[논문 리뷰]AN IMAGE IS WORTH 16X16 WORDS : TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (Vi-T , Vision Transformer)
PapersReview

AN IMAGE IS WORTH 16X16 WORDS : TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
본 논문은 NLP 에서만 적용되었던 Transformer 가 Computer Vision 분야로 온전히 넘어온 내용을 담고 있다.
본 논문이 등장했었을 때, Vision 분야에서는 아직 Transformer 구조가 활발하게 적용되는 단계는 아니였는데, 이 논문에서는 비전 분야에서 CNNs에 의존하는 것이 필수적인 것은 아니며, CNN을 사용하지 않는 pure transformer또한 이미지 분류 task에서 매우 좋은 성능을 달성할 수 있음을 보여주었다.
ViT는 입력 이미지를 2D 패치로 나누어 각 패치를 1D 시퀀스로 변환한 후, Transformer의 입력으로 사용한다. 이를 위해, 각 패치는 학습 가능한 linear projection를 통해 고정된 크기의 임베딩 벡터로 변환한다. 이러한 patch embedding은 Transformer의 입력으로 사용되며, 이를 통해 이미지를 처리하고 분류 작업을 수행한다.(여기서 image patches 들을 sequence로 보았다.)
ViT는 충분한 규모의 데이터로 사전 학습된 후, 작은 이미지 인식 벤치마크에서 높은 성능을 보였다.
METHOD
Vision Transformer (Vi-T)
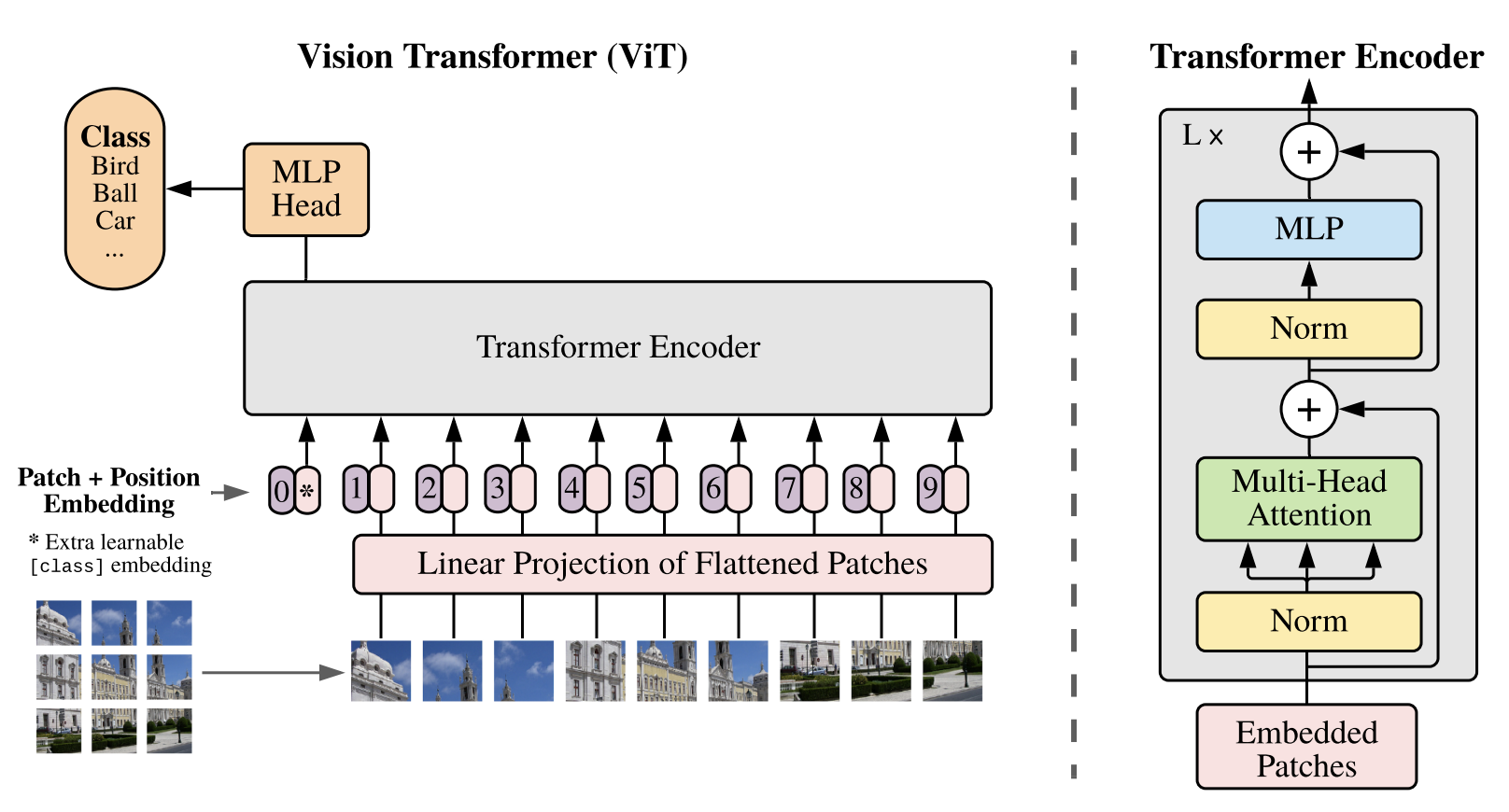
- ViT에서는, standard transformer와 다르게
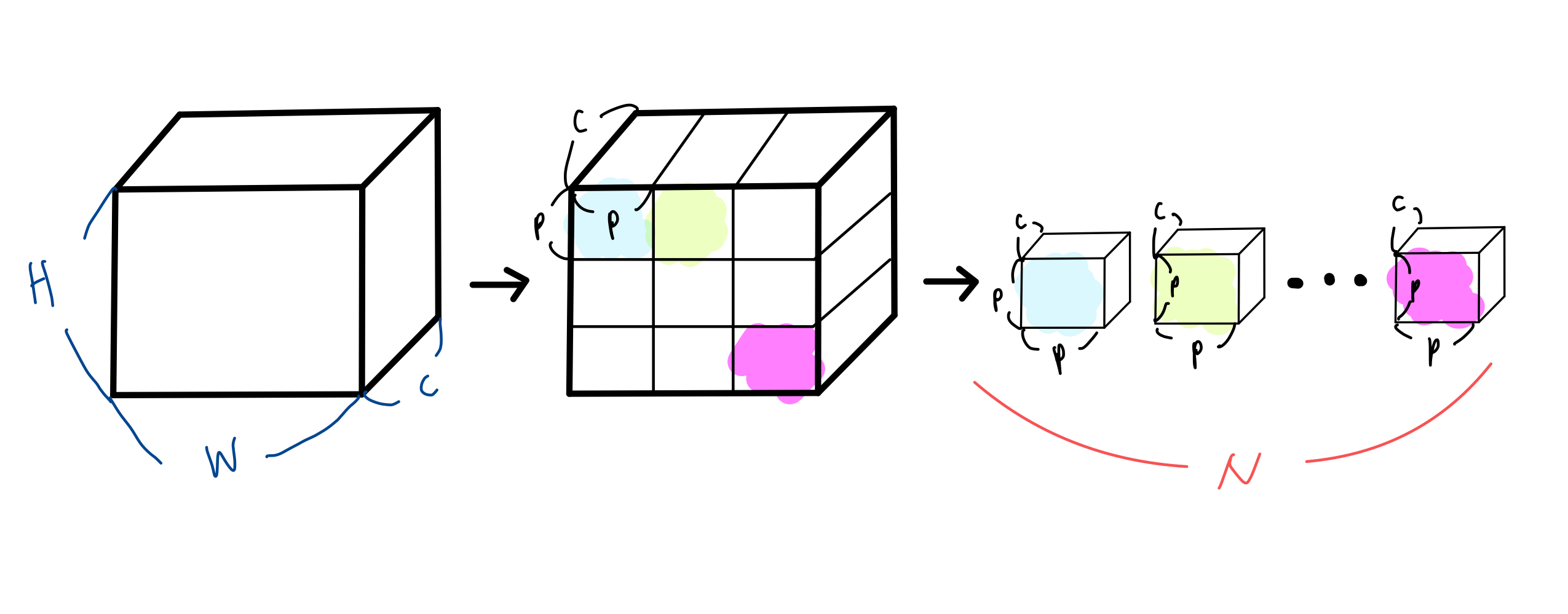
2차원의 image를 다뤄야하기 때문에 input에 해당하는 위치에서 reshape 작업을 진행해야한다.
reshape 는 크기의 이미지 를 크기의 flattened 2D patches 로 reshape 해준다. 여기서
: 원본 이미지의 해상도
: 채널 개수
: 각 image patch의 해상도
: reshape 결과 나오게 되는 image patches의 개수
위의 결과를 통해 각 token이 차원의 latent vector를 갖는, 길이 N의 효율적인 input sequence(tokens)를 형성한다. 그림으로 표현해보면
하지만, standard transformation 에서는 input sequence와 query들은 D차원의 latent vector를 가진다.
