
문제
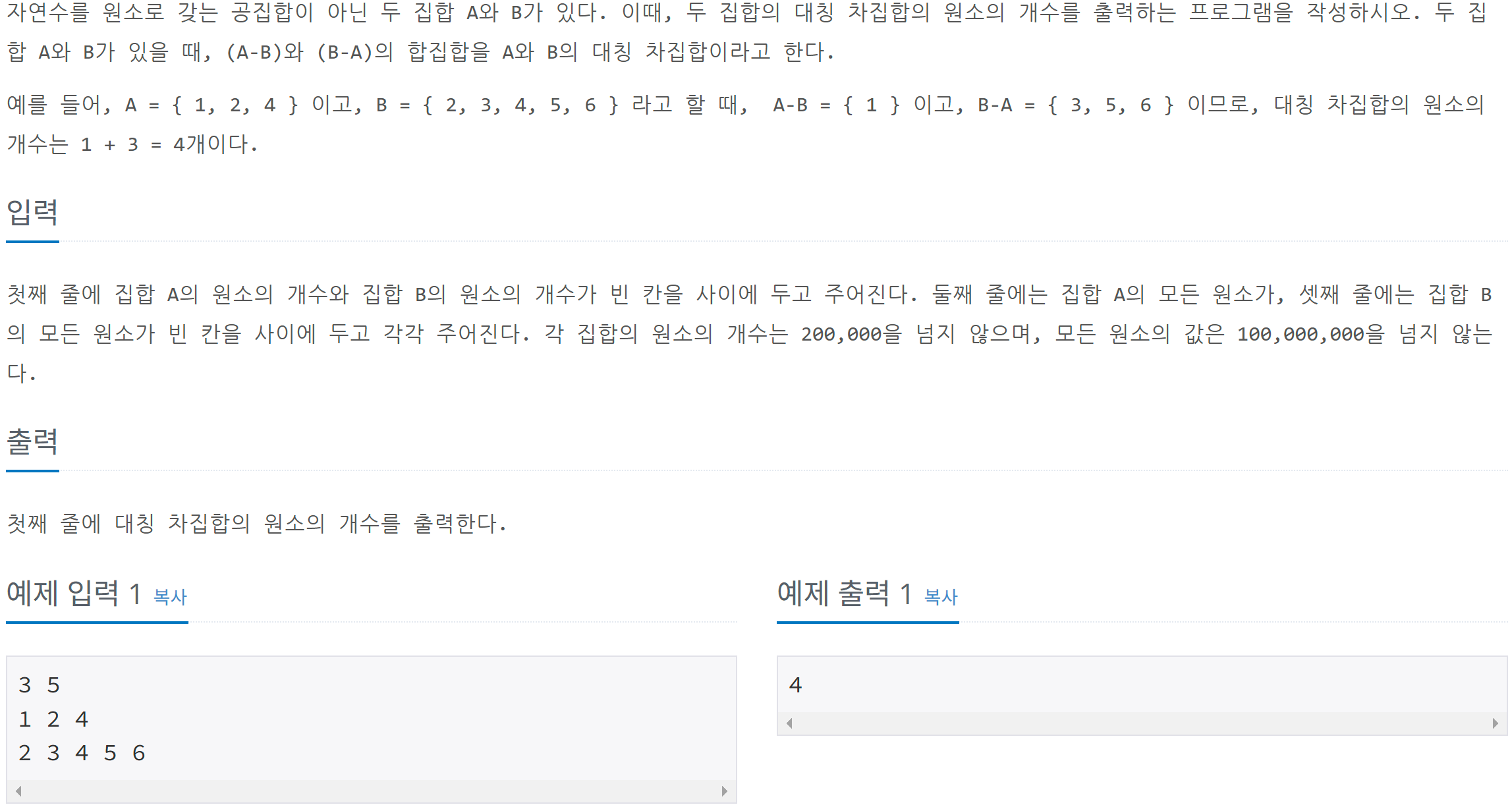
메모리 초과
오늘 푼 다른 문제들과 마찬가지로 인덱스 기반 풀이로 갔더니
메모리 초과 이만큼 ~
시간 초과도 아니고 메모리 초과라길래
long long 이런거 만져보다가 수상해보이는 벡터 발견
생각해보니까 메모리 제한이 256MB인데 1억이 넘는 벡터?
