✨Concurrency (1)
운영체제

Concurrency: An Introduction
process는 자신이 CPU와 memory를 소유하고 있다는 illusion을 가지고 있었고 single point of execution을 가졌다.
thread는 single running process에 대한 새로운 abstraction이다.
thread는 multiple execution flow를 가진다.
multi-threaded program은 하나 이상의 point of execution을 가지며 여러 개의 PC를 가지고 있다. 하지만 address space는 공유한다.
Context Switch Between Threads
각 thread는 자신만의 PC와 register set을 가지고 있다.
각 thread의 상태를 나타내기 위해 하나 이상의 thread control block(TCB)가 필요하다.
running하고 있는 두 thread 사이의 switch를 할 때에는 한 thread의 register state를 저장하고 다른 thread의 register state를 restore하면 된다.
thread간의 switch를 하더라도 address space는 그대로 남아있다.
process와 다르게 thread는 address space를 share한다. process는 address space를 share하면 protection boundary를 violation하게 된다.
The Stack of the Relevant Thread
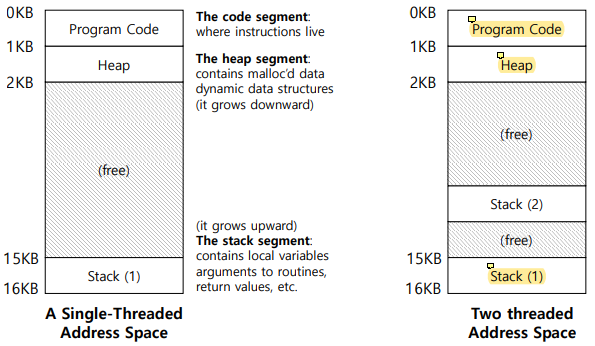 각 thread마다 한 개의 stack을 소유한다.
각 thread마다 한 개의 stack을 소유한다.
multi thread는 single process에 의해 생성되기 때문에 memory space를 share하게 된다.
그래서 thread마다 별도의 execution environment가 필요하고, stack을 thread마다 각각 따로 사용한다.
thread가 address space를 공유하면 program code를 공유하고 heap도 share한다 (heap은 반드시 share할 필요는 없지만 많은 경우 default policy로 heap을 share한다).
하지만 stack이 execution flow를 capture하고 있기 때문에 각각 별도의 stack을 가진다.
Why Threads?
-
Parallelism
만약 우리가 여러 개의 physical CPU가 있고 hardware resource가 매우 풍부하다면 여러 개의 physical CPU core를 utilize할 수 있다 (exploiting multiple physical CPUs).
multiple CPU를 exploit하려면 single process 안에서 multiple execution flow를 create해야한다. 내가 하나의 single program을 갖고 있고 내가 code의 각각 다른 부분을 실행할 수 있는 multiple execution flow를 만들 수 있다면 multiple physical CPU를 utilize할 수 있다. -
Avoid blocking program progress due to slow I/O
I/O가 끝날 때까지 기다리지 않고 CPU가 다른 useful computation을 할 수 있도록 utilize할 수 있다.
만약 multiple physical core에 의해 support되는 parallelism을 exploit한다면 slow I/O가 program의 progress를 blocking하는 것을 피하기 쉽다. single execution flow만 있고 code에서 frequent하게 I/O를 perform하는 프로그램이 있다면 read/write를 system call을 실행할 때마다 process를 block해야한다...
I/O와 병렬적으로 수행될 수 있는 code가 존재함에도 single execution flow밖에 없다면 전체 프로그램을 block 해야한다.
Why It Gets Worse: Shared Data
single process에서 생성된 모든 multiple thread는 data를 share한다.
address space를 share한다는 것은 모든 thread가 같은 data에 access할 수 있다는 의미이다. 이것은 race condition을 야기한다.
두 thread가 50이 들어있는 counter의 값을 1 증가시키려고 한다고 가정하자.
