
컨볼루션을 활용한 일반화
8장에서는...
- 컨볼루션을 이해한다.
- 컨볼루션 신경망을 만들고, 커스텀 nn.Module 서브클래스를 만들어본다.
- 모듈과 함수형 API의 차이에 대해 인지한다.
- 신경망 설계시 고려할 점도 살펴보자 !
컨볼루션이란?
컨볼루션은 평행이동 불변성을 해결할 수 있다. (평행이동 불변성 : 지역화된 패턴이 이미지의 어떤 위치에 있더라도 동일하게 출력에 영향을 주는 성질 )
이산 convolution 이란?
2차원 이미지에 가중치 행렬을 스칼라곱으로 수행하는 것으로 정의한다.
가중치 행렬은 커널(kernel) 이라 부르며, 입력의 모든 이웃에 대해 수행한다.
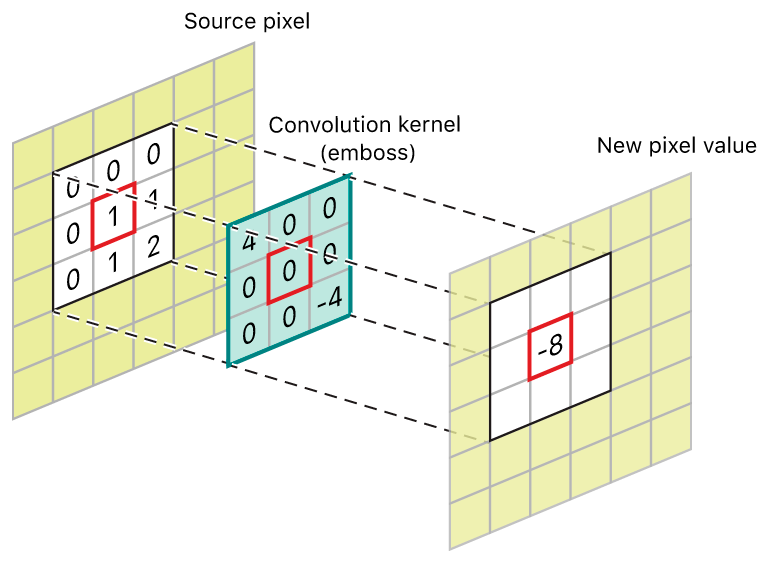
- 커널은 평행이동하며 이동한 위치의 입력 이미지 값과 가중치를 곱한다. 이런 방식으로 입력의 모든 위치에 대해 커널을 이동시켜 가며 가중치의 합을 구해 출력 이미지를 생성한다.
-
RGB 이미지처럼 channel이 여러개인 경우 가중치 행렬은 3 3 3 행렬로 각 채널에 대한 가중치 집합이 존재하며, 이를 합쳐서 계산을 진행한다.
-
커널의 가중치는 미리 알 수 없으며, 랜덤으로 초기화되고 역전파를 통해 업데이트된다. 동일한 커널의 각 가중치가 전체 이미지에 대해 계속 사용된다 !
-
컨볼루션을 사용하게 되면, 주위 영역에 대한 지역 연산을 할 수 있으며, 평행이동의 불변성을 가지고, 더 적은 parameter를 사용할 수 있다.
-
Conv1d : 시계열용, Conv2d : 이미지용, Conv3d : 용적 데이터나 영상용
컨볼루션의 활용
컨볼루션을 만들기 전, 커널부터 정의해보자 !
커널의 크기는 일반적으로 w, h 가 같으며, 홀수 값으로 정의한다.
conv = nn.Conv2d(3, 16, kernel_size=3)
conv
#results
Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1))하나의 입력 이미지로 conv 모듈 호출 시 nn.Conv2d는 입력으로 B X C X H X W 를 받으므로 0번째 차원을 unsqueeze를 통해 배치 차원으로 사용한다.
img, _ = cifar2[0]
output = conv(img.unsqueeze(0))
img.unsqueeze(0).shape, output.shape
#results
(torch.Size([1, 3, 32, 32]), torch.Size([1, 16, 30, 30]))
#뒤의 output.shape는 전체 가중치 텐서값. out_ch * in_ch * 3 * 3이미지를 다룰 때, 출력 이미지가 입력 이미지보다 작은 것은 이미지의 경계에서 이뤄지는 작업에 따른 부작용이라고 볼 수 있다.
