✨Persistence: File Systems
운영체제

File and Directories
File
File은 OS에 의해 생겨난 새로운 abstraction이다.
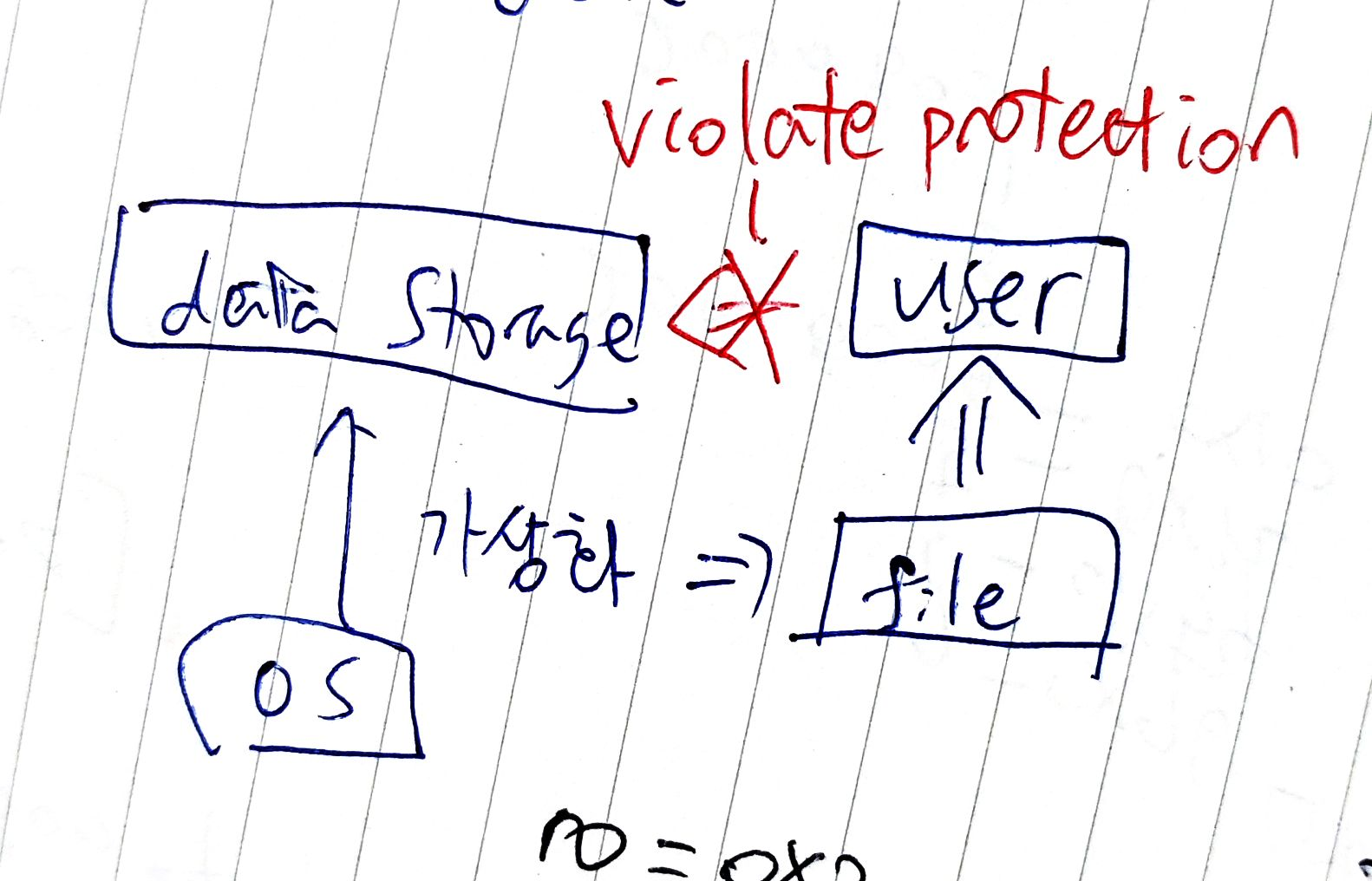 OS는 storage device를 virtualization한 뒤에 뭔가로 그것을 제공해야 하는데 그것이 바로 file이다.
OS는 storage device를 virtualization한 뒤에 뭔가로 그것을 제공해야 하는데 그것이 바로 file이다.
User은 storage device에 direct하게 접근할 수는 없다. protection violation이 일어날 수 있기 때문이다.
User는 file만 보이고 자신의 storage space에 그 file이 있다고 생각한다.
User는 절대 file에 direct하게 access하지 않고, OS가 file system이라는 software layer를 제공하고 file system은 disk, storage virtualization을 제공한다.
 File은 named permanent storage로, data를 안전한 곳에 보존한다.
File은 named permanent storage로, data를 안전한 곳에 보존한다.
그리고 각 file은 inode number의 low-level name이 있다.
