"Attention is All you need"이란 논문 이름에 걸맞게 transformer 논문은 기존에 **sequence transduction 모델에서 부분적으로 사용하던 attention 알고리즘을 모델 전반에 적용하는 방안을 처음으로 도입했다. Scaled Dot-product Attention이 어떤 방식으로 쓰였는지 자세히 알아보려 한다.
**sequence transduction model - input sequence를 입력했을 때 다른 형태의 output sequence가 출력되는 모델
Scaled Dot-Product Attention은 무슨 의미일까?
** Q: Query 벡터
** K: Key 벡터
** V: Value 벡터
** d_k: Key 벡터의 차원 수
"Scaled Dot-Product Attention"는 입력된 토큰 간의 관계(유사도)를 파악하기 위해 제시된 방법이며 공식 안에서 "Scaling"과 "내적(Dot-Product)"을 사용한다. 몇년 전 처음 이 공식을 봤을 때, Query, Key, Vector라는 이름으로 왜 저렇게 명명했으며 Attention이란 인문학적인(?) 표현이 잘 와닿지 않았다.
지금 이해된 수준에선 Scaled Dot-Product Attention의 수식의 특징을 풀어서 이렇게 설명할 수 있을 것 같다.(정확한 표현인지는 모르겠다.)
Attention은 Value 벡터에 대한 가중 평균을 구 특정 단어에 집중하게 만드는 방식이라 설명하고 싶다. 조금 더 추상적인 표현으로는 주어진 문장에서 질문과 연관이 있는 핵심 단어에 대해서만 가산점을 부과하여 주목하는 방식이다.(Query, Key, Value란 값을 해석했을 때)
공식을 하나씩 쪼개서 왜 이런 의미를 갖는지 알아본다.
1. Q, K, V 값을 만들자(선형 변환)
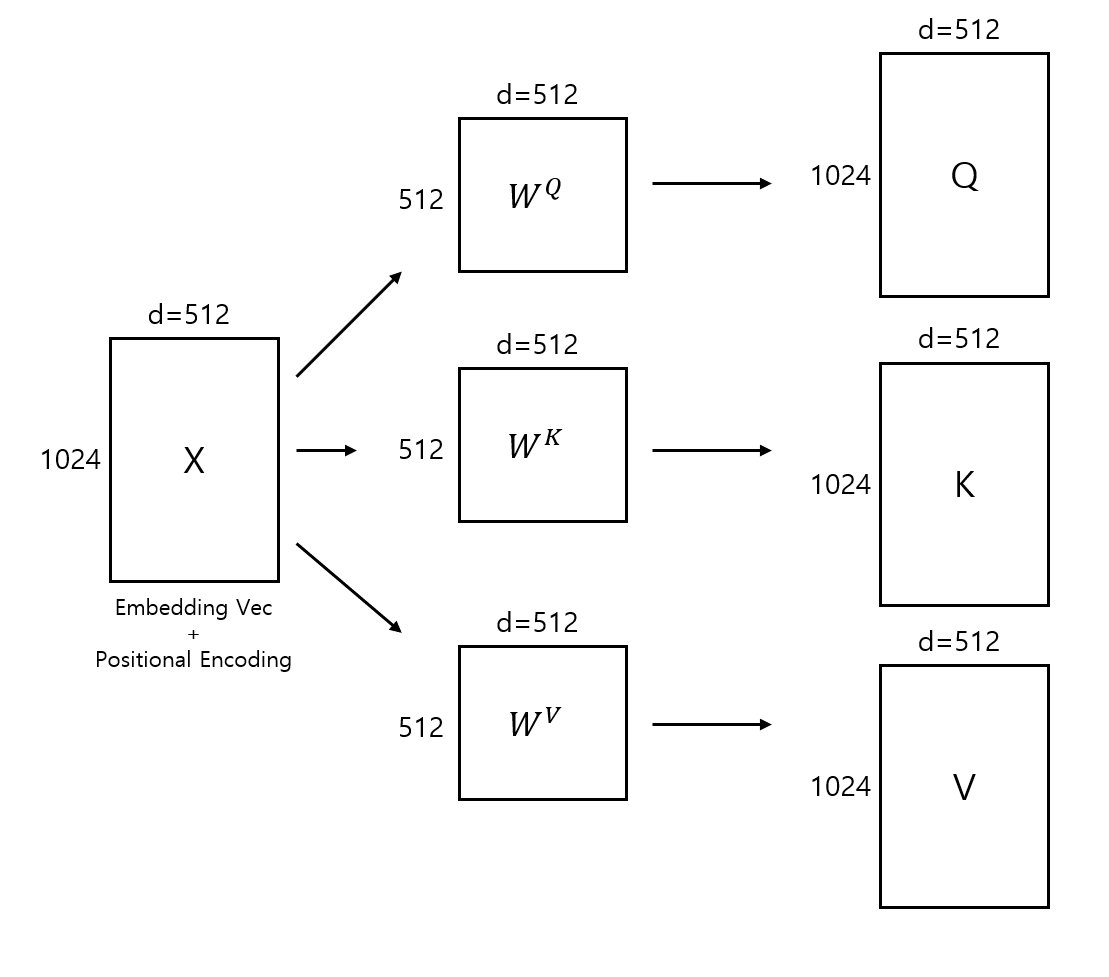
공식에 등장하는 Query, Key, Value Vector는 Self-Attention의 개념에서 봤을 때 모두 Embedding Vector와 Positional Encoding 값에 대해 선형 변환을 한 값이다. 선형 변환을 하는 이유는 Attention 연산에 적합하기 위해 Query, Key, Vector의 Shape이 동일해야 하기 때문이다. 물론 논문에서 나오는 예제인 (1024, 512) shape에 대해선 내적을 위해 선형 변환이 필요하지 않다.
내적, Softmax, 그리고 정규화
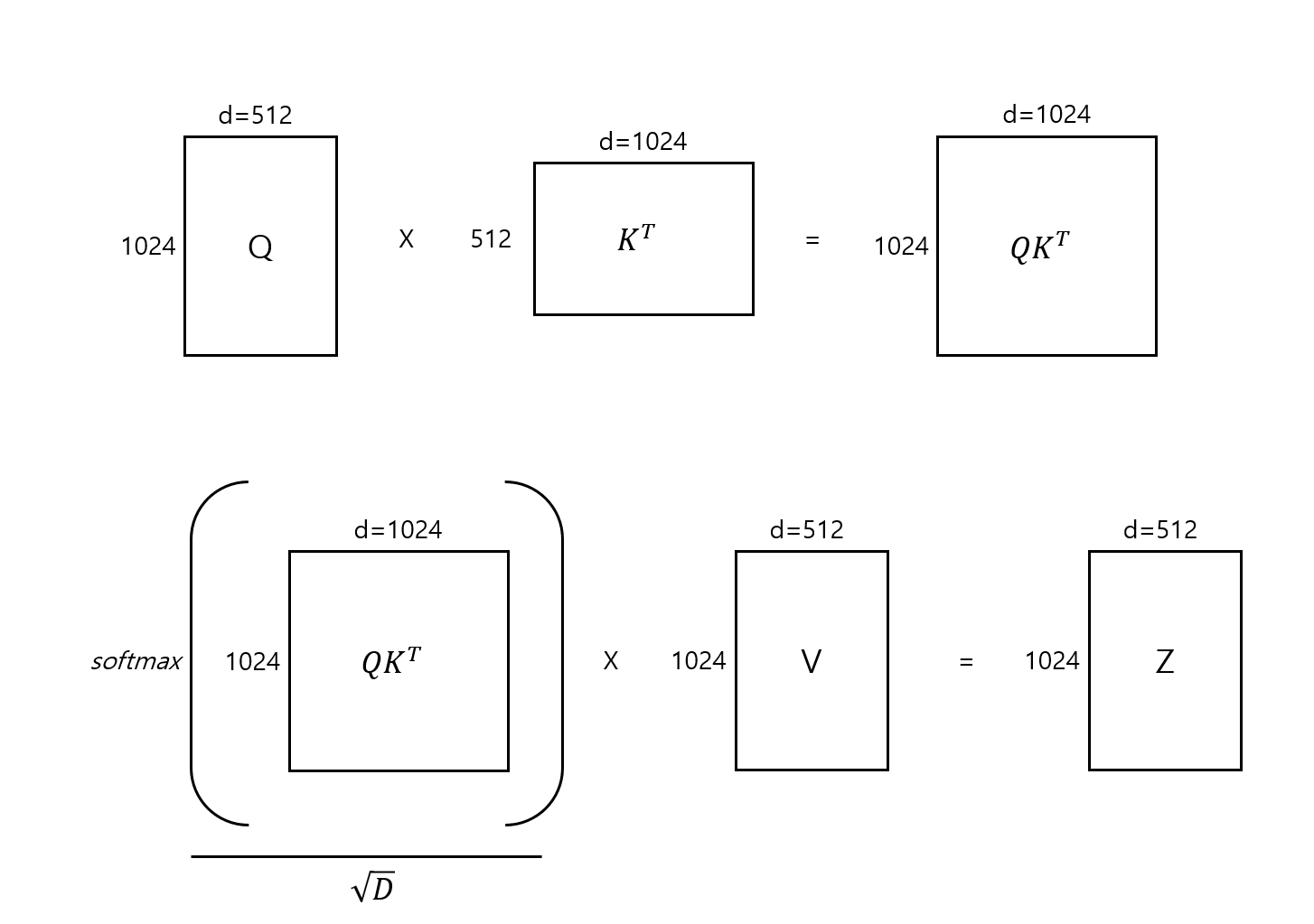
Query 벡터와 Key 벡터의 역행렬(행렬 연산을 위함)의 내적은 1024개 Token에 대한 유사도를 구하는 첫번째 관문이다. 이후 softmax를 통해 내적의 값을 0~1 사이로 바꿔줌으로써 가중치 벡터의 형태로 변환해준다. 