- 따라서, 차원의 이미지 패치를 D차원으로 매핑시키는 linear projection과정을 추가하여 맞춰준다. 이 때 나온 output값을
patch embeddings라고 부른다. 다음과 같은 식을 이용하여 변형을 진행한다.
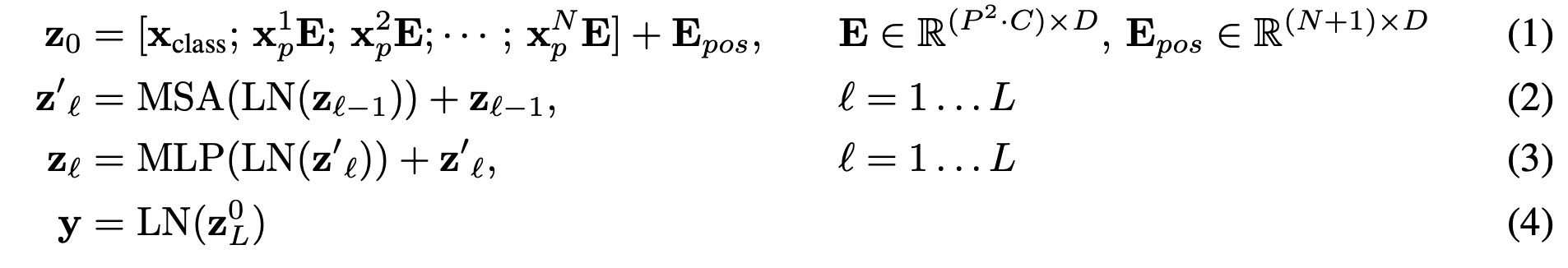
-
Class embeddings 과정을 살펴보면, 위의 과정을 거쳐 얻은 embeded patches의 좌측에 BERT와 유사하게 학습할 수 있는
class embedding을 추가해준다.
본 embedding 을 진행하면 transformer encoder의 output 에서 예측한 이미지 label 를 반환하는 역할을 한다. -
여기에 추가적으로
Positional embedding이 있는데, 본 논문에서는 원래 이미지에 맞게 positional embedding도 2D-aware position embeddings 을 사용하려 했으나 성능 향상 크게 되지 않아 기존standard learnable 1D position을 사용한다.
즉, Positional embeddings은 patch embeddings과 더해져 트랜스포머 input으로 작동하게 되는 것 !
Fine-Tuning And Higher Resolution
NLP 분야 에서 BERT, GPT 등의 사전 학습된 언어 모델을 fine-tuning하여 특정 자연어 처리 작업에 맞게 조정하고, 음성 인식 분야 에서는 DeepSpeech, Wav2Vec 등의 모델을 fine-tuning하여 새로운 음성 인식 작업에 맞게 조정한다.
비전 분야 또한 마찬가지이다.
ViT는 대량의 데이터셋에 대해 사전 학습한 후 더 작은 다운스트림 태스크에 fine-tuning 하는 방법을 취한다.
본 논문에서는 기존 transformer 에서 진행했었던 것처럼 Vi-T를 large dataset에 pre-trained한 다음, down stream tasks에 fine-tuning을 진행한다.
이러한 down stream task에 적용하기 위하여 pre-train 할 때 prediction head를 없애고, 0으로 초기화된 차원의 feed forward layer 로 변경을 진행하였다. (K는 downstream task의 class 개수)
여기서 pre-trained할 때의 이미지 해상도보다, 고해상도로 down-stream task에 fine-tuning할 때 효과적이라고 한다.
고해상도 이미지를 사용할 때에는 pre-trained 단계에서 사용했던 patch size와 동일한 size를 사용해 더 긴 sequence length를 사용한다.
단, pre-trained 단계에서 학습시켰던 positional embedding은 효과가 없어지기 때문에 길이에 맞춰 2D interpolation을 진행한다는 부분에 유의해야한다.
