RNN 문제점 해결
Transformer 특징
Long-term dependency problem
-
어떤 정보와 다른 정보 사이의 거리가 멀 때 해당 정보를 이용하지 못하는것 -> RNN의 문제점
-
Attention 메커니즘으로 문장을 한번에
모두 봄으로써 문제를 해결
Parallelization
-
RNN은 이전 hidden state를 사용함으로써
순차적으로 계산이 되어야함(병렬화 불가능) -
Transformer는 RNN이 아니라
행렬 병렬연산으로 빠르게 학습 가능
Transformer
-
CNN이나 RNN을 사용하지 않고, Attention mechanism 만으로 시계열 데이터의 인코더-디코더 구조를 설계
-
RNN은 메커니즘 상 순차적으로 처리해야 하는 반면
attention은 병렬 처리가 가능하고 GPU 등을 통해 학습 시간을 크게 단축함 -
Multi-head Attention의 도입으로 복합적 문맥 이해 능력이 크게 향상됨
-
자연어 처리에 있어 혁신적인 페러다임의 변경
인코더에서 알아야 할 핵심 개념
-
Self attention
-> 단어의 맥락적 의미 추출 -
Multi-head attention
-> 다양한 관점에서 맥락 고려 (self attention 여러개) -
Positional encoding
-> seq data의 특성을 살리기 위한 위치 정보 update
Encoder
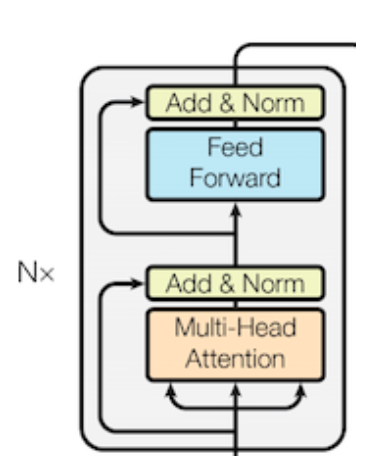
-
Encoder : 입력시퀀스의 데이터 정보 추출
-
트랜스포머는 하이퍼파라미터인 N 개의 인코더 층을 쌓음
- 논문에서는 6개의 층
- Multi-Head Attention -> Residual connection -> Layer Normalization -> Feedforward -> residual Connection-> Layer Normalization
-
하나의 인코더 층에는 Self-Attention과
Feed Forward 신경망으로 구성 (핵심) -
Multi-Head Attention
- Self-Attention을 병렬적으로 사용했다는 의미
-
성능 향상을 위해 residual learning 사용
= skip connection (성능을 위한)
Encoder - Self Attention
셀프 어텐션을 통해 얻을 수 있는 대표적인 효과
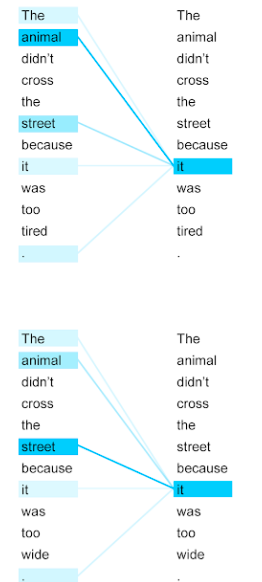

-