Inode는 index node의 줄임말이다. User가 file을 사용할 때는 human-friendly한 string으로 이름을 짓지만, OS 입장에서는 숫자를 사용해 표기하는 것이 훨씬 편하므로 inode number를 사용한다.
User는 inode number를 aware할 수 없다.
Inode는 disk의 각 data block의 address를 담고 있다.
User에게 어떤 file이 있으면 user은 그 file이 contiguous한 byte라고 생각하고, 각 byte가 disk의 어디에 존재하는지는 모른다.
User가 자각하는 것과 OS가 저장한 것 사이의 gap을 메우려면 logical address를 physical address로 translation했던 것처럼 file system에서도 address translation을 해주는 layer가 필요하다.
즉, user가 specify한 address를 disk의 actual address로 translate해줄 layer가 필요하고 그것을 inode structure로 구현하는 것이다.
Data를 store할 때 address를 찾아서 저장한 다음 그 address를 inode에 저장해둔다.
Inode structure은 file system에서 관리하지만 user는 file system을 specify하지 못하고 그저 file에서의 offset만 준다.
이 offset을 가지고 file system(inode)에서 실제 data의 위치를 계산한다.
File은 data를 담고 있는데 그 data에 해당하는 data block을 disk의 어딘가에 저장해둔다.
User은 어떤 block에 자신의 data가 저장됐는지 알 수 없다.
오직 File system만 그 data의 actual position을 알고 있고, 그것이 inode structure로 관리된다.
File에는 이런저런 metadata도 있다.
File system은 data를 disk에 persistent하게 저장해야하는 책임이 있다.
Persistent Storage
 File은 user data와 metadata를 담고 있는 abstraction이다.
File은 user data와 metadata를 담고 있는 abstraction이다.
Directory는 OS가 data를 찾을 수 있도록 guide해준다.
이 directory structure는 user에게도 export돼서 user가 자신의 storage system을 hierarchical way든 flat way든 자기가 원하는 대로 organize할 수 있다.
Directory
 Directory는 이름이 필요하다. File을 찾아야하기 때문이다.
Directory는 이름이 필요하다. File을 찾아야하기 때문이다.
Directory는 user에게 export돼서 user가 자신의 directory structure를 human-friendly한 name을 통해 organize할 수 있기 때문에 directory는 이름이 필요하다.
Directory Tree (Directory Hierarchy)

요약
File은 OS가 storage devices를 virtualize하기 위해 사용하는 중요한 abstraction이다.
Storage devices는 user data를 durably하게 store해야하는 아주 중요한 역할이 있다.
Durably는 user가 confirm하거나 storage system에 write되는 data는 어떤 failure에도 살아남아야 함.
File은 user process에게 제공되어야 하는 abstraction이고 user process는 file이 named storage의 single byte array라고 생각한다.
User process는 user defined name을 통해 file에 access한다.
OS는 storage를 virtualize하기 위해 2개의 중요한 abstraction을 제공해야한다, file과 directory.
Directory는 user process가 file의 location을 찾기 위해 필요한 mechanism이다.
User은 자신의 file을 directory structure로 볼 수 있고 만약 single flat directory를 사용한다면 자신의 file을 single huge directory에 넣을 것이고 tree같은 hierarchical structure를 사용해 자신의 file을 organize할 수도 있다.
OS은 file과 directory를 manage하는 special layer가 필요하다. 그것을 file system이라고 부른다.
File system은 user-defined file, user-created file, directory를 내부적으로 manage하고 file system이 number를 사용해 file과 directory를 찾기 위해 사용할 수 있는 mapping structure를 maintain하는 software layer이다.
User은 human friendly name의 string을 사용하지만 file system은 그 string을 number로 transform하는 것이 더 효율적이다.
File System Implementation

The Way to Think
 File system은 2개의 important structure가 필요하다.
File system은 2개의 important structure가 필요하다.
여기서 사용하는 data structure은 user에 의해서 보여지거나 access될 수 없다.
OS, file system layer은 user data(file)를 organize하기 위한 data structure를 internally 가지고 있다.
Access method는 user process에게 export되어야 하는 method이고 user process는 file을 read, write, open, delete하기 위해 모든 access method를 invoke할 수 있다.
Overall Organization
 File system이 사용하는 data structure은 3개의 중요한 component를 사용한다.
File system이 사용하는 data structure은 3개의 중요한 component를 사용한다.
- Data region
- Metadata (data block의 location을 identify하기 위해 사용해야함)
- Super block, bitmap (to manage free space)
Super block, inode bitmap, data block bitmap, inode structure, data region은 모두 fix된 것이다.
Data block의 size를 decide하면 system은 얼마나 많은 data block을 file system이 이 storage device에 store할 수 있는지, 얼마나 많은 inode가 data block의 location을 담기 위해 필요한지 자동으로 결정한다.
Data block의 개수를 decide하면 free inode와 free data block을 기억하기 위해 필요한 bitmap의 개수를 fix할 수 있다.