100 mov 0x8049alc, %eax
105 add $0x1, %eax
108 mov %eax, 0x8049alc우리는 결과값이 52가 되기를 기대하지만 그렇게 동작하지 않을 수도 있다.
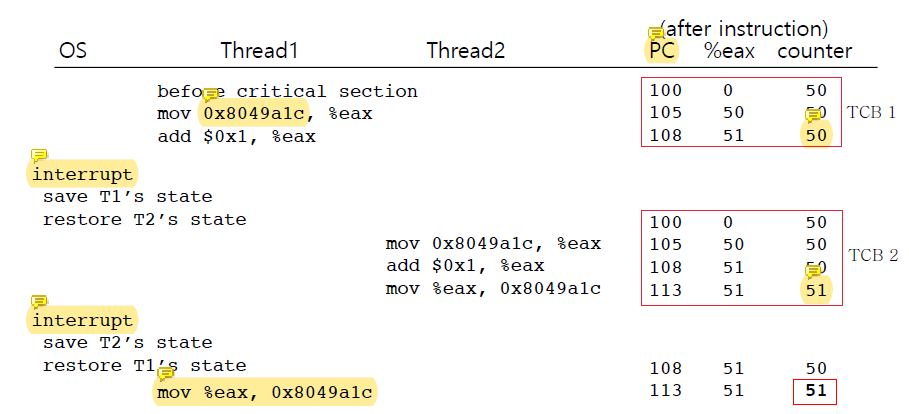 세 instruction에서 바뀐
세 instruction에서 바뀐 counter의 값이 반영되기 위해서는 108번째 줄의 mov가 실행되어야 한다.
thread1에서 counter에 1을 더하고 이를 반영하기 전에 interrupt가 발생하였다고 가정하자. OS는 thread1의 실행을 중단하고 thread2을 실행하기 시작했다.
thread2는 아무것도 모르고 50인(51이어야 하지만 반영되지 않은) counter의 값을 읽어서 1 증가시키고, 저장까지 완료해 counter를 51로 만들었다.
이후 다시 interrupt가 일어나 thread1의 실행이 시작되었지만 thread1은 counter의 값이 51이 된 줄도 모르고 자신의 실행이 멈췄던 지점부터 실행을 재개해 자신이 원래 반영하려고 했던 값인 51을 다시 counter에 overwrite하였다.
즉, 52가 되어야 할 결과는 51이 되었다.
Race Condition and Critical Section
위의 문제가 발생한 원인은 race condition이다.
여러 instruction을 실행하였고 그 과정이 atomic하지 않았기 때문이다.
counter의 값을 1 증가시키는 것에 instruction이 3개나 실행되어야 했고 그것이 한번에 실행되지 않은 것이 문제.
Critical Section
shared variable에 접근하고 한 개 이상의 thread에 의해 concurrently하게 실행되면 안되는 code 영역이다.
multiple thread가 critical section을 실행하면 race condition이 발생한다. 따라서 critical section에 대해서는 atomicity를 보장해야한다 (mutual exclusion).
mutual exclusion은 1 single execution flow만 critical section을 실행하는 것을 허용하는 것이다.
multiple thread가 shared variable에 access하는데 read만 한다면 그것은 benign race로, safe하다. 하지만 그 중 하나라도 write를 수행한다면 malicious data race가 된다.
Mutual Exclusion Using Locks
모든 critical section이 하나의 atomic instruction처럼 실행되도록 보장해줘야 한다.
series of instruction을 다른 execution flow의 개입 없이 실행할 수 있다면 mutual exclusion을 guarantee하는 것이다.
 lock을 사용하면 다음과 같이 critical section을 보호할 수 있다.
lock을 사용하면 다음과 같이 critical section을 보호할 수 있다.
Locks
lock은 어떤 critical section이라도 마치 single atomic instruction처럼 실행되도록 보장해준다.
