Swapping
swapping은 memory virtualization의 마지막 assumption을 relax하는 것이다.
다음과 같은 가정을 해보자.
- user의 address space는 physical memory에 연속적으로 존재해야 한다 (memory region 사이에 hole이 없음).
- address space의 size는 physical memory의 size보다 작다.
- 각 address space는 같은 크기를 가지고 있다.
process는 자신이 큰 크기의 address space를 갖고 있다는 illusion을 갖고 있는데 보통 64-bit 기준 2^48의 address space가 컴퓨터의 DRAM size나 server, data center보다 크다.
infinite size의 address space를 support하기 위해서는(process의 sizer가 몇이 될지 확실히 알 수 없기 때문에) resource를 expand해야한다.
큰 address space가 필요할 경우 memory만으로는 부족하기 때문에 memory와 disk를 함께 사용하게 되는데 이 때 어떤 page를 memory에 두고 어떤 page를 disk에 둘 것인지 고민을 해야한다. disk에 있는 page는 memory에 있는 page에 비해 상대적으로 fetch하는 것이 오래걸리기 때문이다.
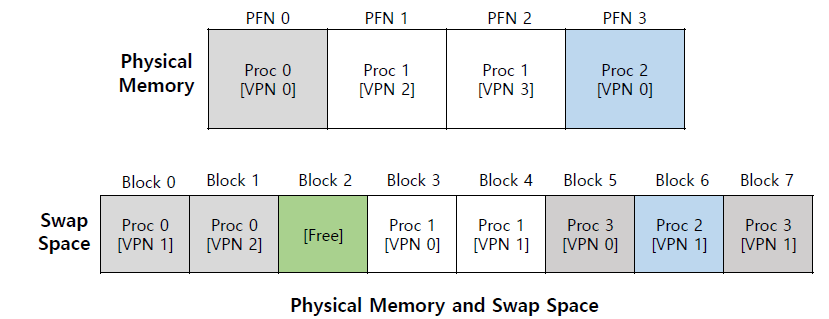
single DRAM 하나에 전체 address space를 담을 수 없으니까 swap space라고 불리는 disk의 일부를 함께 사용한다. 그것을 swapping이라고 한다.
swap space는 큰 disk의 part의 logical concept이다. disk는 large size를 갖고 있기 때문에 process의 large address space를 전부 담을 수 있다.
 OS는 address space에서 현재 사용되지 않는 page를 살짝 치워두는데 그 역할을 현대에는 hard disk drive가 담당하고 있다.
OS는 address space에서 현재 사용되지 않는 page를 살짝 치워두는데 그 역할을 현대에는 hard disk drive가 담당하고 있다.
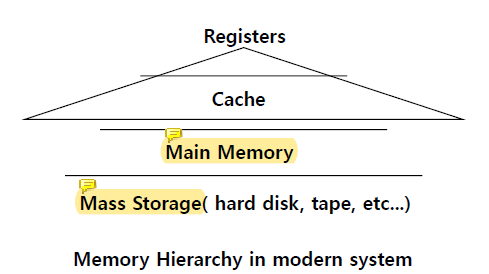
main memory는 fast하지만 small이고, mass storage는 slow하지만 large하다.
capacity가 large할 수록 slower, cheaper price라는 특성을 가진다.
즉, size가 클 수록 가격은 싸고 data를 fetch하는 시간이 오래 걸린다.
이러한 특성으로 인해 trade-off이 발생하게 된다.
자주 access되는 page는 memory에 저장되어야 하고 process가 더 많은 memory를 request하면 OS는 memory를 physical frame에 allocate해야한다.
process가 OS에게 더 많은 memory를 request한다면 OS는 physical memory의 free space가 작아진다는 pressure가 생긴다. memory pressure가 발생하면 OS는 몇 개의 page를 선택애서 paging out하게 된다.
Swap Space
user process는 page가 disk에 있는지 아닌지 알 수 없다.
process는 단지 그저 전체 address space의 임의의 memory 위치에 접근한다고 생각한다. swap space를 이용해 이 illusion을 제공하는 것이 OS가 해야하는 역할이다.