Data Region in a File System
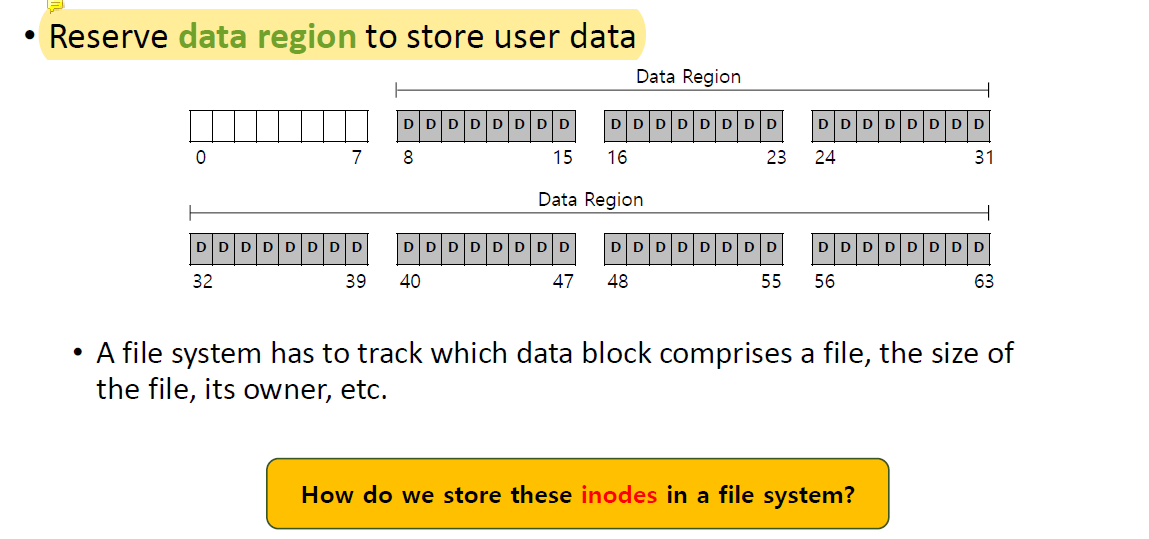 전체 disk를 data region으로 사용할 수는 없다. 그럼 address를 저장할 공간이 없기 때문이다.
전체 disk를 data region으로 사용할 수는 없다. 그럼 address를 저장할 공간이 없기 때문이다.
Address는 inode structure에 저장된다.
disk space의 특정 부분을 data region으로 reserve해서 사용한다.
전체 block을 어떤 format(particular unit size, data block size)으로 initialize했는지에 따라 달라진다.
Huge block size를 이용한다면 data region으로 사용 가능한 space가 커지겠지만 엄청 작은 block size를 사용한다면 모든 disk block을 track하기 위한 inode의 수가 증가하면서 inode를 위해 더 많은 공간을 reserve해야한다.
Inode Table in File System
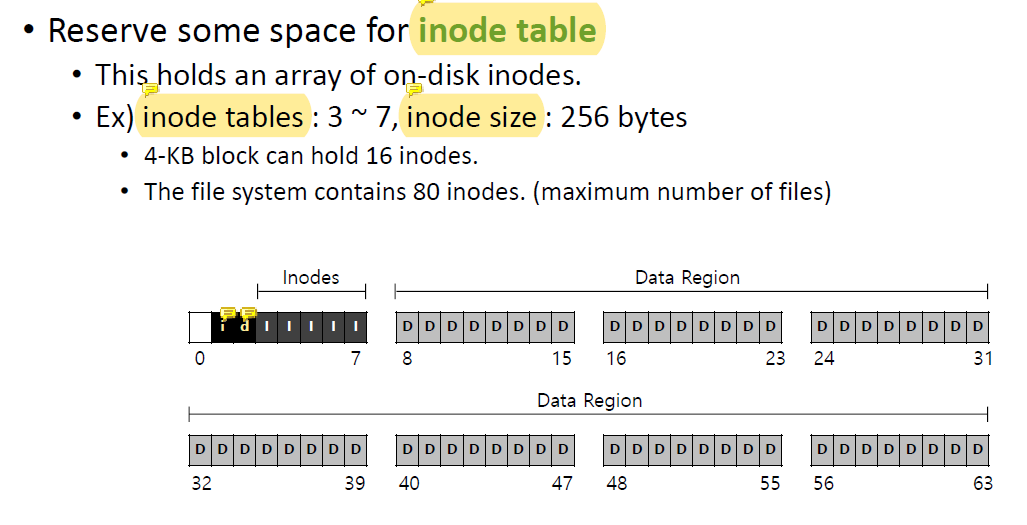 Inode table을 위한 공간을 reserve 해야한다.
Inode table을 위한 공간을 reserve 해야한다.
Inode table로 모든 data block을 track 해야한다.
Small block size를 이용한다면 모든 data block을 track하기 위해 필요한 inode의 수가 증가한다.
그 말은 data region으로 사용할 수 있는 공간이 줄어든다는 것이다.
