
🧭 시계열을 위한 딥러닝
1️⃣ 다양한 종류의 시계열 작업
시계열이란?
시계열 데이터는 일정한 간격으로 측정하여 얻은 모든 데이터를 말한다.
(예를 들어 주식의 일별 가격, 도시의 시간별 전력 소모량, 상점 주간별 판매량 등..)
지금까지 보았던 데이터와 달리 시계열을 다루려면 시스템의 역학을 이해해야한다.
주기성, 시간에 따른 트렌드, 규칙적인 형태, 급격한 증가 등이 있다.
가장 일반적인 시계열 관련 작업은 예측 인데, 현시점의 시계열 데이터 다으메 일어날 것을 예측하는 것이다. 그 외에도
분류 : 하나 이상의 범주형 레이블을 시계열에 부여한다. 예를 들어 웹 사이트의 방문자 활동에 대한 시계열이 주어지면 방문자가 봇인지 사람인지 분류한다.
이벤트 감지 : 연속된 데이터 스트림에서 예상되는 특정 이벤트 발생을 식별한다. 예를 들어 시리야 라던지 오케이 구글이라던지,,
이상치 탐지 : 연속된 데이터 스트림에서 발생하는 비정상적인 현상을 감지한다. 이상치 탐지는 일반적으로 비지도 학습(unsupervised learning)으로 수행된다. (어떤 종류의 이상치를 찾는지 모르는 경우가 많기 때문에)
이 파트에서는 순환신경망(Recurrent Neural Network)에 대해 배우고 시계열 예측에 적용하는 방법을 알아보자 !
2️⃣ 온도 예측 문제
이 문제를 통해서 CNN합성곱 네트워크가 이런 종류의 데이터셋을 잘 처리하는데 적절하지 않으며 순환 신경망이 이런 종류의 문제에 뛰어나다는 것을 확인해볼 것이다.
이번장에서 사용할 데이터는 독일 예나(Jena)시에 있는 막스 플랑크 생물지구화학연구소의 기상 관측소에서 수집한 것이며, 수년간에 걸쳐 14개의 관측치가 10분마다 기록되어있다. 먼저 데이터를 다운받고 압축을 푼다
!wget https://s3.amazonaws.com/keras-datasets/jena_climate_2009_2016.csv.zip
!unzip jena_climate_2009_2016.csv.zip데이터를 확인해보자.
import os
fname = os.path.join("jena_climate_2009_2016.csv")
with open(fname) as f:
data = f.read()
lines = data.split("\n")
header = lines[0].split(",")
lines = lines[1:]
print(header)
print(len(lines))['"Date Time"', '"p (mbar)"', '"T (degC)"', '"Tpot (K)"', '"Tdew (degC)"', '"rh (%)"', '"VPmax (mbar)"', '"VPact (mbar)"', '"VPdef (mbar)"', '"sh (g/kg)"', '"H2OC (mmol/mol)"', '"rho (g/m**3)"', '"wv (m/s)"', '"max. wv (m/s)"', '"wd (deg)"']
420451출력된 줄 수는 42만 551줄이고 헤더는 위와 같이 출력된다.
데이터 변환부터 진행시켜보자. 온도를 하나의 배열로 만들고 나머지 데이터를 또 다른 배열로 만든다. 두 번째 배열이 미래 온도 예측을 위해 사용할 특성이다.
import numpy as np
temperature = np.zeros((len(lines),))
raw_data = np.zeros((len(lines), len(header) - 1))
for i, line in enumerate(lines):
values = [float(x) for x in line.split(",")[1:]]
temperature[i] = values[1] #두 번째 열을 temperature 배열에 저장한다.
raw_data[i, :] = values[:] #온도를 포함한 모든 열을 raw_data배열에 저장한다.처음 10일간의 온도를 그래프로 그려보면?
plt.plot(range(1440), temperature[:1440])
plt.show()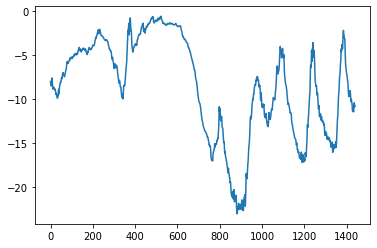
✋🏻 데이터에서 찾아봐야할 것은?
이와 같이 그래프를 통해 항상 데이터에서 주기성을 찾아야한다. 여러 시간 범위에 걸친 주기성은 시계열 데이터에서 매우 중요하고 일반적인 성질이다. 어디에서나 일별 주기와 연간 주기성을 확인할 수 있으므로, 데이터를 탐색할 때 이런 패턴을 찾아야한다.