OS는 swap space를 이용해서 process가 어떤 임의의 memory address에도 allocate하거나 access할 수 있다는 illusion을 준다.
swap space는 page를 넣었다 뺐다 하기 위해 disk에 예약된 공간이다.
OS는 swap space를 page-sized unit으로 기억하고 있어야 한다.
Present Bit
present bit은 current page가 DRAM에 있는지 아닌지 나타낸다.
만약 fetch하고자 하는 page가 DRAM에 있지 않다면 그 page를 disk로부터 fetch해서 memory에 저장하고 process가 access할 수 있도록 하는 것이 OS의 일이다.

What If Memory Is Full?
memory가 꽉 찼을 때 OS는 새로운 page를 가져오기 위한 공간을 확보하기 위해 기존에 있던 page를 memory에서 제거한다.
process는 page-replacement policy에 의해 kick out할 page를 정한다.
OS는 process가 memory space를 어떻게 access했냐에 따라 page를 replace하는 것 뿐이다.
Page Fault
OS가 missing page를 swap space에서 memory로 fetch해서 process가 그 page에 access할 수 있도록 해주는 것이 page fault이다.
page fault는 interrupt임..
hardware가 virtual address를 physical address로 translate할 때 그 page가 DRAM에 있는지 아닌지 detect할 수 있다.
만약 page가 DRAM에 있는 것이 아니라면 process가 page fault를 generate해서 CPU를 통해 interrupt handler가 invoke된다.
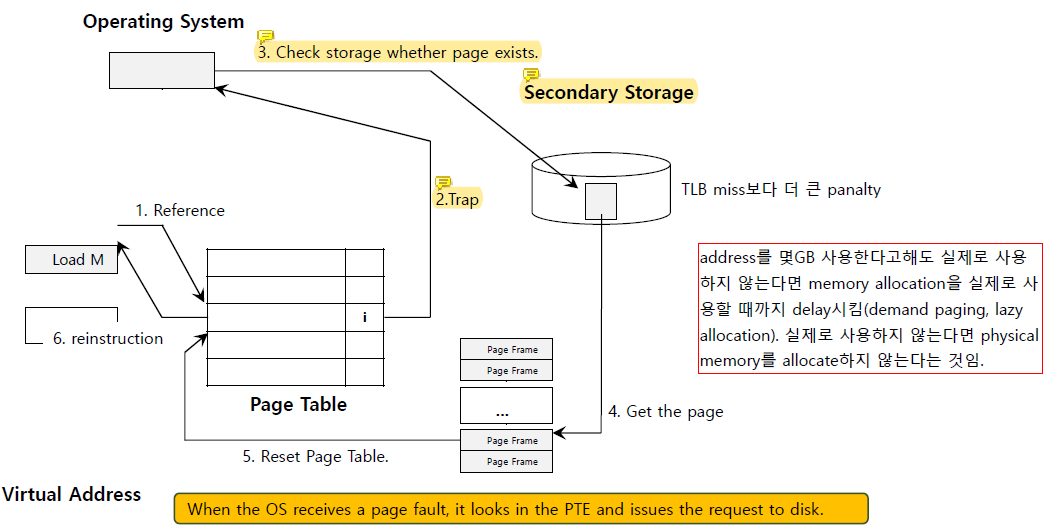 memory에 page가 존재하지 않는 것을 알게 되면 자동으로 page fault를 generate한다. trap인 이유는 page fault를 스스로 generate하기 때문임.
memory에 page가 존재하지 않는 것을 알게 되면 자동으로 page fault를 generate한다. trap인 이유는 page fault를 스스로 generate하기 때문임.
page fault가 일어나면 page fault를 trigger한 memory virtual address가 어딘가에 기억되어야 하는데 그것이 CR4 레지스터에 저장된다.
CR4를 보고 어떤 page에 access해야 하는지 page number를 확인하고 swap space에 access한다.
swap space에서 page를 찾아 page table로 옮긴다.
address를 몇 GB 사용한다고 해도 실제로 사용하지 않는다면 memory allocation을 실제로 사용할 때까지 delay시킴 (demand paging, lazy allocation). 실제로 사용하지 않는다면 physical memory를 allocation하지 않는다는 것이다.