큰 size의 block은 큰 file을 저장하는 데에는 좋지만 작은 file을 저장하게 되면 internal fragmentation이 발생한다.
Inode table은 data block의 address를 hold하고 있고 inode size는 configuration에 따라 달라질 수 있다.
Allocation Structures
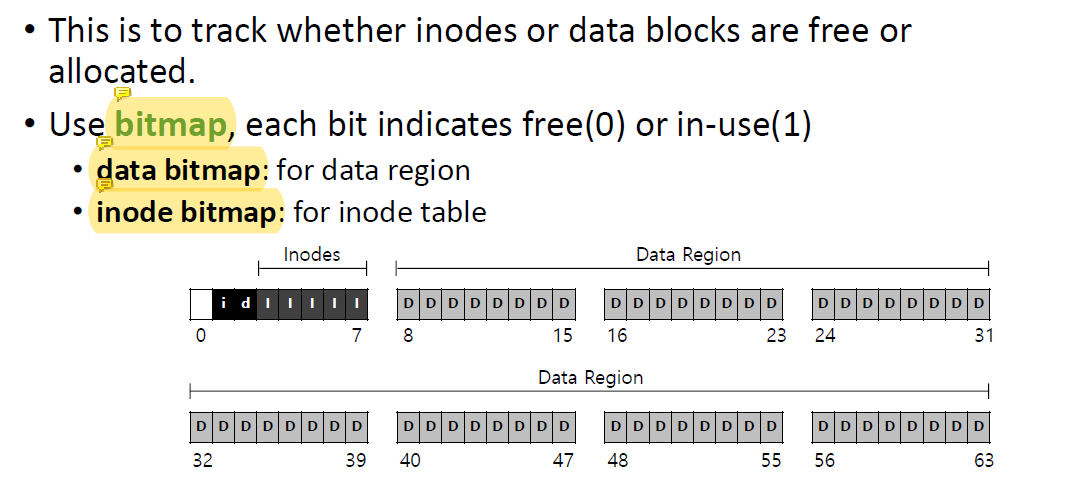
Bitmap은 어떤 block이 사용중이고 어떤 block이 free인지 나타낸다.
-
Data bitmap: data region을 위한 것이다.
inode bitmap보다는 살짝 큰데 free space를 track한다.
어떤 data block이 free되고 어떤 data block이 사용되는지 표시한다. -
Inode bitmap: inode table을 위한 것이다.
어떤 inode block이 현재 사용중이고 free됐는지 나타낸다.
Superblock
 Superblock은 file system에 대한 information을 담고 있다.
Superblock은 file system에 대한 information을 담고 있다.
Superblock은 전체 file system을 consistence하게 유지하는 데에 필요하다.
어떤 failure가 발생한다면,
예를 들어 disk에 data는 store됐는데 새로운 data의 주소가 inode table에 update되지 않았다던가 하면 inconsistency가 발생한다.
이러한 문제를 해결하려면 metadata가 필요한데, 그 metadata가 superblock에 저장된다.
File Organization: The inode
 User process가 어떤 data를
User process가 어떤 data를 write() system call을 통해 저장하면 자신의 data를 data block(data region)에 저장한다.
Data를 data region에 저장하면 그 data의 location을 어딘가에 저장해야한다.
그것이 inode block을 통해 이루어진다.
Data를 저장하면 그 data block의 location(data block의 number같은 것)을 알게 되고 그것을 inode block에 저장한다.
inode block을 store하고 나면 끝난 것이다.
그 inode는 high-level directory structure에 store된다.
그리고 directory나 file name이 자신의 inode block을 가지고 있고 그리고 거기에 actual data의 location이 있다.
inode number를 알게 되면, file system은 human friendly string(name)을 사용하지 않고 inode number만 사용한다, 그 inode block의 location은 너무 명확하다.
inode block의 number은 이 file system에서 이미 fix되어있고 이 storage device의 total number of data block 역시 이미 fix되어있기 때문이다.
32라는 inode number를 얻기만 하면 inode block의 위치를 쉽게 계산할 수 있다.
위의 예시를 보면 super block, inode bitmap, data bitmap이 각각 4KB를 차지한다.
따라서 3개의 data disk block은 reserve되어있다.
OS는 내부적으로 inode block에 대해 fixed size를 사용하므로 inode의 size가 256bytes이고 32번째 inode block이므로 32 * 256 = 8KB을 구할 수 있다.
Final location이 8KB이다.
1 single inode block의 크기가 4KB인데 그 안에 16개의 inode가 있다. 그래서 2개의 data disk block을 더 skip 해야한다.
그리고 바로 그 다음에 나오는 처음 256bytes의 inode가 32번째 inode structure가 될 것이다.

sector는 hard disk drive에 쓰이지만 여기서는 다루지 않는다.
이것은 block interface를 이용해서 어떻게 inode block을 얻는지를 보여주는 예시이다.
