Multi-Head Attention은 Scaled Dot-Product Attention의 연산을 사용하되 여러 개의 head를 사용하는 방법이다. Transformer의 Encoder, Decoder의 핵심이 되는 Layer이기 때문에 기존의 attention과 어떻게 다른지 알아본다.
Multi-head Attention은 어떻게 생겼나?
** h : head의 개수
d_model: 모델의 임베딩 벡터 차원 수
논문에서 h=8, d_model = 512
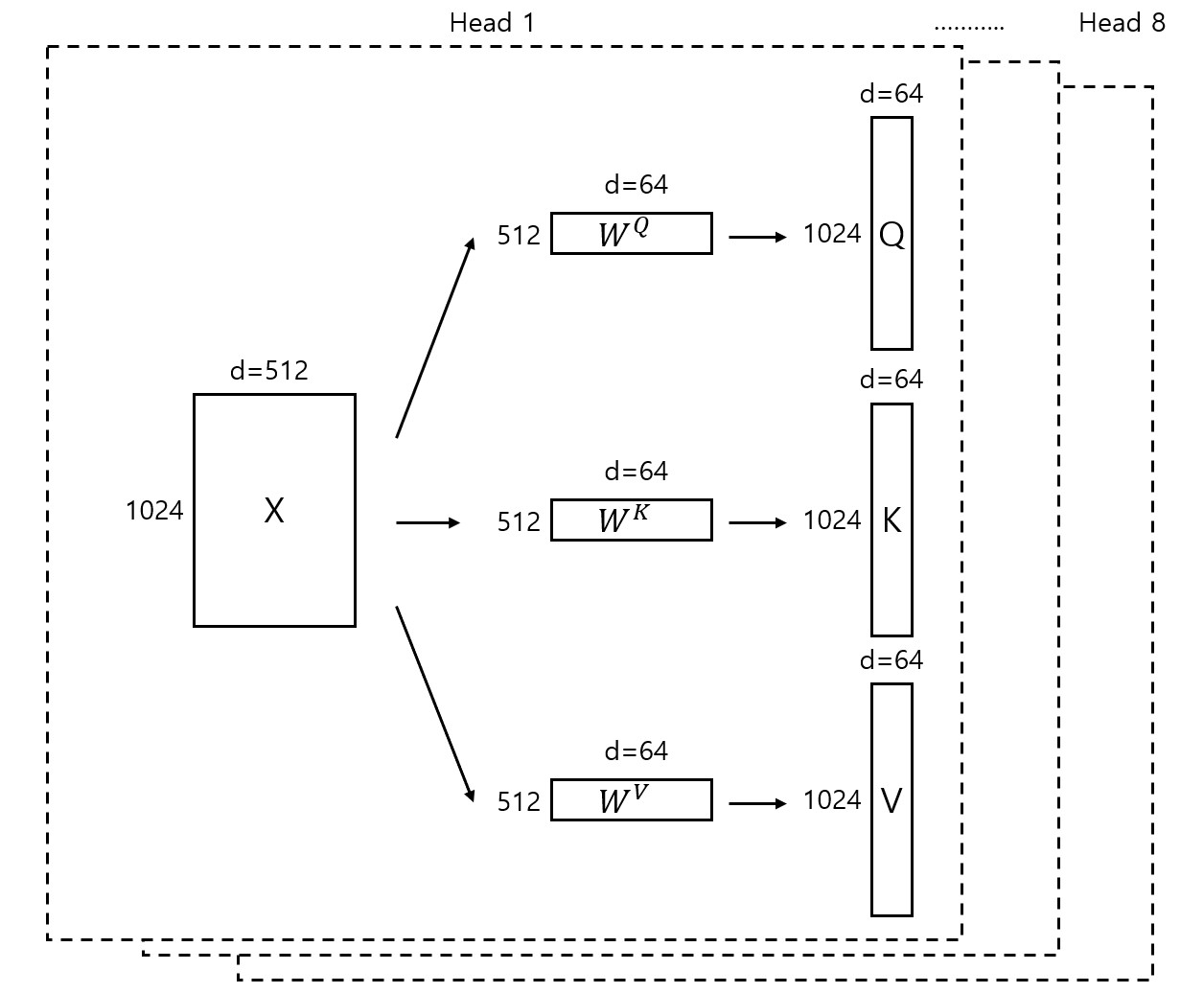
간략하게 설명하면 Multi-Head Attention은 head라고 명명한 여러 subspace에서 scaled dot- product attention 연산을 병렬로 수행하고, head를 concat한 후 가중치 벡터(W)를 통해 선형 변환을 하는 방식이다. 이 때 각 head 내의 Key, Query, Vector의 차원은 (d_model/h) 차원이고, 이에 따라 attention에 대한 결과 벡터도 (d_model/h) 차원이 된다. 각 head에서의 결과에 대한 concatenation에 가중치 벡터를 선형 결합함으로써 기존의 input vector shape과 동일한 결과 벡터를 생성할 수 있게 된다.