Cache Management
replacement policy의 궁극적인 목표는 cache miss의 수를 최소화하는 것이다.
cache miss가 발생할 때마다 panalty가 있고 TLB miss보다 page fault의 panalty가 더 크다. page fault가 났을 때는 disk에 다녀와야 하기 때문이다.
cache hit과 miss로 average memory access time(AMAT)을 계산할 수 있다.
AMAT = (P_hit * T_M) + (P_miss * T_D)
T_M과 T_D에서의 cost는 access하는데에 드는 시간을 의미한다.
The Optimal Replacement Policy
miss가 가장 적게 만드는 방법이 optimal이다.
가장 나중에 access될 page를 대체하는 것이다.
하지만 이는 모든 page reference에 대해 사전에 알고 있을 때만 가능한 얘기이다. 따라서 optimal replacement policy는 사실상 불가능하다. 최대한 optimal에 가깝게 만들 뿐이다.
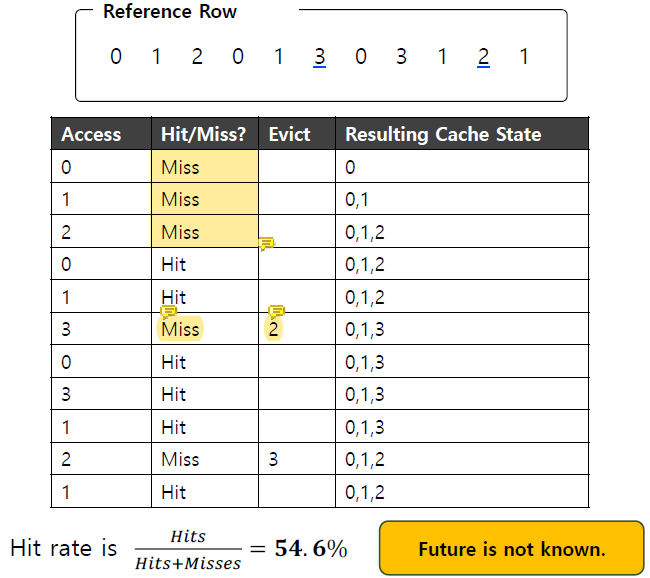 cache에 담을 수 있는 값이 총 3개라고 할 때, 처음의 세 miss는 page가 처음으로 access되기 때문에 발생하는 cold miss이다.
cache에 담을 수 있는 값이 총 3개라고 할 때, 처음의 세 miss는 page가 처음으로 access되기 때문에 발생하는 cold miss이다.
그 다음에 발생하는 miss는 capacity miss인데, cache area가 꽉 차 있어서 새로운 것에 access할 때 capacity limit으로 인해 memory에 새로운 page를 넣기 위해서 memory의 어떤 것은 evict해야하는 경우를 의미한다.
이 때 3으로부터 0, 1, 2 중 가장 멀리 떨어진 것이 2이므로 2를 evict하는 것이 optimal이다.
이 경우 hit rate는
(Hit rate) = Hits / (Hits + Misses) = 6 / (6 + 5) = 54.5%이것은 미래를 알고 있어야만 가능한 것이라 optimal이며, 실제로는 불가능하다.
small size의 fast한 storage와 big size의 slow한 storage가 존재하면 반드시 cache problem에 직면하게 된다.
register과 memory이든, memory와 disk이든...
우리는 cache policy를 통해 궁극적으로는 미래를 예측하고 싶은 것이다.
과거를 통해 미래를 예측하기. 그렇기 때문에 cache policy가 여러 개 생기는 것이다. 미래를 예측하기 위한 방법이 많기 때문이다.
어떤 사람은 미래를 예측하기 위해 frequency를 더 중요하게 생각할 수 있고 어떤 사람은 recent가 중요할 수 있고 각자 중요하다고 생각하는 것으로 new metric을 만들어서 과거를 capture하고 더 신중하고 정확하게 미래를 예측하고자 한다.