SSD와 hard disk는 내부적으로 block device이기 때문에, 그들이 I/O device로 computer system에 연결되고 나면 그들의 canonical interface(status register, command register, data register)를 export하고 그들의 device number를 export하면 OS는 I/O device driver를 사용해서 read()나 write()같은 command를 특정 block number에 보낸다 (byte address로 보내는게 아님!!!).
그래서 OS는 disk로부터 entire inode block을 읽기 위해 block number가 필요하다.
Block number(blk)만 구하면 canonical interface를 통해 I/O interface에게 command를 보내고 hard disk나 ssd에게 canonical protocol을 보낸다.
SSD가 그 command를 OS로부터 가져오면 SSD는 자신의 device로부터 data block을 fetch하고 그들이 DMA를 통해 그것을 OS에게 보낸다.
The Multi-Level Index

256bytes의 single inode 내부에는 block number(blk)에 맞는 block address에 대한 12개의 4byte entry가 있다.
User data의 location을 identify하기 위한 pointer인 셈이다.
User가 certain file offset을 read/write하려면 file system이 내부적으로 그 offset을 entry를 통해 block number로 translate한다.
File system이 inode structure로부터 data block number를 얻게 되면 disk의 block에 access할 수 있다.
File system은 OS의 일부분이다. 그래서 device에 directly하게 access할 수는 없다.
Location에 대한 information을 얻으면 그 location(block number)을 이용해서 canonical interface를 통해 device에게 command를 보낸다.
inode는 direct pointer라고 불리는 address pointer를 갖는다.
Space limitation으로 인해 single inode는 12개의 direct pointer를 갖는다.
각 pointer는 4KB block을 cover할 수 있다. 따라서 12 * 4 KB block을 커버할 수 있는 것이다. 상당히 작다.
만약 user가 huge file을 생성한다면 single inode가 그 file의 entire range를 커버할 수 없게 된다.
그래서 inode는 12개의 direct pointer와 1개의 indirect pointer를 가진다.
Indirect pointer는 inode structure만 담고 있는 block number를 가리킨다.
4KB block 1개에 1024개의 block number를 넣을 수 있다.
Single block number가 4bytes이기 때문이다.
그래서 이것을 indirect pointer라고 한다.