만약 다음과 같은 critical section이 있다고 가정해보자.
balance = balance + 1;balance는 shared variable이다.
balance의 mutual exclusion을 보장하기 위해 lock을 추가한다.
lock_t mutex; // some globally-allocated lock 'mutex'
...
lock(&mutex);
balance = balance + 1;
unlock(&mutex);lock variable은 lock의 state를 hold하고 있다.
-
available (or unlocked or free)
No thread holds the lock. -
acquired (or locked or held)
Exactly one thread holds the lock and presumably is in a critical section.
sleep을 할 때는 절대 lock을 들고 있으면 안된다.
The Semantics of The lock()
lock()은 lock을 acquire하려고 시도한다.
만약 lock을 hold하고 있는 thread가 없으면 이 thread가 lock을 acquire한다.
lock을 획득하면 critical section에 진입하는데, 이 thread를 lock의 owner라고 한다.
만약 어떤 thread가 lock을 hold하고 critical section에 진입해있으면 다른 thread들은 critical section에 들어갈 수 없다.
mutex
mutex는 POSIX 라이브러리에서 사용하는 lock의 이름이다.
thread간의 mutual exclusion을 제공하는 데에 사용된다.
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
Pthread_mutex_lock(&lock); // wrapper for pthread_mutex_lock()
balance = balance + 1;
Pthread_mutex_unlock(&lock);다른 변수를 보호하기 위해서는 다른 variable을 써야한다.
이것이 concurrency를 증가시키고 더 fine-grained한 approach다.
Building a Lock
효율적인 lock은 mutual exclusion을 낮은 cost로 제공한다.
lock을 build하는 것은 hardware와 OS의 도움이 필요하다.
Evaluating Locks: Basic Criteria
-
Mutual exclusion
correctness에 대한 얘기이다. lock이 critical section에 multiple thread가 진입하는 것을 제대로 방지하는가? -
Fairness
각 thread가 다른 thread와 비교했을 때 lock을 획득할 동등한 chance를 가지는 것이다. thread가 starvation하면 안된다. -
Performance
lock으로 인한 time overhead가 과해지면 안된다.
Early Days: Controlling Interrupts
초기에는 mutual exclusion을 제공하기 위해 interrupt를 disable했다.
single-processor system을 위해 개발되었다.
 하지만 문제점이 있었다.
하지만 문제점이 있었다.
-
Application에 대한 너무 많은 신뢰가 요구됨.
greedy(or malicious) program은 processor를 monopolize할 수 있다. -
Multiprocessor에서 작동하지 않음.
내 core의 interrupt만 disable 해야 하는데 다른 core의 interrupt까지 disable 해버림. -
Interrupt를 mask 혹은 unmask하는 코드는 modern CPU에서는 느리게 처리됨.
Why Hardware Support Needed?
그 다음으로는 lock이 hold되었는지 아닌지 나타내는 flag를 사용하였다.
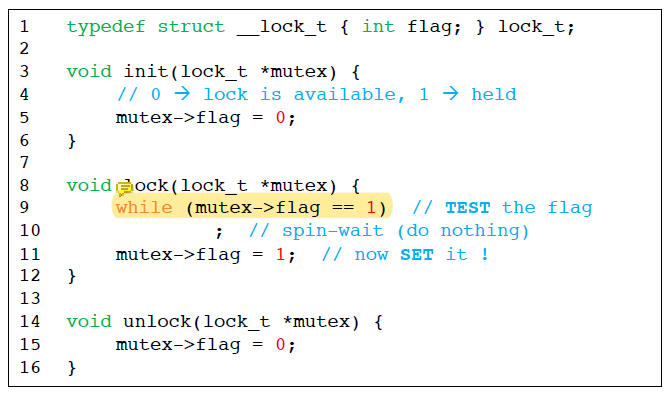 하지만 이 방법에도 문제점이 있었다.
하지만 이 방법에도 문제점이 있었다.