이 데이터의 경우 연간 데이터 주기성은 안정적이기 때문에, 다음 달의 평균 온도를 예측하는 문제는 쉬운 편이다. 하지만 일자별 수준의 시계열 데이터 예측은 어떨까?
한번 도전해보자.
데이터 준비
주어진 문제 : 한 시간에 한번씩 샘플링된 5일간의 데이터가 주어졌을 때, 24시간 뒤의 온도를 예측할 수 있을까?
각 데이터(시계열)의 스케일이 각각 다르기 때문에, 평균과 표준편차를 계산하여 정규화를 시켜준다.
#평균과 표준편차 계산
mean = raw_data[:num_train_samples].mean(axis=0)
raw_data -= mean
std = raw_data[:num_train_samples].std(axis=0)
raw_data /= std과거 5일치 데이터와 24시간 뒤 타깃 온도의 배치를 반환하는 Dataset 객체를 만들어본다. 데이터셋에 있는 샘플은 중복이 많다. raw_data 와 temparature 배열만 메모리에 유지하고 그때 그때 샘플을 생성한다.
**이 때 파이썬 제너레이터를 사용하지 않고 케라스에 내장된 데이터셋 유틸리티(timeseries_dataset_from_array()) 를 사용해보자.
이를 사용해서 훈련, 검증, 테스트를 위해 3개의 데이터셋을 만들어보자.
매개변수는
sampling_rate = 6: 시간당 하나의 데이터 포인트가 샘플링된다.sequence_length = 120: 이전 5일간(120시간) 데이터를 사용한다.delay = sampling_rate * (sequence_length+24-1):시퀀스 타깃은 시퀀스 끝에서 24시간 후의 온도이다.
자, 이제는 훈련 데이터셋과 검증 데이터셋을 만들어보자.
sampling_rate = 6
sequence_length = 120
delay = sampling_rate * (sequence_length + 24 - 1)
batch_size = 256
train_dataset = keras.utils.timeseries_dataset_from_array(
raw_data[:-delay], #훈련 데이터셋 만들기
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=0,
end_index=num_train_samples)
val_dataset = keras.utils.timeseries_dataset_from_array(
raw_data[:-delay], #검증 데이터셋 만들기
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=num_train_samples,
end_index=num_train_samples + num_val_samples)
test_dataset = keras.utils.timeseries_dataset_from_array(
raw_data[:-delay], #테스트 데이터셋 만들기
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=num_train_samples + num_val_samples)각 데이터셋은 (samples, targets) 크기의 튜플을 반환한다. 각 샘플은 연속된 120 시간의 입력 데이터를 담고, targets는 256개의 타깃 온도에 해당하는 배열이다.
상식 수준의 기준점 잡기
이 문제의 시계열 데이터의 경우 연속성이 있고 일자별로 주기성을 가진다고 가정할 수 있다. 그렇기 때문에 상식 수준의 해결책은 지금으로부터 24시간 후 온도는 지금과 동일하다고 예측해야한다. 이를 점검하기 위해 상식 수준 모델의 MAE를 계산해보자.
def evaluate_naive_method(dataset):
total_abs_err = 0.
samples_seen = 0
for samples, targets in dataset:
preds = samples[:, -1, 1] * std[1] + mean[1]
#특성을 정규화하였기 때문에 온도를 섭씨로 바꾸려면 표준 편차를 곱하고 평균을 더해야한다.
total_abs_err += np.sum(np.abs(preds - targets))
samples_seen += samples.shape[0]
return total_abs_err / samples_seen
print(f"검증 MAE: {evaluate_naive_method(val_dataset):.2f}")
print(f"테스트 MAE: {evaluate_naive_method(test_dataset):.2f}")검증 MAE: 2.44
테스트 MAE: 2.62상식 수준의 모델은 24시간 후 온도를 항상 현재와 같다고 예측하면 평균적으로 2.5도 정도 차이가 난다. 나쁘지는 않지만 딥러닝 모델이 더 나은지 확인해야한다.
기본적인 머신 러닝 모델 시도해보기
데이터를 펼쳐서 2개의 Dense 층을 통과시키는 완전 연결 네트워크를 보여준다. 즉, 밀집 연결 모델을 훈련하고 평가해보자.