Direct pointer로는 block number를 data block으로 해석할 수 있다.
하지만 indirect pointer는 C의 pointer structure처럼 single block number로 해석되지만 그 block은 다른 block number만 담고 있다.
그래서 indirect pointer는 또 다른 1024 * 4KB = 4MB space를 cover한다.
정리하자면,
(12 * 4KB) + (1024 * 4KB)=(12 + 1024) * 4KB=4144KB
하지만 one single indirect pointer가 있더라도 user는 4MB 이상의 file structure를 만들 수 없다.
이를 극복하기 위해 inode structure에 double indirect pointer, triple indirect pointer가 사용되기 시작했다.

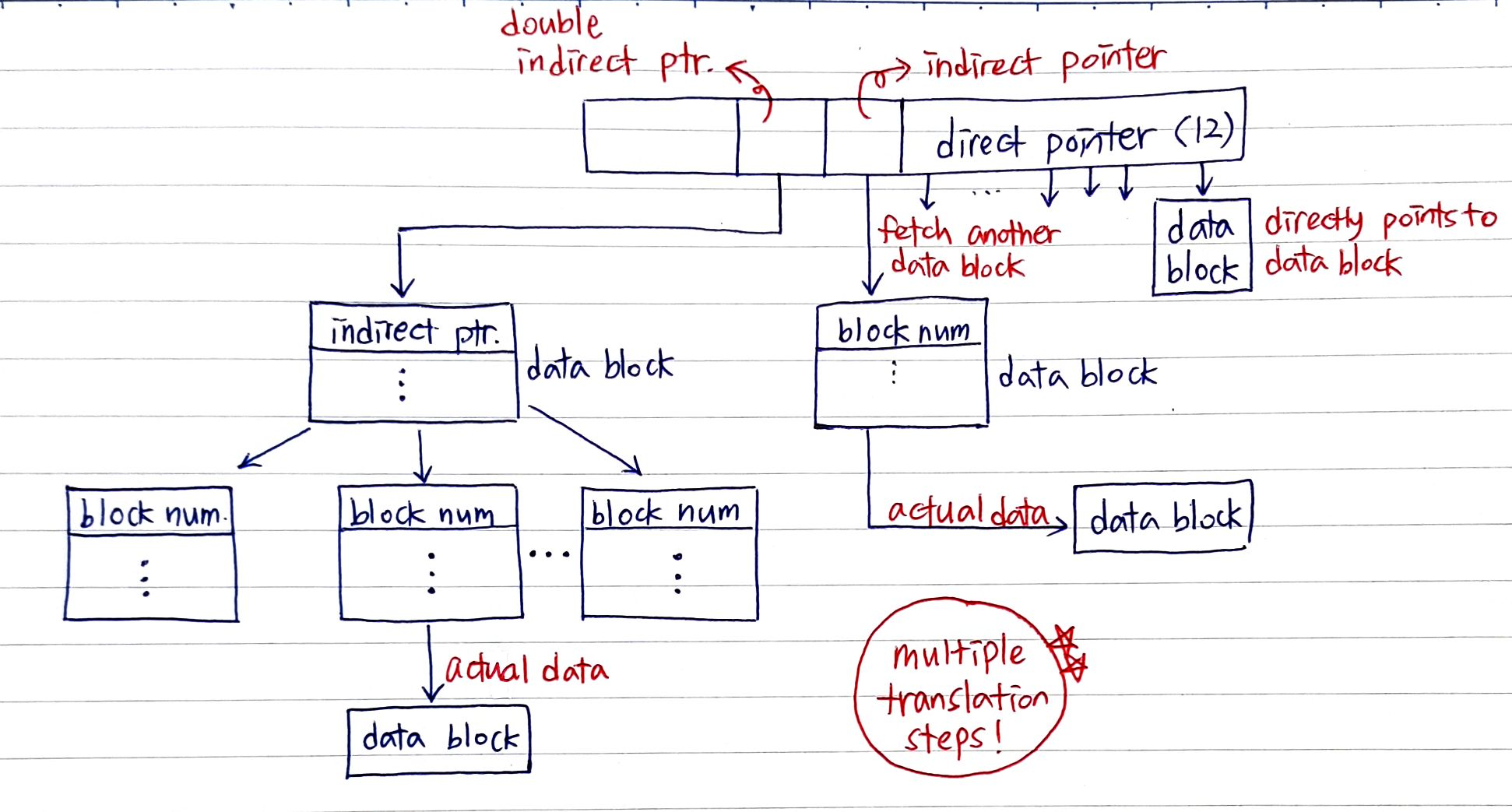 Direct, indirect, double indirect, triple indirect을 쓰면 huge size of file을 cover할 수 있다.
Direct, indirect, double indirect, triple indirect을 쓰면 huge size of file을 cover할 수 있다.
이것이 file system이 size limitation을 극복하는 방법이다.
User가 크기가 큰 file을 create하는 경향이 있으면 OS는 single, double indirect pointer만 사용해서는 user request를 충족하지 못할 수 있다.
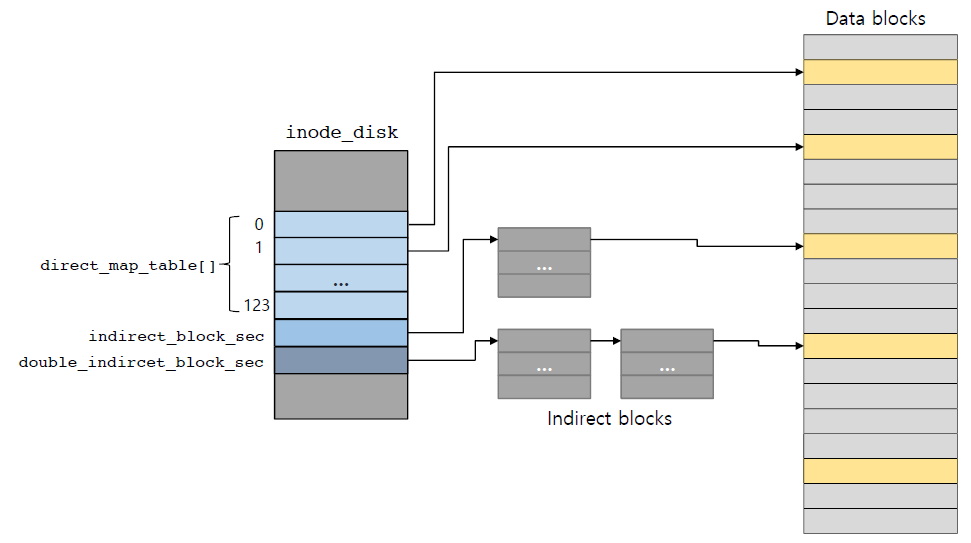 마치 multi-level paging같은 느낌이다.
마치 multi-level paging같은 느낌이다.

Directory Organization

Free Space Management
 Free space는 inode bitmap과 data bitmap으로 manage된다.
Free space는 inode bitmap과 data bitmap으로 manage된다.
Access Paths: Reading a File From Disk

Location "/foo/bar"은 user(human)-friendly directory structure이다.
User process는 human-friendly directory structure만 제공한다.
이것을 directory path라고 한다.
우리는 open() system call에 path를 제공하고 user process로부터 path를 받으면 OS는 그것을 number로 해석한다.
OS는 pathname을 traverse해서 bar file의 desired inode를 찾아야 함.
이 sequence는 file system의 root(/)부터 시작된다.
그리고 /는 보통 fixed inode number를 갖고 있고 그건 2번이다.
그래서 file system은 inode number 2가 있는 block을 읽고 그리고 그 inode number를 통해 data block을 가리키는 pointer를 찾는다.
