NLP
1.[Transformer] Positional Encoding 구현 Deep dive

Positional Encoding 개념을 이해하고 code implementation을 보던 중 논문과 구현 방법이 달라 찾아보았다.기존의 수식에는 없던 로그 함수와 지수함수가 들어간다.. 이해가 안돼서 찾아봤는데 positional encoding 구현 설명, 이
2024년 5월 17일
2.[Transformer] Positional Encoding 이론 Deep Dive
Positional Encoding에 대한 이론적인 내용을 공부하여 요약하였다.Positional Encoding은 transformer 모델의 앞단에서 Input Embedding 값에 더해진다. 이런 encoding 값이 필요한 이유는 각 representation
2024년 5월 17일
3.Scaled Dot-Product Attention 이론 deep dive
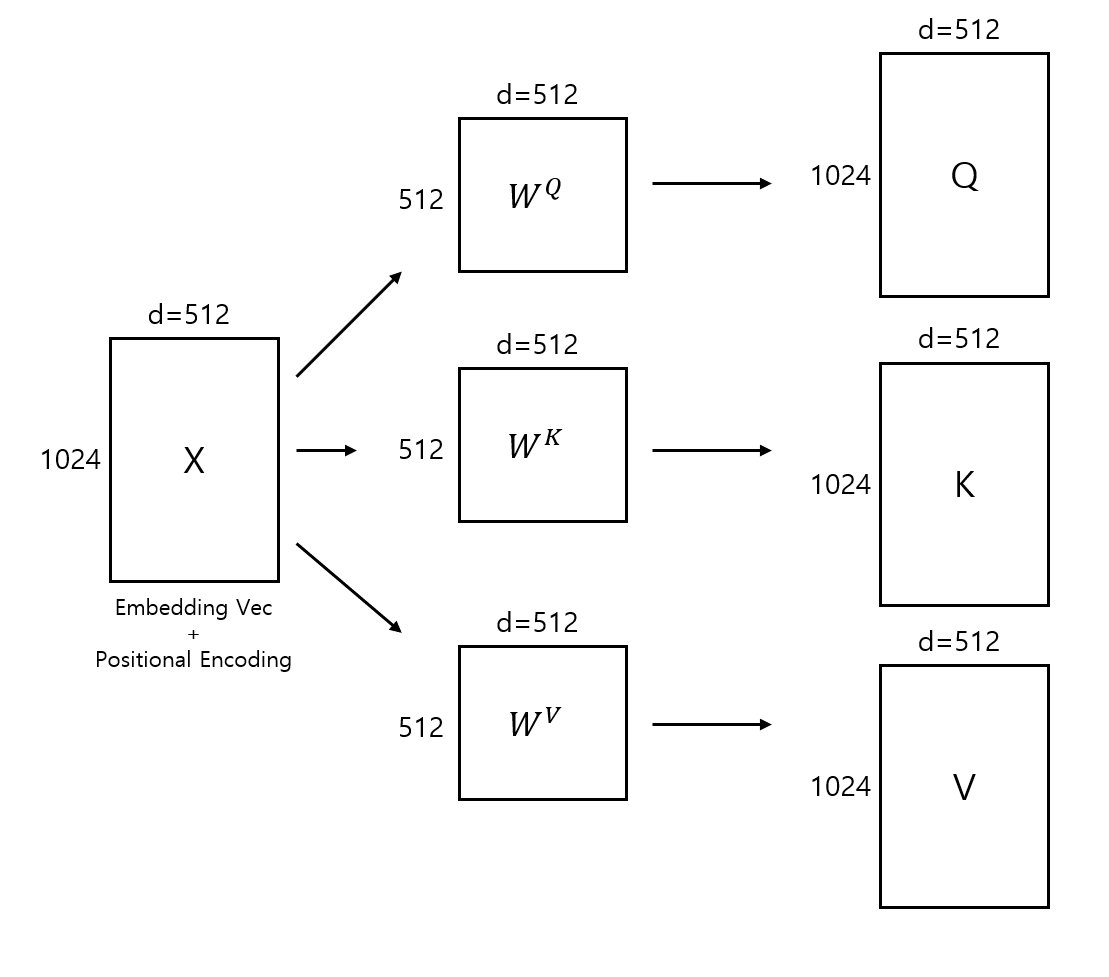
"Attention is All you need"이란 논문 이름에 걸맞게 transformer 논문은 기존에 \*\*sequence transduction 모델에서 부분적으로 사용하던 attention 알고리즘을 모델 전반에 적용하는 방안을 처음으로 도입했다. Scal
2024년 5월 22일
4.Multi-Head Attention 이론 deep dive
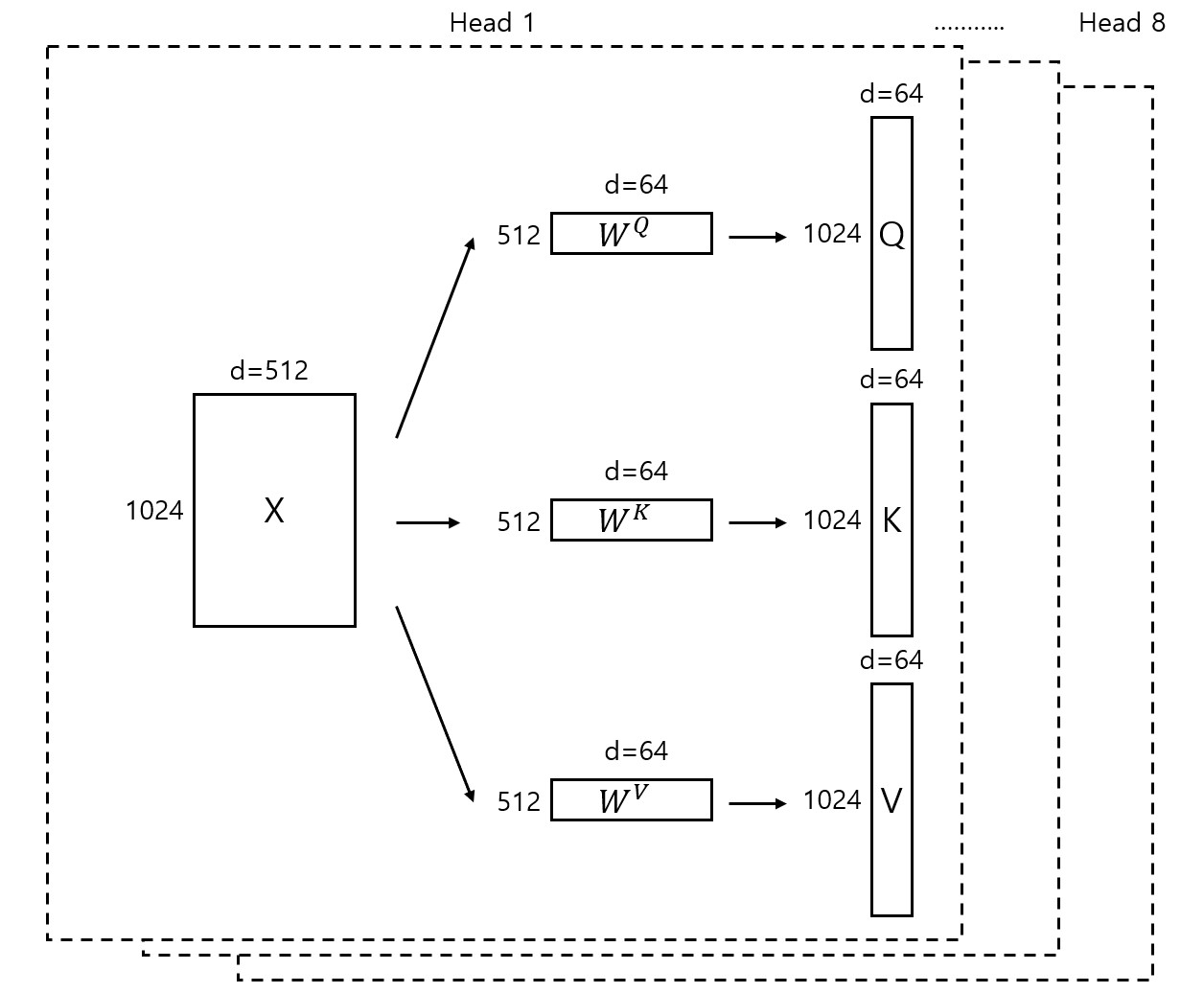
Multi-Head Attention은 Scaled Dot-Product Attention의 연산을 사용하되 여러 개의 head를 사용하는 방법이다. Transformer의 Encoder, Decoder의 핵심이 되는 Layer이기 때문에 기존의 attention과 어
2024년 5월 23일