셀프 어텐션은 입력 문장 내의 단어들끼리 유사도를 구해서, 그것(it)이 동물(animal) 혹은 길(street)과 연관되었을 확률이 높다는 것을 찾아냄
-
Q, K, N 이 다 자기안에 있기 때문에 Self Attention
-
attention -> Q 의미와 가장 유사한 의미를 가진 정보를 K를 통해 가중치를 찾아 V를 융합
-
self-attention -> 문장안에서 단어의 의미는 그 문장의 다른 단어를 통해 알 수 있다
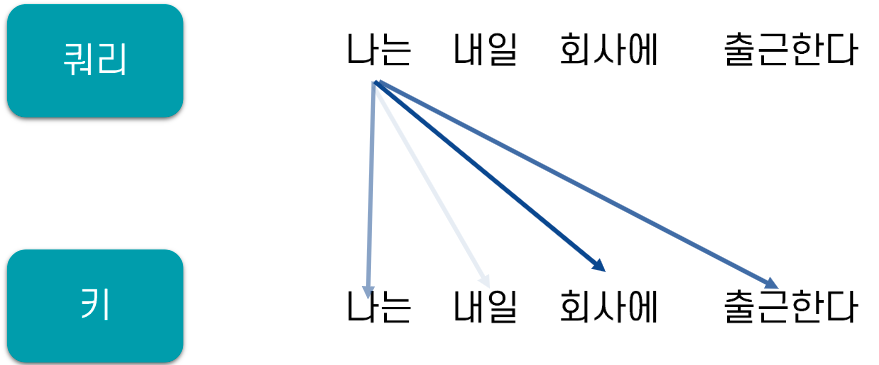
Self-Attention :
입력문장에서 각 단어가 어떤 단어와 연관성이 높은지 계산
Q = K = V : 입력 문장의 모든 단어 벡터들 ( 다 같다)
Multi-Head Attention
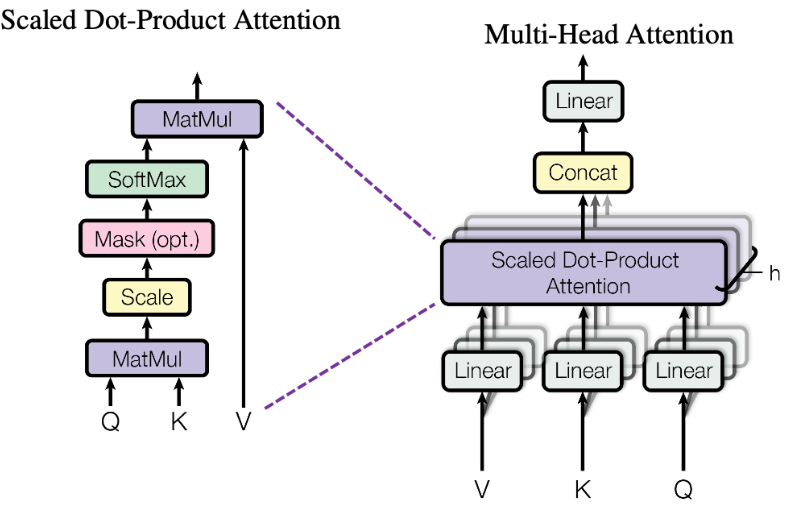
-
논문에서는 한 번의 어텐션을 하는 것보다 여러 번의 어텐션을 병렬로 사용하는 것이 더 효과적이라고 판단
-
dmodel의 차원을 num_heads개로 나누어
dmodel/num_heads의 차원을 가지는 Q, K, V에 대해서
num_heads개의 병렬 어텐션을 수행
-> 예를 들어 dmodel = 267, heads =8
-> 각 32차원의 Q, K, V
-> 32차원의 attention 정보 -
병렬 어텐션을 모두 수행하였다면 모든 어텐션 헤드를 연결(concatenate)
-
서로 다른 Head는 문장 내의 서로 다른 관계를 배울 수 있음
-
Multi-Head Attention은 서로 다른
Query, Key, Value 행렬들과 선형 변환함
Position-wise Feed-Forward Networks
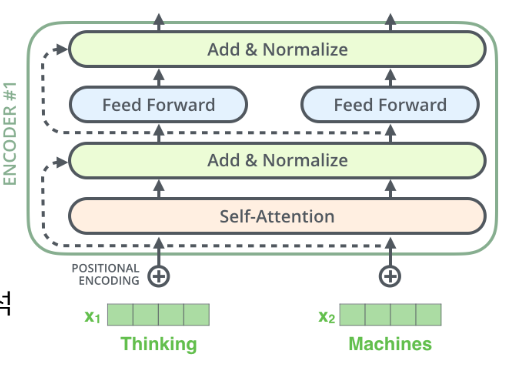
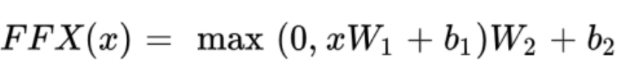
-
쉽게 말하면 완전 연결 FFNN(Fully-connected FFNN)
이라고 해석 (FC Layer) -
x : 멀티 헤드 어텐션의 결과, (seq_len, dmodel)행렬
-
W1 : 가중치 행렬 (dmodel, dff)
-
W2 : 가중치 행렬 (dff, dmodel)
- 논문에서 dff는 2048, dmodel은 256
(트랜스포머의 인코더와 디코더의 정해진 입출력크기)
- 논문에서 dff는 2048, dmodel은 256
-
여기서 매개변수 W1,b1,W2,b2는 하나의 인코더 층 내에서는 다른 문장, 다른 단어들마다 정확하게 동일하게 사용되지만, 인코더 층마다는 다른 값을 가짐
-> Weight Share = 똑같은거 돌려 사용..