FIFO
page가 system에 처음 들어왔을 때 queue에 위치하게 되고 replacement가 발생하면 가장 queue에 일찍 들어온 page를 evict하는 것이다.
이것은 구현하기 간단하지만 각 cache block 중 어느 것이 중요한지 구분해내지는 못한다.
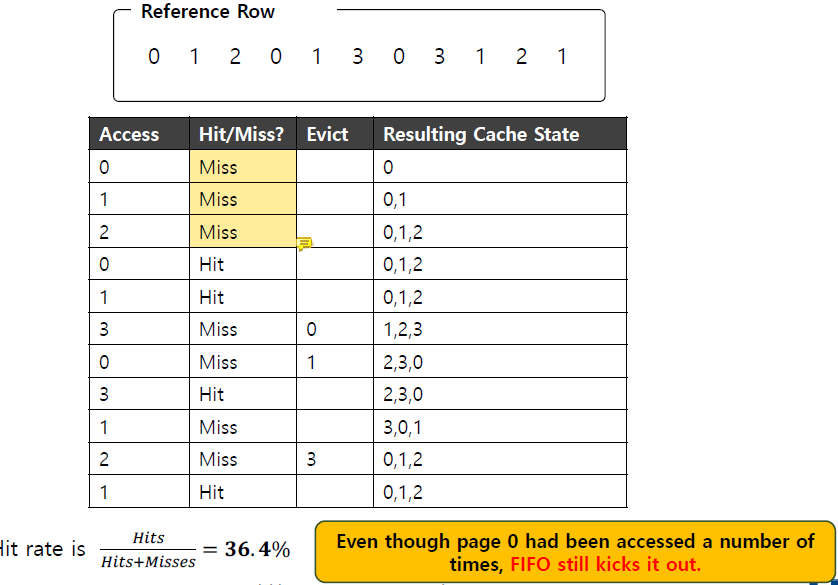 맨 처음 3번의 cold miss가 발생한 이후, cache miss가 될 때마다 cache에 먼저 들어온 page의 순서대로 evict하는 것을 확인할 수 있다.
맨 처음 3번의 cold miss가 발생한 이후, cache miss가 될 때마다 cache에 먼저 들어온 page의 순서대로 evict하는 것을 확인할 수 있다.
이 경우 hit rate는
(Hit rate) = 4 / (4 + 7) = 6 / (6 + 5) = 36.4%FIFO는 무조건 page가 cache에 들어온 순서대로 evict하므로 page의 중요도에 상관 없이 page를 evict한다.
3에서 cache miss가 된 시점에 이전에 0은 2번, 1도 2번, 2는 1번 access되었지만 이 경향성과 전혀 관련 없이 0을 evict한 것을 확인할 수 있다.
Belady's Anomaly
우리는 cache의 크기가 커질수록 cache안에 담을 수 있는 cache block의 양이 늘어나므로 hit rate가 증가하길 기대하지만 FIFO의 경우 hit rate가 특정 시점에서는 오히려 안좋아진다.
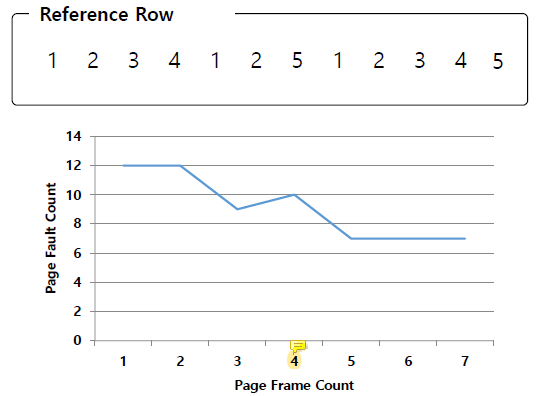 이 그래프를 보면 page frame을 늘렸을 때 page fault가 줄어들기만 하는 것이 아니라 증가하는 지점이 있음을 확인할 수 있다.
이 그래프를 보면 page frame을 늘렸을 때 page fault가 줄어들기만 하는 것이 아니라 증가하는 지점이 있음을 확인할 수 있다.
Random
memory pressure가 발생했을 때 random page를 선택해 evict하는 것이다.