3 X 3 이웃 영역에 대해 conv kernel을 가중치합으로 적용하려면 모든 방향의 값이 존재한다는 가정이 필요하다.
이 가정을 충족시키기 위하여 출력이미지와 입력이미지의 크기를 동일하게 해야하는데, 작은 입력이미지의 크기를 키우는, 이미지의 경계의 값이 0인 픽셀을 채워주는 padding 을 진행해야한다.
conv = nn.Conv2d(3, 1, kernel_size=3, padding=1) # <1>
output = conv(img.unsqueeze(0))
img.unsqueeze(0).shape, output.shape
#results
(torch.Size([1, 3, 32, 32]), torch.Size([1, 1, 32, 32]))이미지 사이즈가 커져버린다면 ?
지금까지는 컨볼루션을 활용하여 지역성이나 평행이동 불변성을 해결했다. 지금까지는 작은 size의 커널을 사용하였는데, 이는 지역성으로 인해 작아졌기 때문인데, 이미지가 커질 경우 이미지안의 물체나 크기가 3~5 사이즈 내로 다루지 못하는 경우가 존재한다 !
이러한 경우에 대해서 이미지를 다운 샘플링 한다 !
다운 샘플링 : 이미지를 반으로 줄이는 과정이다. 이웃하는 네 개의 픽셀을 입력받아 한 픽셀의 출력을 진행한다.
- 4개의 픽셀 평균하기 :
average pooling을 진행한다. - 4개의 픽셀 중 최댓값 사용 :
Max pooling이라고 부른다. 오늘날 가장 널리 사용하나, 데이터의 3/4를 버리기 때문에 보완하는 방식이 차후에 많이 설계되고있다. - stride 하며 conv를 수행하되 n번째 픽셀만 계산하기
nn.Module 서브 클래싱 진행하기
우리가 신경망을 항상 있는 그대로 가져오는 것은 아니다 ! 따로 커스텀하여 만들어서 다룰 줄 알아야한다. 여기서 nn.Module을 활용하여 직접 신경망을 커스텀하는 방법을 진행해보자.
그러나, 우리가 만들 연산도 결국 컨볼루션과 같은 이미 있는 모듈이나 커스텀 모듈을 사용하기 때문에 이러한 submodule 을 포함하려면 생성자 __init__ 에 정의하고 self에 할당하여 forward 함수에서 사용할 수 있게 만들어야한다.
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.act1 = nn.Tanh()
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(16, 8, kernel_size=3, padding=1)
self.act2 = nn.Tanh()
self.pool2 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(8 * 8 * 8, 32)
self.act3 = nn.Tanh()
self.fc2 = nn.Linear(32, 2)
def forward(self, x):
out = self.pool1(self.act1(self.conv1(x)))
out = self.pool2(self.act2(self.conv2(out)))
out = out.view(-1, 8 * 8 * 8) # <1>
out = self.act3(self.fc1(out))
out = self.fc2(out)
return out분류 신경망의 목적은 두가지로 설명할 수 있다.
- 중간에 나타나는 값의 개수가 점점 줄어드는 모습에 우리가 목표하는 바인 정보 축소 압축을 담을 수 있다.
- 최초의 컨볼루션에서는 입력 크기에 대해 출력 크기가 줄어들지 않는다는 점이다.
nn.Module의 속성에 인스턴스를 할당하게 되면, 모듈이 서브모듈로 등록된다.