- Mutual exclusion이 보장되지 않는다.
flag = 0이 초기 상태로 가정한다.

flag가 0일 때 나 말고 다른 thread도 flag가 0이라고 생각한다. 그래서 내가 flag가 0인 것을 확인하고 그 flag를 바꾸려고 할 때 다른 애가 먼저 들어와서 flag를 바꾸는 것이다.
이렇게 되면 여러 개의 thread가 동시에 flag가 0이라고 생각해서 flag의 값을 바꿀 수 있다.
variable을 change하는 flag = 1은 atomic하지만 flag를 0에서 1로 바꾸는 writing action이 flag를 checking하는 것에 depends on 하는 것이 문제이다.
우리가 flag를 바꾸는 것에는 우리가 확인한 flag의 값과 지금 바꾸려고 하는 flag의 값이 같다는 전제가 깔려 있는건데 이 사이에 값이 바뀔 수 있다는 것이다.
내가 확인한 값을 바꾸기 전까지 그 값이 바뀌지 않길 원하는데 그것이 안된다.
다른 thread의 operation이 사이에 끼어들 수 있기 때문이다. 원하지 않는데도.
- 다른 thread를 기다리면서 spin-waiting을 하는 것이 시간낭비이다.
while문에서 flag가 1이면 spin 해야한다.
이것이 너무 시간낭비이기 때문에 이 부분을 atomic하게 해주기 위해서 RMW instruction이 생겨났다. RMW instruction은 hardware가 지원해주는 atomic instruction이다.
위와 같은 이유로 hardware가 지원하는 atomic instruction이 필요해졌다.
Test-And-Set (Atomic Exchange)
TestAndSet()은 simple lock을 만드는 것을 지원하기 위한 instruction이다.

ptr이 가리키고 있는 old value를 return(test)함과 동시에 그 값을 new로 바꾼다(set).
이 과정은 hardware에 의해 atomic하게 수행된다.
A Simple Spin Lock Using Test-And-Set

TestAndSet()은 atomic하기 때문에 single thread에게만 0을 반환할 것이다.
어떤 variable의 값을 확인했을 때 여러 thread에게 같은 값을 반환하니까 문제가 생겼던 건데 한 thread에게만 0을 반환하면 그 thread만 critical section에 접근할 수 있다.
flag의 초기값이 0일 때 여러 thread가 TestAndSet()을 호출하면 그 중 한 thread만 0을 return하면서 flag의 값을 1로 바꾸고 다른 thread는 이미 1로 바뀐 flag값을 읽어서 1을 return하며 flag를 1로 overwrite할 것이다.
결론적으로 0을 return받은 thread는 가장 처음의 thread 뿐이다.
Evaluating Spin Locks
-
Correctness : yes
spin lock은 하나의 single thread만 critical section에 들어갈 수 있도록 허용한다. -
Fairness : no
spin lock은 그 어떤 fairness guarantee도 제공하지 않는다.
최악의 경우 spin lock은 영원히 spin할 수도 있다. -
Performance
single CPU에서는 spin lock의 performance overhead는 상당히 괴로울 수 있다.
하지만 thread의 개수가 CPU의 개수와 어느정도 비슷하다면 spin lock은 합리적으로 잘 동작할 것이다.
Compare-And-Swap

CompareAndSwap()은 ptr 주소 안에 담긴 값이 expected와 같은지 test한다.
만약 같다면, ptr이 가리키는 memory location을 new value로 update한다.
그리고 memory location의 actual value를 return한다.
 위와 같은 형태로 사용된다.
위와 같은 형태로 사용된다.
lock이 보호하고 있는 flag의 값이 0이면 1로 바꿔주고 0을 return하고, 1인 경우에는 1을 return한다.
atomic하게 실행되는 instruction이기 때문에 flag가 0일 때 가장 먼저 CompareAndSwap()을 실행한 thread만 0을 return해 while문을 벗어날 수 있다.
실제로는 이런 식으로 생겼다.