Head를 여러개로 나누는 이유가 뭘까?
Multi-head attention allows the model to jointly attend to information from different rerpesentation subspaces at different positions.
논문에선 Multi-Head Attention을 통해 모델이 서로 다른 위치 subspace로부터 오는 정보를 처리할 수 있다라고 설명되어 있다. 이 말이 Multi-Head Attention의 이유이자 핵심인 것 같다. 하나의 input vector가 아닌, n개의 서로 다른 subspace에서 attention을 진행함으로써 앙상블 모델을 사용하는 것과 같이 다양한 representation을 학습할 수 있을 것이다.
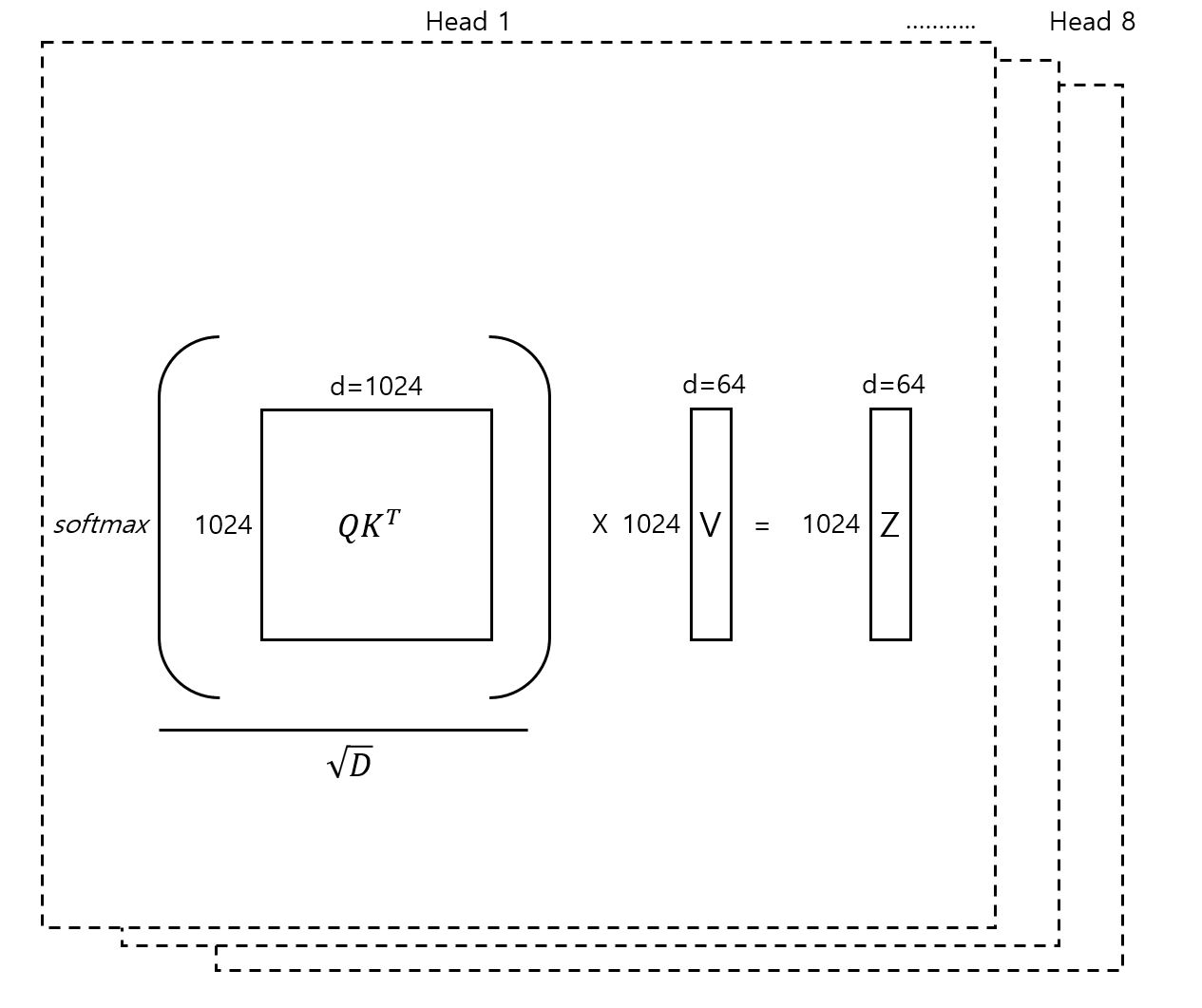
각 head에선 차원의 수가 작아졌을 뿐, 동일한 scaled dot-product attention이 적용되며 이 작업은 병렬로 처리된다. 