이리하여 nn.Module 서브클래스의 method 라면 언제든 인스턴스 호출이 가능해졌다!
model = Net()
numel_list = [p.numel() for p in model.parameters()]
sum(numel_list), numel_list
#추가 행위 없이 서브모듈의 파라미터에 접근가능하다 !함수형 API
언제든 호출 가능한 것에 대한 이유는 존재한다. 파이토치에서는 nn.Module에 대한 모든 함수형 API를 제공한다. 이에 따라서 언제든지 호출이 가능해 진 것이다.
함수형 API : Functional API는 각 층을 일종의 함수(function)로서 정의한다. 또한 각 함수를 조합하기 위한 연산자들을 제공하는데, 이를 이용하여 신경망을 설계한다. Functional API로 FFNN, RNN 등 다양한 모델을 만들면서 기존의 sequential API와의 차이점을 파악할 수 있다.
컨볼루션 신경망을 훈련시켜보자 !
책에서 작성한 컨볼루션 신경망은 중첩된 두 루프를 가지고 있다. 겉 루프는 epoch 단위로, 안 루프틑 Dataloader 단위로 돌고있다.
- 모델에 입력값을 넣어 forward로 진행한다. 과정 중
loss를 계산한다. - 이전이 기울기값을 0으로 지정한다.
loss.backward()를 통해 모든 parameter에 대한 loss 기울기를 계산하며 backpropagation을 진행한다.optimizer를 통해 loss를 낮추도록 파라미터를 조정하고 계속해서 반복한다.
코드는 다음과 같다 !
import datetime
def training_loop(n_epochs, optimizer, model, loss_fn, train_loader):
for epoch in range(1, n_epochs + 1):
loss_train = 0.0
for imgs, labels in train_loader:
outputs = model(imgs)
loss = loss_fn(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_train += loss.item()
if epoch == 1 or epoch % 10 == 0:
print('{} Epoch {}, Training loss {}'.format(
datetime.datetime.now(), epoch,
loss_train / len(train_loader)))
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=64,
shuffle=True)
model = Net()
optimizer = optim.SGD(model.parameters(), lr=1e-2)
loss_fn = nn.CrossEntropyLoss()
training_loop(
n_epochs = 100,
optimizer = optimizer,
model = model,
loss_fn = loss_fn,
train_loader = train_loader,
)이로써 conv net을 활용하여 모델 작성부터, 훈련까지 진행하는 과정을 확인해보았다.
이제는 모델 구현 꿀팁들을 알아가보자 !!
모델 설계 꿀팁들
지금까지는 아주 간단한 데이터셋들로 간단한 모델들을 짜보는 과정을 거쳐봤다. 앞으로의 과제에서 복잡한 이미지에서 답을 찾기 위하여 시각적 단서를 찾기 위한 계층적 구조화 가 필요하기에, 이에 관련된 교재에서 언급하는 꿀팁 내용들을 간략하게 정리해보았다.
메모리 용량 늘려보기 (너비)
feedforward architecture 중 신경망의 너비(width) 차원을 늘리는 방법이 있다.
