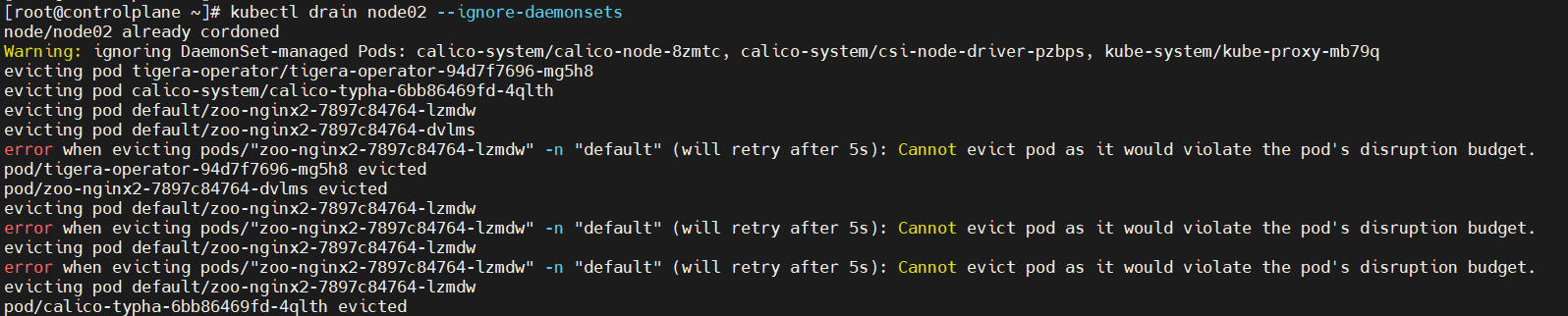

네.. 결과를 확인해보면 PDB에 의해서 한 번에 pod들이 사라질 때, PDB의 minAvailable로 인해서 pod가 2개는 보장이 되는 것을 알 수 있습니다.
pod 한 개는 drain작업으로 인해서 방출되었고, nodeAffinity가 적용되어 node02에만 할당이 될 수 있기에 pending상태에 머물러 있는 것을 알 수 있었습니다.
나머지 pod 1개는 PDB에 의해서 drain작업에서 살아남게 되었습니다.
이 POD는 정상적으로 동작할까요?
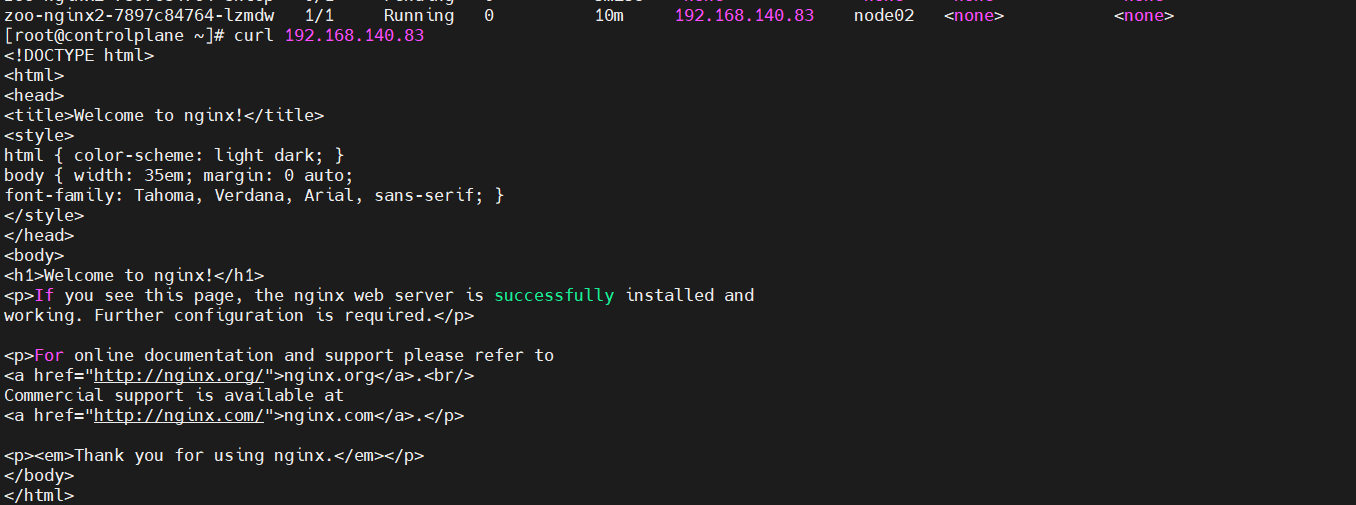
네 nginx가 잘 실행되고 있었습니다.
#drain 해제
$ kubectl uncordon [노드_이름]
pending상태의 pod가 다시 running상태로 돌아왔습니다.
PDB로 인해서 Drain이 제대로 실행되지 않았다는 점이 중요합니다..
PDB 정리
위의 시나리오 실습으로 인해서 쿠버네티스 공식홈페이지가 왜 PDB에 대해 사전지식이 필요하다고 했는지 알 수 있었습니다.
만약, 고가용성이 필요한 어플리케이션의 경우, 자발적인 중단이 일어날 때 PDB를 설정해두어서 어플리케이션이 중단되지 않게 설정할 수 있습니다.
drain작업으로 pod들이 한 번에 사라질 뻔해도 PDB의 보장된 Pod 수가 존재해 어플리케이션은 잘 동작하기 때문이죠!
마무리 하면서
PDB에 대한 시나리오를 스스로 생각해보면서 실습하니 재밌게 포스팅한 것 같습니다.
관리자에 의해서 중단은 언제든 일어날 수 있습니다. 중단이 일어나는 POD에 고가용성을 보장해야하는 POD가 존재할 수 있기 때문에 PDB를 설정하는 방법에 대해 알아둔다면 도움이 될 것입니다.
다음에는 cordon, drain에 대해 다뤄보겠습니다. 감사합니다!
Reference