Load-Linked and Store-Conditional
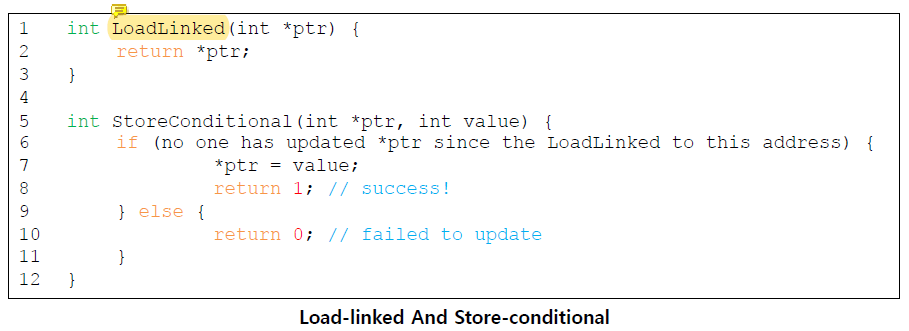 store-conditional은 주소에 대한 intermittent store가 없는 경우에만 성공한다.
store-conditional은 주소에 대한 intermittent store가 없는 경우에만 성공한다.
성공하면 1을 return하고 ptr이 가리키고 있던 값을 value로 update한다.
실패하면 ptr의 값은 update되지 않고 0을 return한다.
LoadLinked를 실행했을 때 해당 variable의 값을 기억하고 그 값이 0인지 1인지 확인한 뒤 값이 modify 됐으면 바꾸려던 값을 바꾸지 않고 그냥 그대로 내버려둔다.


Fetch-And-Add
 특정 address의 old value를 return하면서 atomically하게 value를 1 증가시킨다.
특정 address의 old value를 return하면서 atomically하게 value를 1 증가시킨다.
Ticket Lock
Ticket lock은 fetch-and-add를 통해 만들어질 수 있다.
 모든 thread의 progress를 보장하기 때문에 fairness를 보장한다!
모든 thread의 progress를 보장하기 때문에 fairness를 보장한다!
각 thread가 lock을 획득할 때 atomic하게 ticket값을 1 증가시킨 값으로 서로 다른 myturn을 갖기 때문에 lock을 획득하고자 했던 모든 thread는 순차적으로 기회를 얻을 수 있다.
So Much Spinning
hardware-base의 spin lock은 간단하고 제대로 동작한다.
그런데 어떤 경우에는 spin lock이 상당히 비효율적으로 동작한다.
thread가 spinning을 하게 되면 아무것도 하지 않고 그저 value를 확인하면서 모든 time slice를 낭비한다.
Spinning을 피하기 위해서 OS의 도움이 필요하다!
A Simple Approach: Just Yield
만약 spin을 할 것이라면 CPU를 yield하고 다른 thread에게 주는 것이 낫다.
OS system call이 caller를 running state에서 ready state로 바꿔준다.
하지만 context switch를 하는 데에 드는 cost가 상당하고(substantial, considerable) starvation 문제는 아직도 존재한다.

Using Queues: Sleeping Instead of Spinning
queue는 lock을 획득하려고 기다리고 있는 thread들을 track한다.
park()는 자신을 호출한 thread를 재운다.
unpark(threadID)는 threadID로 지정된(designated) thread를 깨운다.