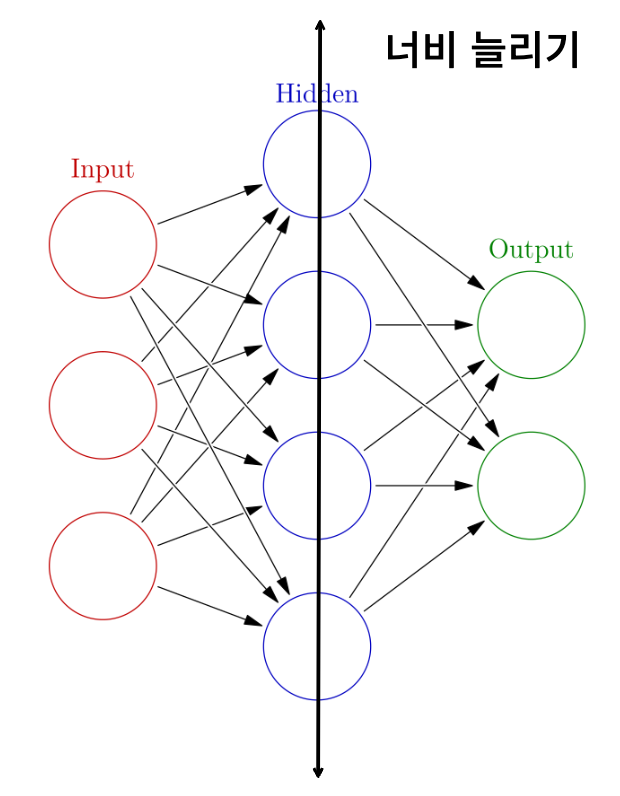
방법은 간단하다 ! 첫번째 컨볼루션의 출력 채널 수를 늘리고 이어지는 계층도 이에 맞춰서 키워주면 더 길어진 벡터를 가져 완전 연결 계층으로 전환되는 forward 함수에도 적용이된다.
장점 : 용량이 클수록 모델이 다룰 수 있는 입력은 더 다양해지기 때문에, 다룰 수 있는 input 이 늘어난다는 장점이 있다.
단점 : 동시에 과적합의 가능성이 존재한다. (파라미터가 많아져 입력에서 불필요한 부분까지 기억할 수 있기 때문 !
모델의 수렴화 돕기 : 정규화
모델 훈련에서 두가지 단계를 거치는데 하나는 최적화 단계 로써, 훈련셋에 대해 loss 값을 줄이는 경우이며, 다른 하나는 일반화 단계 로써 모델이 훈련셋 뿐만 아니라 이전에 겪어보지 못한 검증셋 같은 데이터에 대해서도 동작하게 하는 것이다.
이 두가지는 한꺼번에 진행시켜주는 과정을 정규화(regularization) 라고 한다.
- 일반화 안정적으로 수행하기 : 가중치 패널티를 주자 !
loss 값에 정규화 항을 넣으면, 모델의 가중치가 상대적으로 작아진다.
이는 훈련을 통해 증가할 수 있는 크기를 제한하는 것으로, loss 값이 매끄러운 선형 형태를 띌 수 있게 된다. 가장 유명한 정규화 항으로는 L2 regularization 과 L1 regularization이다.
L1 normalization의 식은
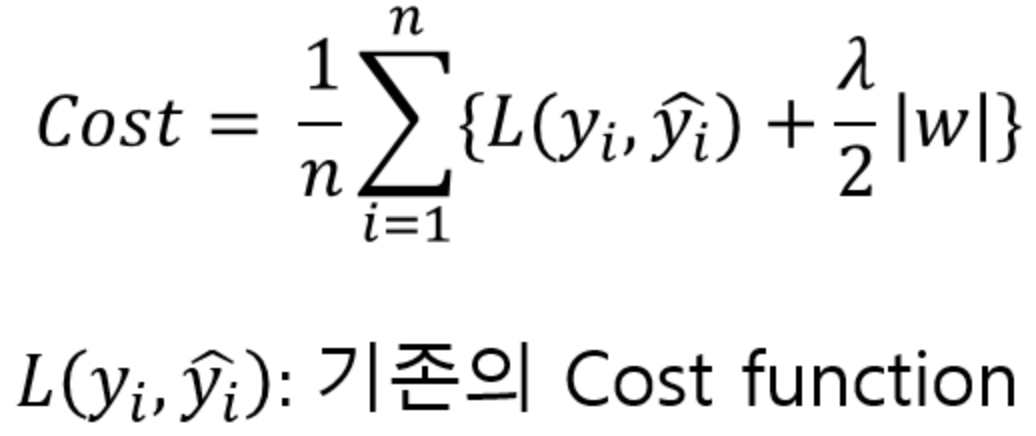
L1 Normalization 은 loss function에 가중치의 절대값을 더해준다.