Positional Encoding(Embedding)
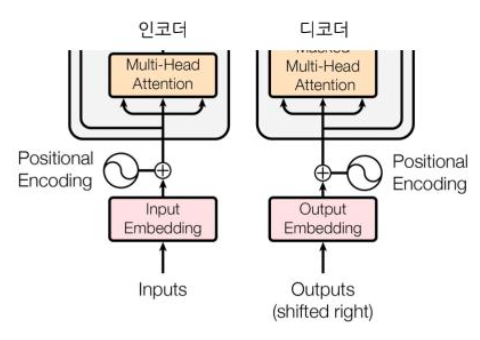
-
Data에 Seq(순서)정보 추가하는 것
-
트랜스포머는 단어의 위치 정보를 얻기 위해서
각 단어의 임베딩 벡터에 위치 정보들을 더하여
모델의 입력으로 사용 -
RNN이 자연어 처리에서 유용했던 이유는
단어의 위치에 따라 단어를순차적으로 입력받아서
처리하는 RNN의 특성으로 인해 각 단어의 위치 정보
(position information)를 가질 수 있다 -
트랜스포머는 단어 입력을 순차적으로 받는 방식이 아니다
-
따라서, 단어의 위치 정보를 다른 방식으로 알려주어야 한다
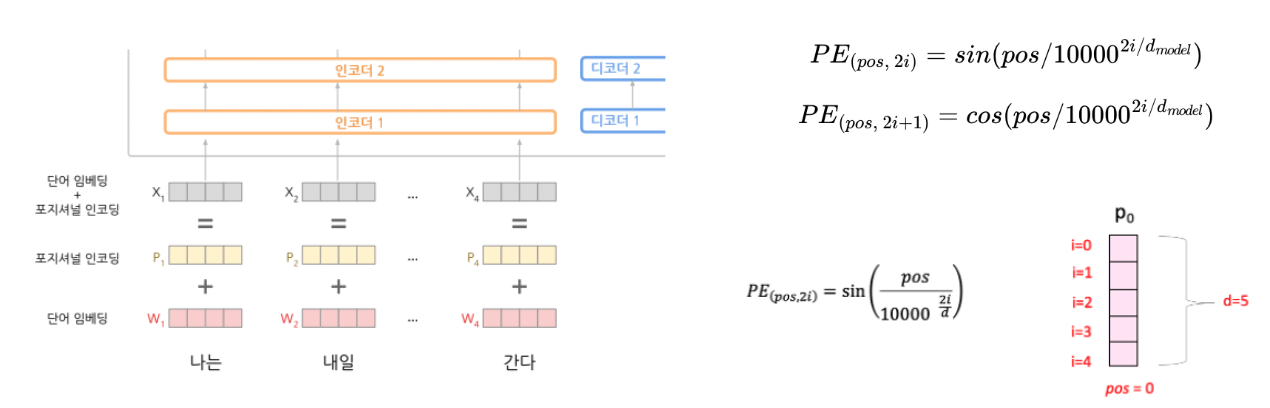
-
입력으로 사용되는 임베딩 벡터들이 트랜스포머의 입력으로 사용되기 전에 포지셔널 인코딩의 값이 더해진다
-
위치(Position)에 대한 절대적 위치를 표현하는 것이 아니라 대변 할 수 있는 encoding
-
포지셔널 인코딩을 학습시킬 수 있지만, 고정된 벡터여도
학습의 질에는 큰 차이가 없다는 것을 논문 저자가 밝힘 -
위치(Position)에 대한 unique한 벡터가 생성됨
-> 동일 위치는 같은 벡터가 생성된다
Decoder
Masked Muti-Head Attention
-
디코더 학습에서 다음 단어의 Attention을
고려하지 못하도록 Masking -
마스킹 된 후의 어텐션 스코어 행렬의 각 행을 보면
자기 자신과 그 이전 단어들만을 참고할 수 있음