이 때 차원의 제곱근으로 가중치 벡터를 나누어 주는데, 이는 벡터의 차원이 늘어날수록 내적의 값이 커지고, 그에 따라 softmax 함수를 적용했을 때 스칼라 값의 대부분이 0에 가까워지는 편향된 분포를 보이게 된다. 모델의 차원수로 값을 나눠주는 정규화 방법을 통해 벡터 전체에 대한 분산을 줄일 수 있다.
참고 링크에서 언급한 것처럼 Value 벡터를 곱하기 전까지의 전개는 코사인 유사도를 구하는 수식과 유사하다.
코사인 유사도 또한 A,B 벡터의 내적값을 각 벡터의 합의 곱(L2 Norm)으로 나누어주는데 Attention은 머신러닝에서 오래전부터 사용하던 거리 기반으로 유사도를 측정하는 방법을 신경망에 하나의 Layer로 가져온 것이다.
마지막 과정인 가중치 벡터와 Value 벡터의 내적은 Value 벡터에 대한 가중 평균을 구하는 것과 동일한 의미를 가진다.
다음 글에서는 Scaled Dot-Product Attention의 확장 개념인 Multi-head Attention에 대해 알아보려 한다.
참고한 글
Self-attention과 multi-head self attention의 차원 변화에 대한 연산 과정, 의미를 상세하게 설명해주셔서 많은 도움이 됐다. 글의 뒤쪽에 positional encoding, masked attention에 대한 설명도 있다.
-
민경님의 블로그 글
간략한 예시와 함께 이해하기 쉽게 글을 풀어 써주셨다. -
Transformer 논문
"Attention Is All You Need", 다른 설명을 한번 보고 읽으니 이해하기 훨씬 수월했다.