L2 normalization 의 식은

L2 Normalization 은 loss function에 가중치의 제곱을 포함하여 가중치가 너무 크지 않은 방향으로 학습된다.
특히 L2 normalization 의 경우, 가중치 감쇠 작업이라고도 하는데, 이는 최적화 돤계에서 현제 값에 비례하여 각 가중치를 줄이는 역할을 한다. 가중치 감쇠는 편향값과 같은 신경망의 모든 파라미터에 적용되는 특징을 지니기에, 보편적으로 사용되고 있다.
정규화가 진행된 코드를 살펴보자.
def training_loop_l2reg(n_epochs, optimizer, model, loss_fn,
train_loader):
for epoch in range(1, n_epochs + 1):
loss_train = 0.0
for imgs, labels in train_loader:
imgs = imgs.to(device=device)
labels = labels.to(device=device)
outputs = model(imgs)
loss = loss_fn(outputs, labels)
l2_lambda = 0.001
l2_norm = sum(p.pow(2.0).sum()
for p in model.parameters())
loss = loss + l2_lambda * l2_norm
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_train += loss.item()
if epoch == 1 or epoch % 10 == 0:
print('{} Epoch {}, Training loss {}'.format(
datetime.datetime.now(), epoch,
loss_train / len(train_loader)))
-
과적합 극복하기 : Dropout 사용하기 !
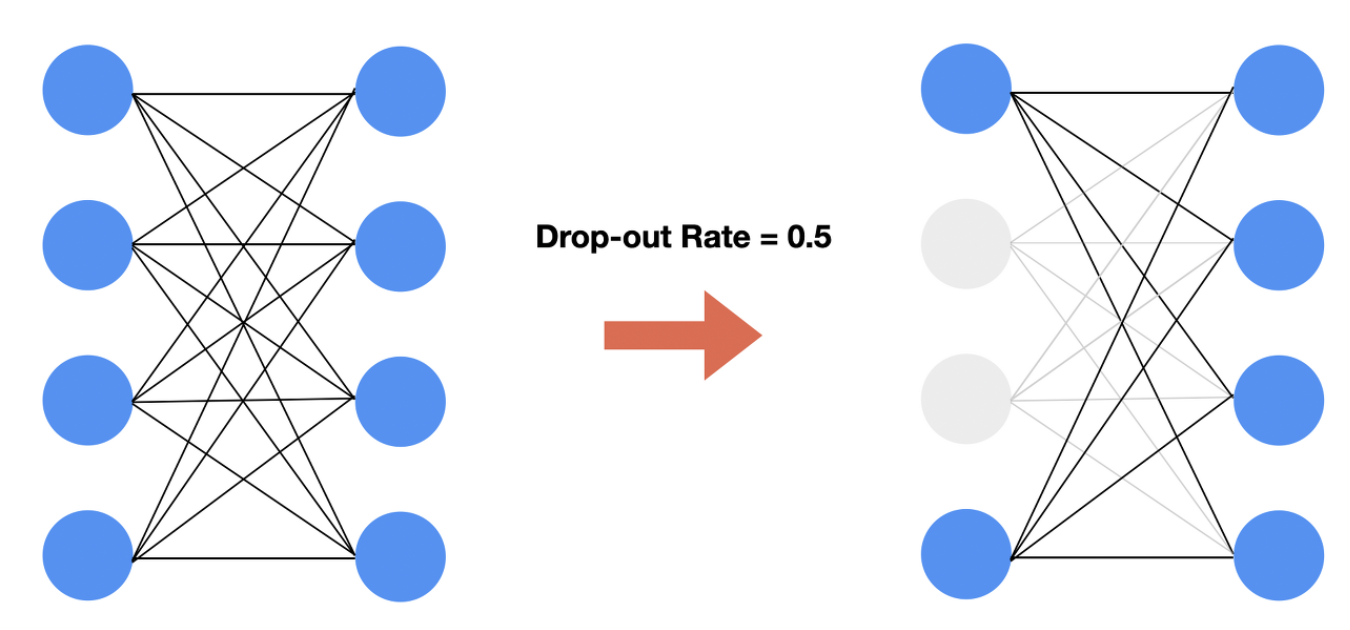
Dropout은 서로 연결된 연결망(layer)에서 0부터 1 사이의 확률로 뉴런을 제거(drop)하는 기법이다.Dropout은 어떤 특정한 feature만을 과도하게 집중하여 학습함으로써 발생할 수 있는과대적합(Overfitting)을 방지하기 위해 사용된다. -
활성 함수 억제하기 : 배치 정규화 해보기 !