뭔가 어떤 기준이나 지능적인 방법을 통해 evict할 page를 고르는 것이 아니라 얼마나 운이 좋게 page를 선택하는지에 결과가 좌우된다.
 때로는 random이 optimal만큼 좋게 작동하는 경우도 있다.
때로는 random이 optimal만큼 좋게 작동하는 경우도 있다.
Using History
과거에 의존해 과거를 통해 future behavior를 예측하는 것이다.
 가장 사용한지 오래 된 것을 갈아치우는 least recently used(
가장 사용한지 오래 된 것을 갈아치우는 least recently used(LRU)와 가장 덜 사용되는 것을 갈아치우는 least frequently used(LFU)등이 있다.
LRU
replaces the least-recently-used page
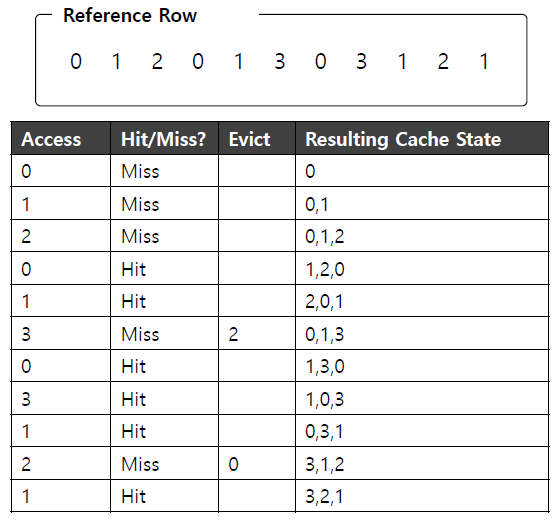 least-and-recently-used 방법을 구현하기 위해서는 every memory reference를 account할 약간의 hardware support가 추가적으로 필요하다.
least-and-recently-used 방법을 구현하기 위해서는 every memory reference를 account할 약간의 hardware support가 추가적으로 필요하다.
이 hardware support는 use bit이다. 일종의 reference bit이다.
만약 page가 reference되면 hardware가 use bit을 1로 set한다.
hardware는 이 bit을 절대 clear하지 않고 use bit을 clear하는 것은 전적으로 OS의 역할이다.
Clock Algorithm
approximate LRU이다.
시스템의 모든 page가 circular list형태로 정렬되어 있다.
clock hand가 시작할 particular page를 가리키고 있다.
 clock hand가 가리키는 page의
clock hand가 가리키는 page의 use bit이 0이면 그 page를 evict하고 1이면 use bit을 clear한다.
clock이 빠르게 돌 수록 시스템의 overhead가 커진다. cache replacement algorithm을 여러 번 호출해야하기 때문이다.
clock algorithm은 모든 page를 확인해서 각 page가 언제 reference되었는제 확인하지 않아도 LRU와 비슷하게 동작시킬 수 있다.
기존의 LRU는 모든 page의 time stamp를 비교해서 oldest one을 찾아야 했는데 매번 cache의 모든 page를 다 확인하는 것은 overhead가 너무 크다.
time stamp를 위한 자료구조도 필요하지만 oldest를 찾기 위해 cache를 전부 확인해야하기 때문이다.
반면 clock algorithm은 use bit의 1-bit만 확인하면 된다.
'야 너 use bit 켜져있네? 그래도 한 바퀴 전에는 reference 됐다는 거니까 한 번 더 기회 준다.' 이러면서 use bit을 끄는 것이다.
그리고 그 다음에 reference가 되지 않았으면 (use bit이 0이라는 뜻. 다시 clock head가 돌아오기 전까지 reference 되었다면 use bit이 1이 되었을 것이기 때문) 갈아치운다.
clock algorithm은 LRU를 approximate하지만 정확히 oldest one을 골라내지는 못한다.