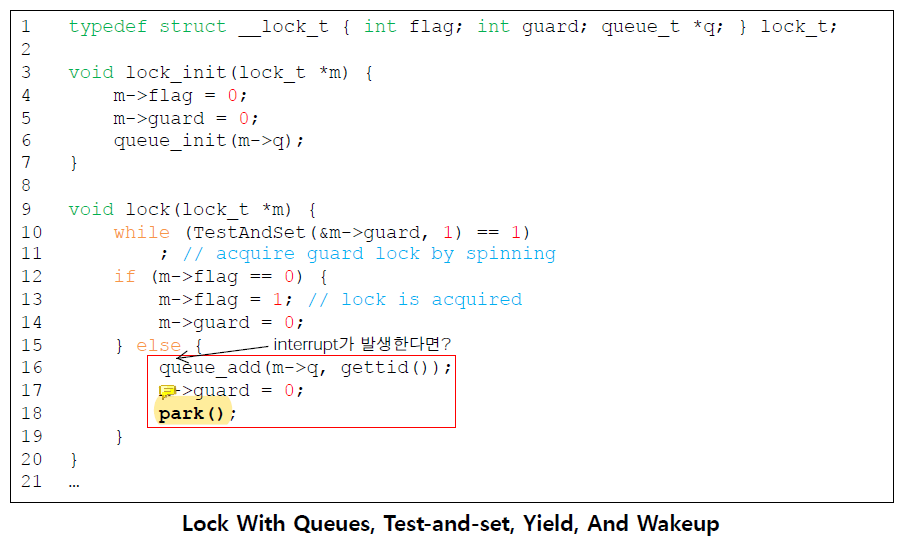 이 예제에서
이 예제에서 m이 guard를 hold하고 잠들면 안된다. 잠을 잘 때 그 어떤 것도 들고 잠에 들면 안된다는 것임!
절대 그 어떤 lock도 holding한 채로 sleep하면 안됨!!!!
위의 TestAndSet()만 atomic하지 나머지는 atomic한 것이 없다.
flag의 state를 확인하는 조건문과 flag의 상태를 바꾸는 부분이 같지도 않고 atomic하지도 않기 때문에 queue에 현재 thread를 추가하기 전에 interrupt가 발생해서 다른 thread가 flag를 확인한다면 queue가 비어있다고 생각하고 기다리는 thread가 없네? 하면서 flag를 0으로 바꿔버린다.
그럼 그 이후에 아까의 thread는 queue에 자신을 넣고 park()하지만... 그 어떤 thread도 잠든 나를 찾을 수 없게 된다.

unlock()에서 lock을 원하는 thread가 있는지 없는지 판단하는 기준이 queue를 확인하는 것이다.
그렇기 때문에 위에서 설명한 문제가 발생한 것이다.
queue가 empty하지 않으면 누군가 이 영역을 사용하려고 기다리고 있다는 것이다.
Wakeup / Waiting Race
위에서 언급했듯, 어떤 thread(B)가 park()를 호출하기 직전에 다른 thread(A)가 lock를 release 해버리면 B는 영원히 잠들게 된다.
Solaris는 이 문제를 setpark()라는 system call을 추가해 해결했다.
 이 routine을 호출하면 그 thread는
이 routine을 호출하면 그 thread는 park()을 하기 직전이라는 것을 나타낼 수 있다.
만약에 interrupt가 발생해서 실질적으로 park()가 호출되기 전에 다른 thread가 unpark()를 호출해도 즉시 잠드는 대신 아래의 park()가 즉시 return 된다.
Futex
Linux는 futex를 제공한다 (Solaris의 park(), unpark() 과 비슷함).
futex_wait(address, expected)futex_wait()은 자신을 호출한 thread가 잠들게 만든다.
만약 address의 값이 expected와 다르면 즉시 return된다 (꿀잠자지 않음).
futex_wake(address)futex_wake()는 queue에서 꿀잠자고 있던 thread를 깨운다.
Two-Phase Locks
Two-phase lock은 lock이 곧 release될 것이라면 spinning이 쓸모있을 수 있다는 사실을 자각했다.
-
First phase
thread는 자신이 lock을 acquire할 수 있을 것이라는 희망을 가지고 잠깐동안 spin한다.
만약 spin phase에서 lock을 획득하지 못한다면 second phase에 들어간다. -
Second phase
caller는 sleep 상태에 놓여진다. caller는 나중에 lock이 free되었을 때만 깨어난다.