이 과정에서 해상도(resolution)을 조정하고 패치(patch)를 추출하는 과정이 유일하게 Vision Transformer에서 inductive bias가 수동으로 작업해야된다는 특징을 지니게 된다.
Vision Transformer의 처리과정
ViT가 이미지 데이터를 어떻게 처리하는지 과정별로 설명하고 있다.
Embedding projection
-
ViT는 펼쳐진 패치를 더 낮은 차원의 공간으로 매핑한다.
-
다음 이미지는 trained 된 embedding filter 중 중요한 요소들을 나타내는 것이다.
-
이러한 중요 요소들은 각 패치에 대해 저차원의 representation을 만드는 기본 함수들을 나타내는 것으로 보인다.

Positional Embedding
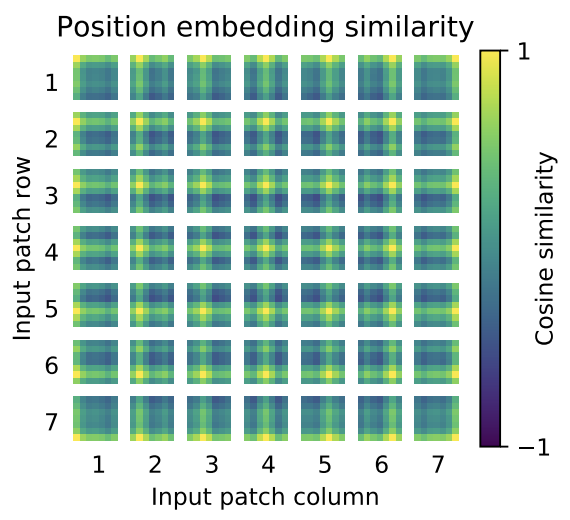
-
linear projection 이후 과정으로, 각각의 패치 representation에는 positional embedding 이 더해진다.
-
위의 시각화 결과를 보면, 모델은 이미지 내의 거리 개념을 인코딩하여 positional embedding에서 유사성이 나타난다는 것을 볼 수 있다.
-
즉, 가까운 거리에 있는 패치는 비슷한 positional embedding을 갖게된다.
-
추가적으로 행-열 개념의 구조가 나오는데, 같은 열이나 행에 위치한 임베딩이 비슷하게 보인다는 특징을 지니고 있다.
-
또한, 더 큰 grid에 대해서는 sinusoidal 구조가 더 명확하게 나타나는데, positional embedding 이 2차원의 이미지를 나타내는 법을 학습한다는 것을 나타낸다.
Self- Attention

-
Self-attention의 경우, transformer 의 핵심 구조로 가장 밑단에 있는 레이어에서부터도 Vi-T가 전체 이미지에 있는 정보를 통합할 수 있도록 도와준다. -
위의 이미지는 attention weight에 기반하여 이미지 공간 상에서 정보가 취합되는 평균 거리를 구해보았다. (여기서 attention distance는 CNN에서 receptive field와 비슷하게 해석할 수 있다.)
-
실험 결과, attention head 중 일부는 가장 낮은 레이어에서부터 대부분의 이미지에 attend 하고 있고, 이렇게 global하게 정보를 통합하는 능력을 모델이 활용하는 모습을 확인할 수 있다.
-
다른 attention head는 밑단 레이어에서 일관적으로 작은 거리의 패치에 집중하는 모습을 보였는데, 이렇게 지역적인(local한) attention은 하이브리드 모델에서는 잘 나타나지 않았다. 즉, 이 attention head는 CNN의 밑단에서 일어나는 것과 비슷한 작용을 하는 것이라고 생각할 수 있다.
-
attention이 일어나는 거리는 네트워크의 깊이가 깊어질수록 늘어난다는 것도 찾을 수 있었다.
-
전체적으로 모델은 의미적으로 분류 과제에 필요한 부분에 attend 하는 것을 찾을 수 있었다.
Self - Supervision
-
본 논문에서는 라벨링 된 데이터셋에 대한 사전학습 대신 Self- Supervision 학습을 사전학습 과제로 실험을 진행하였다.
-
이미지에 대해 masked patch prediction 과제를 주고 ViT의 작은 모델 (ViT-B/16)을 학습을 진행하였는데,
-
결과로, ImageNet에서 79.9%의 성능을 얻었고, 이는 from-scratch로 학습했을 때보다 2% 높은 성적을 얻었다.
-
하지만 이는 supervised pretraining에 비해 4% 떨어지는 정확도이다.