일단 간단하게 용어 정리부터 해보면, 학습 데이터 전체를 한번 학습하는 것을Epoch라고 하고 Gradient를 구하는 단위를Batch라고 한다.
Batch 단위로 학습을 하게 되면 발생하는문제점이 발생하는데, 학습 과정에서 계층 별로 입력의 데이터 분포가 달라지는 현상이 나타난다는 것이다.
각 계층에서 입력으로 feature를 받게 되고 그 feature는 convolution이나 위와 같이 fully connected 연산을 거친 뒤 activation function을 적용하며, 이 과정에서 연산 전/후에 데이터 간 분포가 달라질 수 있다. 이와 유사하게Batch 단위로 학습을 하게 되면 Batch 단위간에 데이터 분포의 차이가 발생하며, 이를 해결하기 위하여 배치 정규화를 진행하게 된다.
자세한 내용을 영상으로 보고싶다면 이영상을 보면 좋다 !!
Batch normalization은 학습 과정에서 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도 각 배치별로 평균과 분산을 이용해 정규화하는 것을 말한다.
class NetBatchNorm(nn.Module):
def __init__(self, n_chans1=32):
super().__init__()
self.n_chans1 = n_chans1
self.conv1 = nn.Conv2d(3, n_chans1, kernel_size=3, padding=1)
self.conv1_batchnorm = nn.BatchNorm2d(num_features=n_chans1)
self.conv2 = nn.Conv2d(n_chans1, n_chans1 // 2, kernel_size=3,
padding=1)
self.conv2_batchnorm = nn.BatchNorm2d(num_features=n_chans1 // 2)
self.fc1 = nn.Linear(8 * 8 * n_chans1 // 2, 32)
self.fc2 = nn.Linear(32, 2)
def forward(self, x):
out = self.conv1_batchnorm(self.conv1(x))
out = F.max_pool2d(torch.tanh(out), 2)
out = self.conv2_batchnorm(self.conv2(out))
out = F.max_pool2d(torch.tanh(out), 2)
out = out.view(-1, 8 * 8 * self.n_chans1 // 2)
out = torch.tanh(self.fc1(out))
out = self.fc2(out)
return out- 깊이 파헤치기 : 스킵 커넥션 을 사용해보자 !
VGGNet 에서 처음 사용된 Skip connection이란 무엇일까?