그래서 reference time metric이 등장한 것이다.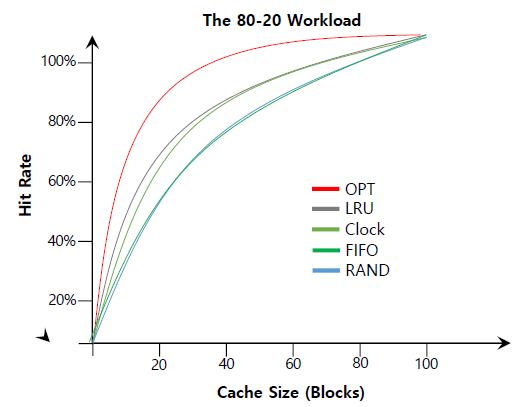 그래프를 보면 clock algorithm이 완벽히
그래프를 보면 clock algorithm이 완벽히 LRU처럼 동작하지는 못하지만 history를 아예 고려하지 않는 방법보다는 좋은 성과를 내는 것을 확인할 수 있다.
Workload Example
The No-Locality Workload
각 reference는 access된 page 집합 내의 임의의 page에 대한 것이다.
workload는 100개의 unique page에 access한다.
next page는 random하게 선택된다.
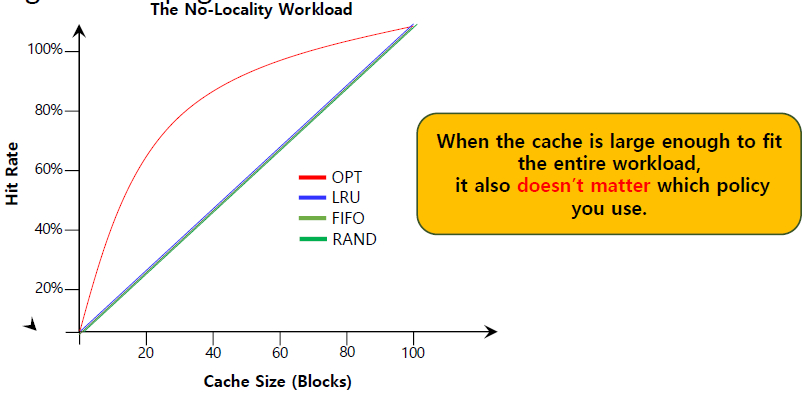 만약 cache가 모든 workload를 fit할 정도로 크다면 어떤 policy를 쓰든 성능이 동일하기 때문에 상관이 없다.
만약 cache가 모든 workload를 fit할 정도로 크다면 어떤 policy를 쓰든 성능이 동일하기 때문에 상관이 없다.
The 80-20 Workload
80%의 reference가 20%의 page에 의해 발생하는 경우이다.
남은 20%의 reference는 남은 80%의 page에 의해 발생한다.
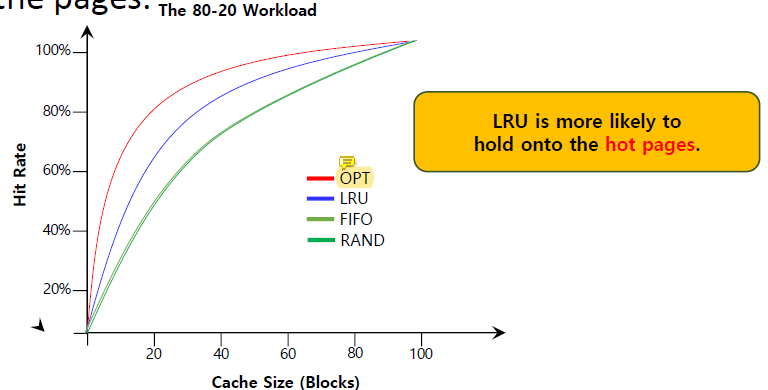
LRU가 자주 사용되는 hot page를 hold하는 경향이 있다. 성능이 높다는 뜻.
The Looping Sequential
50 page를 순서대로 참조한다고 가정한다.
unique한 50개의 page를 0, 1, 2, ..., 49까지 참조하고 다시 0부터 이를 access가 10000번이 될 때까지 반복하는 것이다.