여기서는 root directory를 가리키는 포인터를 찾게 된다.
Root directory가 찾아지면 그 directory structure를 읽는데 directory structure는 multiple file이나 다른 directory를 가지고 있다.
Directory block도 data block 안에 저장되어 있다!
User process는 자신의 file이나 directory structure를 inode structure에 장할 수 없다.
inode structure는 data block의 location을 identify할 때만 사용한다!
Directory는 user에게 export된 abstraction이므로 user-defined structure이다. 일종의 location router.
그래서 directory는 반드시 data block에 저장되어야한다!
그 data block의 location이 inode에 저장되는 것!
그 inode가 root directory structure에 저장되어 있다!
Data block에 access해서 root directory를 찾아서 one or more data block을 읽으면 foo directory를 찾게 됨.
그럼 다시 traverse해서 foo directory에 대한 information을 찾아내고 그 다음에 bar file을 찾게 됨.
foo directory는 bar file에 대한 metadata를 갖고 있다.
foo directory의 data block에서 bar 이름을 가지고 bar inode를 찾으면 그 inode를 가지고 bar에 access할 수 있다.
 File을 open하면 file descriptor가 return되는데 그것으로
File을 open하면 file descriptor가 return되는데 그것으로 read() system call을 발생시켜서 file system이 bar file에 access해 data를 읽고 last accessed time (in inode structure for bar file)같은 metadata를 update한다.
그 이후에 close() system call 같은걸 호출하거나 또 다른 write(), read() system call을 호출할 수 있다.
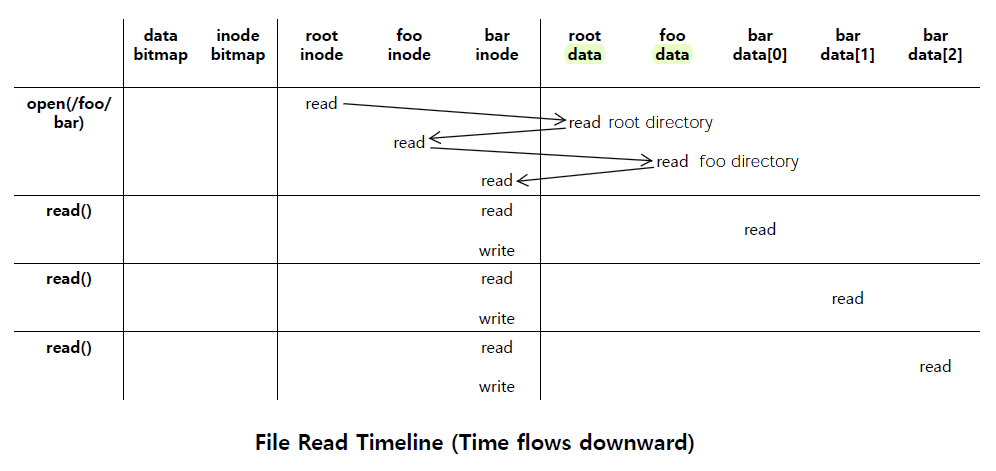
open() system call이 실행되면 가장 먼저 root inode를 읽어야 한다.
root inode에 접근하면 root directory에 해당하는 data block을 가져와야 한다.
root directory에 접근하면 root directory는 multiple directory나 multiple file을 담고 있을 수 있고 root directory data를 읽으면 foo를 찾을 수 있다.
foo를 찾으면 거기에 string foo 옆에 inode number가 쓰여 있을거고 그 foo inode(foo directory를 위한 inode)를 읽으면 foo directory를 읽을 수 있다.
foo directory는 bar의 inode number를 갖고 있다. 그럼 그걸로 bar의 inode를 찾을 수 있다.
이것이 open() system call의 과정이다.
open() system call은 그냥 access해서 bar file에 대한 inode number를 retrieve한다.
bar file이 foo directory에 존재하는지 아닌지 확인하고 존재하지 않는다면 error를 return하고 존재한다면 그 inode structure를 load해서 file descriptor(fd)를 return한다.
fd가 있으면 bar file에 대한 inode를 알고 있는 것이므로 file system은 directly하게 bar의 data block에 access할 수 있다.
read() system call은 항상 제일 처음부터 data를 fetch하려고 하기 때문에 bar에 속해있는 first data block부터 읽는다.
그리고 last accessed time metadata를 bar inode에 쓴다 (update).
File system은 storage device에 직접적으로 data를 쓰지 않는다!
항상 I/O interface를 사용한다.
I/O를 할 때마다 항상 canonical interface/canonical protocol을 통해 command를 보낸다.