논문에선 각 head의 차원이 축소됨에 따라 single-head attention과 크게 computational cost 차이가 나지 않는다는 것 또한 강조한다.
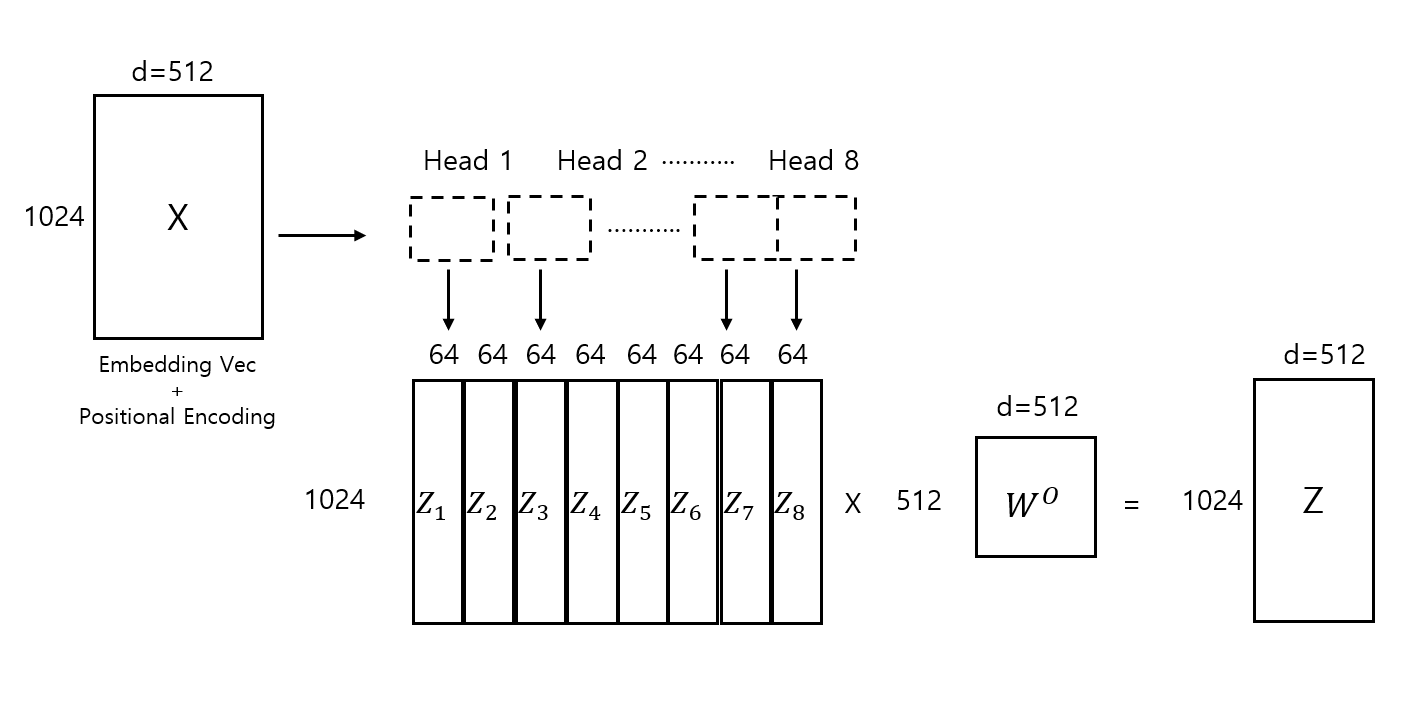
서로 다른 subspace에서 attention을 적용한 결과인 각 head의 output vector에 대해 concatenation을 진행하고 선형변환을 하여 최종 output vector는 input vector와 동일한 shape을 갖게 된다.
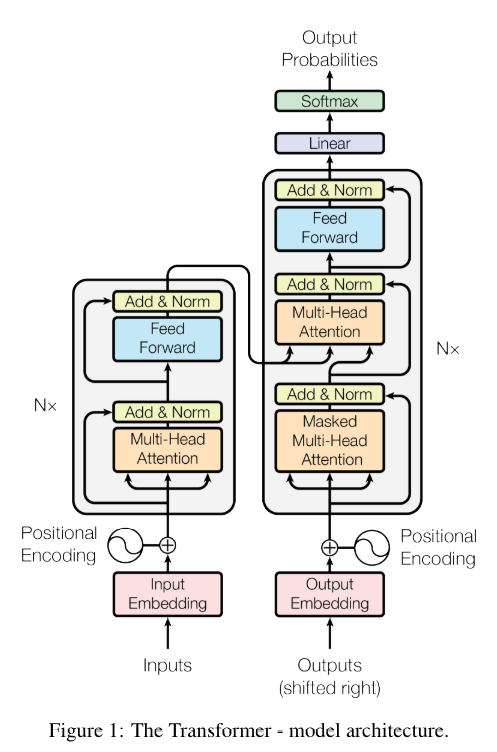
Transformer 아키텍처 안에서 Multi-head attention은 Encoder, Decoder에서 3가지 형태로 사용된다. 3가지 형태의 차이점은 간단하게 요약하면 아래와 같다.
- Encoder의 Multi-Head Attention
k,q,v 벡터가 모두 Input Embedding 벡터로부터 생성된다. - Decoder의 Masked Multi-Head Attention
k,q,v 벡터가 모두 Output Embedding 벡터로부터 생성되며 Attention에 Masking이 적용된다. - Decoder의 Multi-Head Attention
q,k vector는 Encoder Stack으로부터, v 벡터는 Decoder Stack으로부터 생성된다.
다음 글에서는 Masked Multi-Head Attention과 Encoder, Decoder로 이어지는 모델 전체 흐름에 대해 적어보려 한다.
참고 글
Self-attention과 multi-head self attention의 차원 변화에 대한 연산 과정, 의미를 상세하게 설명해주셔서 많은 도움이 됐다. 글의 뒤쪽에 positional encoding, masked attention에 대한 설명도 있다.
민경님의 블로그 글
간략한 예시와 함께 이해하기 쉽게 글을 풀어 써주셨다.
Transformer 논문
"Attention Is All You Need", 다른 설명을 한번 보고 읽으니 이해하기 훨씬 수월했다.