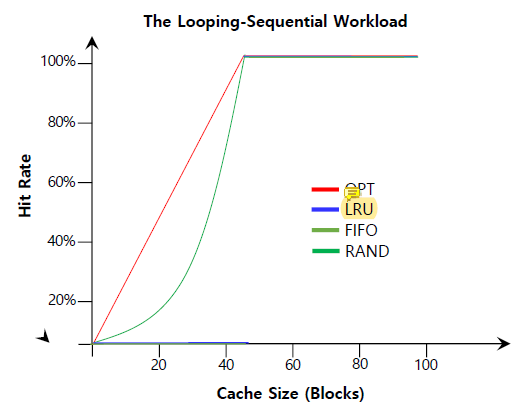
LRU는 그야말로 쓰레기처럼 작동한다. loop가 크면 계속 cache miss만 나기 때문이다. 새로운 것들이 계속 나오기 때문에 무조건 miss만 나면서 값이 갱신된다.
FIFO 또한 쓰레기처럼 동작하는데 무조건 가장 앞에 있는 것을 evict하기 때문에 무조건 miss만 나기 때문이다.
Considering Dirty Pages
hardware는 modified bit(dirty bit)을 포함하고 있다.
cache의 page가 modify 되었다면 dirty하므로 이를 cache에서 evict하기 전에 반드시 disk에 바뀐 값을 write해야한다.
page가 modify되지 않았다면 그냥 evict하면 된다.
Page Selection Policy
OS는 언제 page를 memory에 가져올 것인지 결정해야한다.
Prefetching
OS가 page가 곧 사용될 것이라고 추측하고 미리 가져오는 것이다.
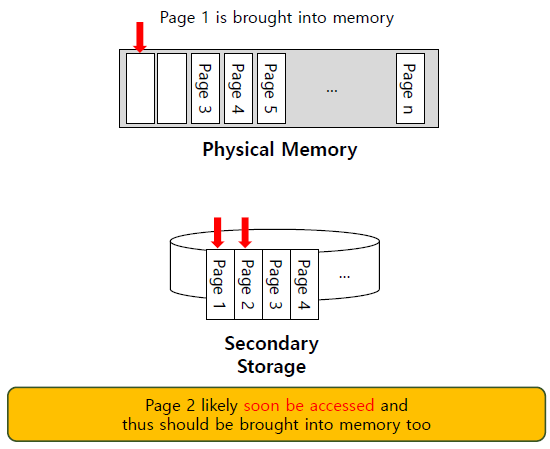
page 1을 사용하기 위해 memory에 불러올 때 page 2도 곧 사용할 것 같다고 생각해 page 2까지 memory에 가져오는 것이 prefetching이다.
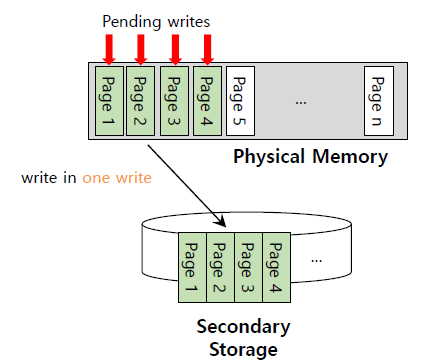
Clustering, Grouping
memory에서 pending write를 여러 개 모아 한 번에 disk에 write하는 것이다.
single large write를 수행하는 것이 many small write를 하는 것보다 효율적이기 때문이다.
Thrashing
memory가 oversubscribe되고 실행 중인 process 집합의 memory 요구량이 사용 가능한 physical memory를 초과하는 것이다.
oversubscribe는 overcommitment와 같은 말인데, 운영체제에서 위와 같은 상황이 발생하면 내부에서 swapping을 수행한다. 최근에 사용되지 않은 page를 조금씩 flush하는 것이다.
그렇게 되면 swapping in, swapping out의 disk I/O만 매우 반복적으로 수행하게 된다. 어떤 single page에 접근하려면 공간이 부족해서 다른 page를 빼내고 그 자리에 새로운걸 넣고, 하나 가져오면 하나 빼고를 반복하는 것이다.
그래서 마우스도 잘 안움직이고 키보드도 안먹는다.
그렇게 되면 일부 process를 실행하지 않기로 결정하거나 memory에 fit하는 working set에서 process의 수를 줄인다.