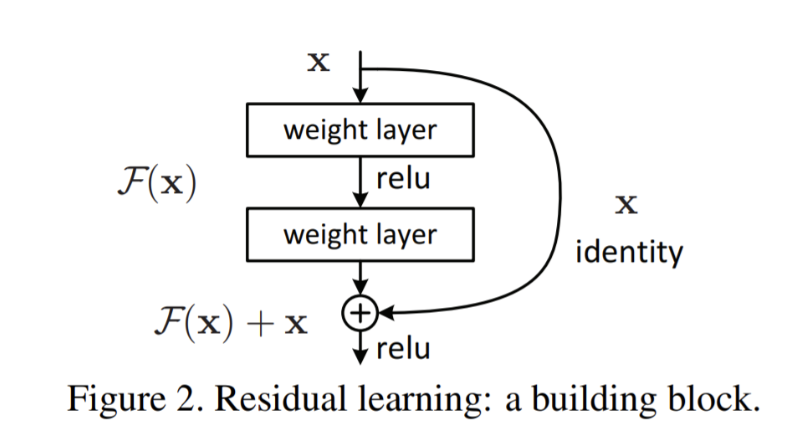
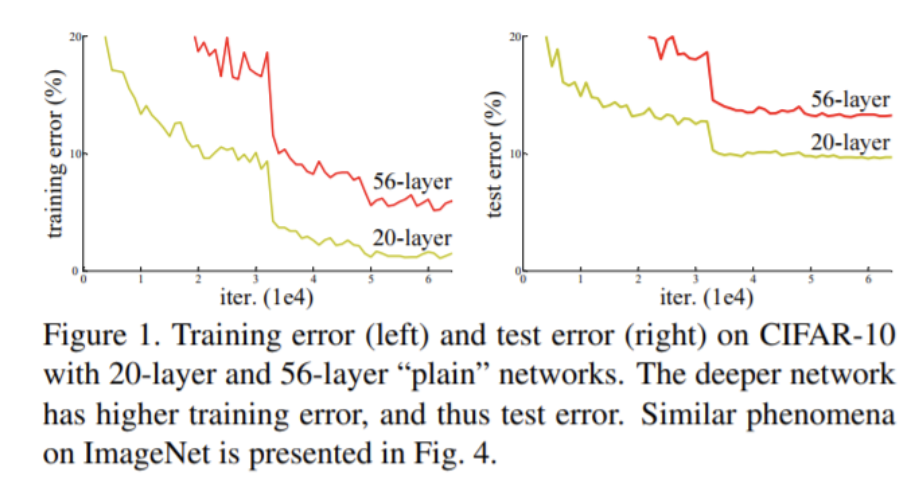
VGG와 같은 architecture를 설계할 때 깊을수록 더 나은 성능을 보인다. 하지만 깊이가 너무 정도 깊어진다면 오히려 성능이 하락하는 결과가 나타난다.
이는 input 정보가 여러 층을 거치면서 이전 층에 대한 정보 손실이 발생할 수 있으며, 따라서 가중치가 잘못된 방향으로 갱신되는 문제 때문인데, 이를 해결하기 위하여스킵 커넥션을 이용하게 되었다.
스킵커넥션이란, 입력을 계층 블럭의 출력에 연결하는 것으로서, input값 x를 target값 y로 매핑(mapping)하는 함수 H(x)를 구하는 과정에서 y를 x의 대변으로 보고 H(x)-x를 찾아 나가는 과정을 학습하는 것이다. 목표하고자 하는 바가 정해져 있게 됨으로써, 갱신될 때 길을 잃지 않고 나아갈 수 있다는 이점을 지니고 있다.
스킵 커넥션을 사용한 코드는 다음과 같다.
class NetRes(nn.Module):
def __init__(self, n_chans1=32):
super().__init__()
self.n_chans1 = n_chans1
self.conv1 = nn.Conv2d(3, n_chans1, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(n_chans1, n_chans1 // 2, kernel_size=3,
padding=1)
self.conv3 = nn.Conv2d(n_chans1 // 2, n_chans1 // 2,
kernel_size=3, padding=1)
self.fc1 = nn.Linear(4 * 4 * n_chans1 // 2, 32)
self.fc2 = nn.Linear(32, 2)
def forward(self, x):
out = F.max_pool2d(torch.relu(self.conv1(x)), 2)
out = F.max_pool2d(torch.relu(self.conv2(out)), 2)
out1 = out
out = F.max_pool2d(torch.relu(self.conv3(out)) + out1, 2)
out = out.view(-1, 4 * 4 * self.n_chans1 // 2)
out = torch.relu(self.fc1(out))
out = self.fc2(out)
return out이로써 기본적인 툴과 모델들 방식을 다루는 8장이 끝이났다. 9장부터는 실전 이미지 학습을 통해서 더 디테일한 모델들을 만들고, 다양한 개념들을 학습해보도록 하자 !