Access Paths: Writing to Disk

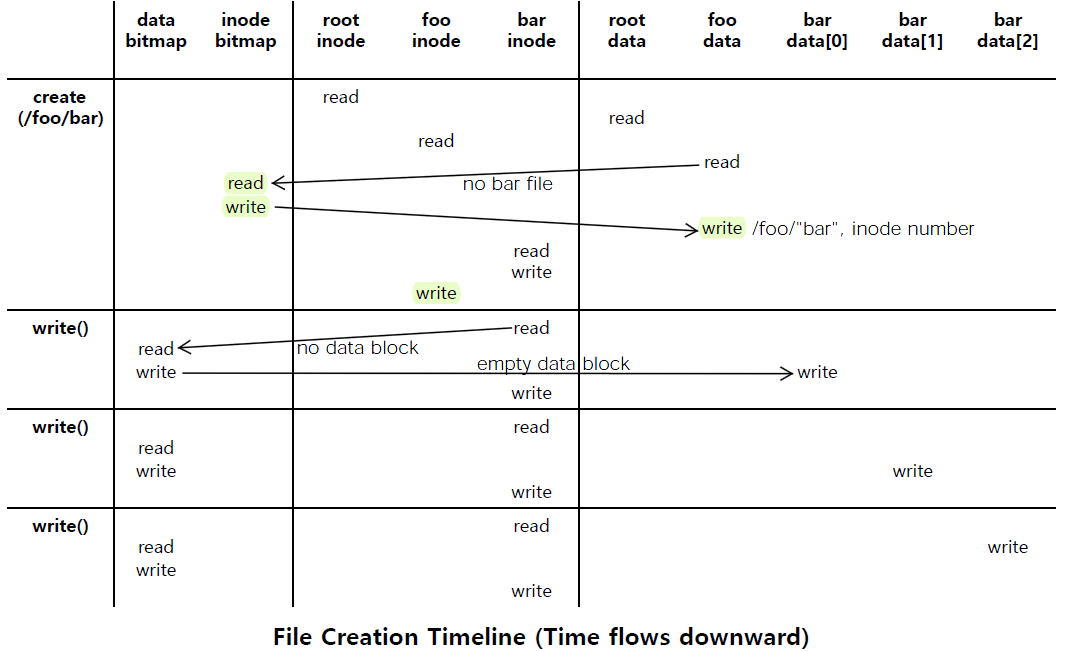
bar file을 생성하는 과정을 살펴보자.
가장 먼저 inode를 읽고 root directory data를 읽는다.
그리고 거기서 foo를 찾으면 foo inode를 읽어서 foo의 data(directory)에 access한다.
그리고 foo directory에 bar file이 없으면 file system은 inode bitmap으로 돌아온다.
bar file을 새롭게 생성해야하기 때문이다.
New file을 새로 생성하는 것은 실제로는 data를 write하는 것이 아니다.
File을 create하는 자체는 그 어떤 writing operation을 수행하지 않기 때문이다. 쓸 data가 없으니까.
그래서 inode bitmap만 update한다.
새로운 file을 생성한다는 것은 그 file을 위한 새로운 inode structure가 필요하다는 의미이기 때문이다.
그래서 inode bitmap을 읽고 bar을 위한 새로운 inode를 allocate한다.
그럼 inode bitmap이 반영돼서 bar inode가 allocate되고 update된다.
그럼 bar의 이름과 inode number를 foo의 directory data block에 저장하게 된다.
그럼 bar file을 위한 inode를 읽을 수 있고 creation time과 같은 중요한 metadata를 기록한다.
그리고 foo의 inode를 update한다. 새로운 file이 생성돼서 foo directory가 그 file을 담게 되었기 때문이다.
그래서 foo의 inode가 access되고 access time과 관련된 metadata가 update된다.
File을 생성하고 나면 return되는 fd를 통해 write() system call을 호출하고 이미 bar inode를 알고 있기 때문에 bar inode를 읽는다.
그런데 file system에서 new data를 읽는거라 data block이 없으므로 이를 먼저 allocate 해야한다.
그래서 data bitmap으로 돌아가서 data bitmap을 읽고 empty data block을 찾기 위해 data bitmap을 update하고 비어있던 new data block으로 가서 새로운 information(user data)을 write한다.
그 new data block이 bar의 data block이 된다.
그러면 user buffer에 있던 content가 bar의 data block에 쓰인다.
그 후 다시 bar inode로 돌아와서 metadata를 바꾼다. 수정시간 같은거.
이 과정이 매우 중요하다.
만약 new data를 allocate하지 않으면 아무것도 write할 수 없다.
항상 new data block에 write하기 위해서 data bitmap을 update해야한다.
그렇지 않으면 어디에 data를 써야할지 알 수 없다.
Data block의 location을 알기 위해서 가장 먼저 data bitmap에 visit해야하고 그리고 free data block을 찾아서 data block number를 가지고 data를 적는다.
data block number를 가지고 write을 끝냈으면 그 data block을 bar의 inode에 저장해주어야 한다.
그러면 inode structure는 정확하게 data block의 number를 기억할 수 있다.
Reading, writing의 sequence와 어떻게 file system이 내부적으로 user process에게 export한 method를 process하는지 잘 알아야 한다.
Caching and Buffering