절대 통과 모대
인덱스로 풀어서 통과가 된 것은 가히 기적이라 말할 수 있었던 것이다.
어쩐지 풀면서 찝찝했어
#include <iostream>
#include <vector>
using namespace std;
int na, nb, tmp;
int cnt = 0;
vector<int> v(100000001);
int main() {
cin >> na >> nb;
for (int i = 0; i < na; i++) {
cin >> tmp;
v[tmp]++;
}
for (int i = 0; i < nb; i++) {
cin >> tmp;
v[tmp]++;
if (v[tmp] == 2) cnt++;
}
cout << na + nb - 2 * cnt;
return 0;
}unordered_set
그러면 다른 방법으로 풀어야겠다 하고 생각한 게
연관 컨테이너에 들어있는 멤바 함수 find()다.
내가 아는 연관 컨테이너는 map하고 set 뿐인데
값은 하나만 저장하면 되니까 map은 아니고
set을 쓰긴 쓸건데 정렬까진 또 필요가 없다.
그래서 찾아본 것이 unordered_set.
말 그대로 안순서 set이다.
set처럼 중복을 허용하지 않고
탐색, 삽입, 삭제의 평균 시간복잡도가 O(1)이라고 하니
이 문제에 쓰지 않을 이유가 없시
풀이
각 집합을 unordered_set에 각각 넣어주고,
find 함수를 활용해서
a에 있는 값이 b에 없을 때 cnt++,
b에 있는 게 a에 없을 때 cnt++ 해주면 된다.
코드
#include <iostream>
#include <unordered_set>
using namespace std;
int main() {
int na, nb, tmp;
unordered_set<int> a, b;
cin >> na >> nb;
for (int i = 0; i < na; i++) {
cin >> tmp;
a.insert(tmp);
}
for (int i = 0; i < nb; i++) {
cin >> tmp;
b.insert(tmp);
}
int cnt = 0;
for (int ai : a) {
if (b.find(ai) == b.end()) cnt++;
}
for (int bi : b) {
if (a.find(bi) == a.end()) cnt++;
}
cout << cnt;
return 0;
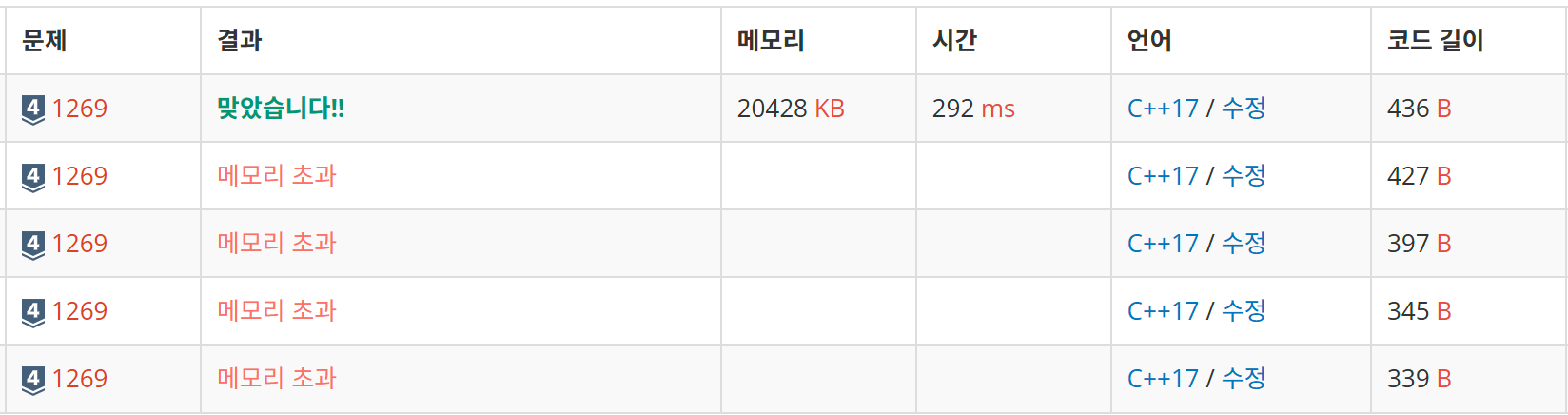
}채점
배울 거 많다 ~

난멋져