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.Flatten()(inputs) #평탄화 진행
x = layers.Dense(16, activation="relu")(x) #밀집 연결 신경망
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_dense.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_dense.keras")
print(f"테스트 MAE: {model.evaluate(test_dataset)[1]:.2f}")훈련과 검증 손실 곡선을 그려보면,
import matplotlib.pyplot as plt
loss = history.history["mae"]
val_loss = history.history["val_mae"]
epochs = range(1, len(loss) + 1)
plt.figure()
plt.plot(epochs, loss, "bo", label="Training MAE")
plt.plot(epochs, val_loss, "b", label="Validation MAE")
plt.title("Training and validation MAE")
plt.legend()
plt.show()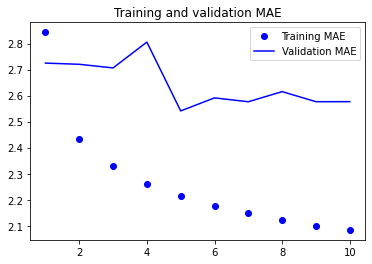
일부 검증 손실은 학습을 사용하지 않은 기준점에 가깝지만 안정적이지 못하다. 이러한 결과가 나온 이유는,
문제 해결을 위해 탐색하는 모델의 공간, 즉 가설 공간은 우리가 매개변수로 설정한 2개의 층을 가진 네트워크의 모든 가능한 가중치 조합이다. 상식 수준의 모델을 이 공간에서 표현할 수 있는 수백만 가지 중 하나일 뿐 ! 이것이 머신 러닝의 가장 심각한 제약 사항이다. 특정 종류의 간단한 모델을 찾도록 학습 알고리즘을 하드코딩하지 않는다면, 간략한 해결책을 찾기 어렵다.
따라서 특성 공학과 문제와 관련된 아키텍처 구조를 활용하는 것이 중요한 이유이다. 모델이 찾아야 할 것을 정확히 알려줘야하기 때문이다.
1D 합성곱 모델 시도해보기
입력 시퀀스가 일별 주기를 가지기 때문에 합성곱 모델을 적용할 수 있다. 시간 축에 대한 합성곱을 다른 날에 있는 동일한 표현을 재사용할 수 있기 때문이다. 2D컨브넷과 매우 유사한 1D컨브넷을 만들어 초기 윈도우 길이를 24로 정하고, 24시간의 데이터를 보도록 구성해보자.
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.Conv1D(8, 24, activation="relu")(inputs)
x = layers.MaxPooling1D(2)(x)
x = layers.Conv1D(8, 12, activation="relu")(x)
x = layers.MaxPooling1D(2)(x)
x = layers.Conv1D(8, 6, activation="relu")(x)
x = layers.GlobalAveragePooling1D()(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_conv.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_conv.keras")
print(f"테스트 MAE: {model.evaluate(test_dataset)[1]:.2f}")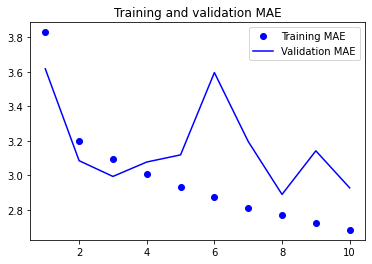
이런 , 밀집 연결 모델 보다 성능이 더 나쁘다. 이유를 생각해보면,
- 날씨 데이터는 평행 이동 불변성 가정을 많이 따르지 않는다. 데이터에 일별 주기성이 있지만 아침 데이터는 저녁이나 한밤중의 데이터와 성질이 다르기 때문이다. 날씨 데이터는 매우 특정한 시간 범위에 대해서만 평행 이동 불변성을 가진다.
- 이 데이터는 순서가 매우 중요하다. 최근 데이터가 5일 전 데이터보다 내일 온도를 예측하는데 훨씬 더 유리하다. 1D 컨브넷은 이런 사실들을 활용할 수 없었다.
첫 번째 순환 신경망
밀집 연결 모델이나 합성곱 모델의 경우, 시계열 데이터를 펼쳤기 때문에 입력 데이터에서 시간 개념을 잃어버렸다. 합성곱 모델은 모든 부분을 비슷한 방식으로 처리하였기 때문에 풀링을 적용할 때 순서 정보를 잃어버리게 된다.
이런 방법 때신 인과 관계와 순서가 의미 있는 시퀀스 데이터를 그대로 사용해보자.
이를 위해 고안된 신경망 구조가 순환 신경망이다. 그 중에서 LSTM(Long-Short-Term-Memory) 층이 오랫동안 인기가 많았다. 적용해보자.
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.LSTM(16)(inputs)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_lstm.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_lstm.keras")
print(f"테스트 MAE: {model.evaluate(test_dataset)[1]:.2f}")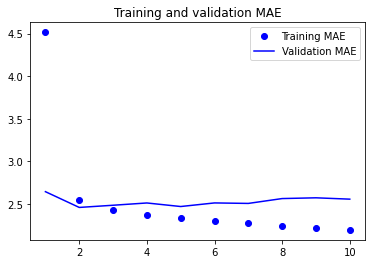
가장 좋은 결과를 보여준다. 가장 낮은 검증 MAE는 2.36도, 테스트 MAE는 2.55도를 달성하였다.
