Seq2Seq 란?
-
시퀀스-투-시퀀스 는 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에서 사용되는 모델
-
고정된 차원의 입력을 받아, 입력값에 대응하는
"가변적 길이의" 결과값을 출력하는 모델 -
챗봇(Chatbot)과 기계 번역(machine Translation),
STT(Speech to Text) 등 다양한 분야에서 활용
-
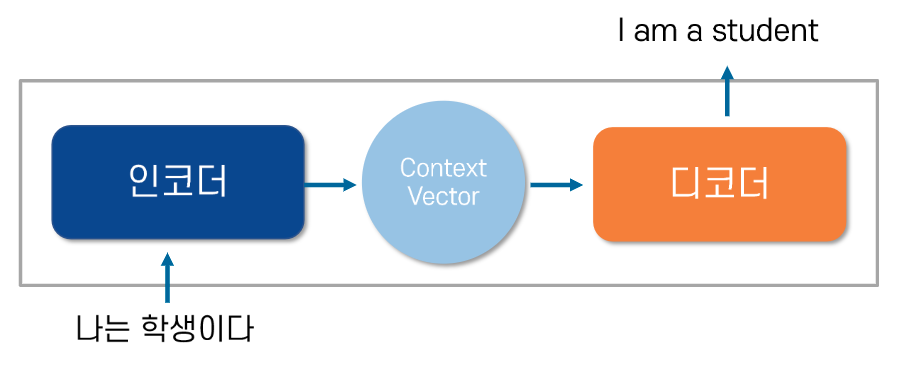
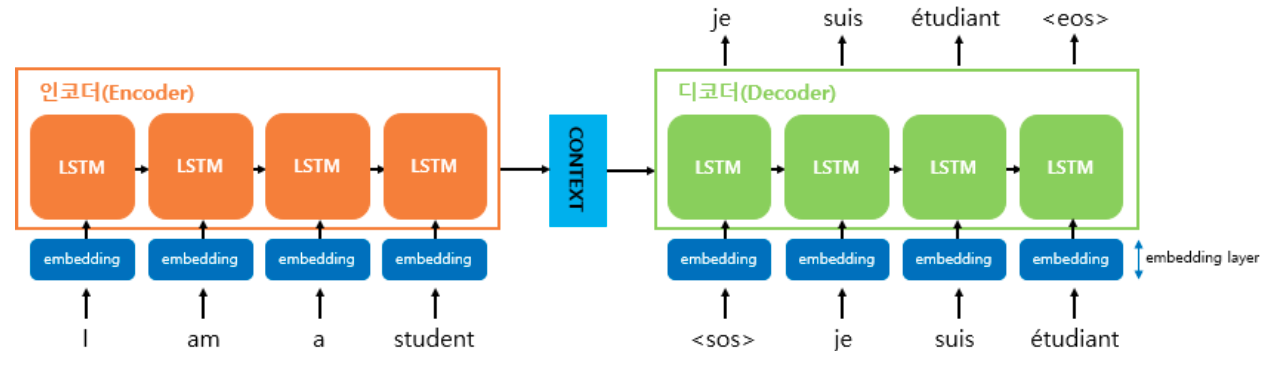
Seq1Seq는 크게 인코더와 디코더라는 두 개의 모듈로 구성
-
인코더는 입력 문장의 모든 단어들을 순차적으로
입력받은 뒤에 마지막에 이 모든 단어 정보들을 압축해서 하나의 벡터로 만듦 -> 컨텍스트 벡터(context vetor) -
디코더는 컨텍스트 벡터(인코더에서 생성된 상태)를
받아서 번역된 단어를 한 개씩 순차적으로 출력
-
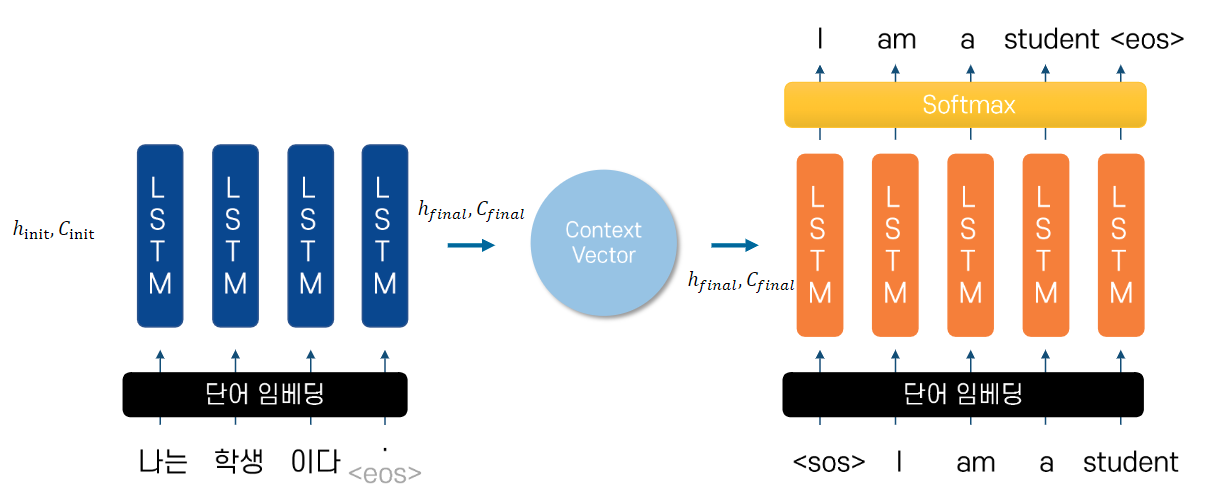
eos : 문장의 끝 / sos : 문장의 시작
-
인코더 아키텍처와 디코더 아키텍처의 내부는
사실 두 개의 RNN 아키텍처 -
입력 문장을 받는 RNN 셀을 인코더라고 하고,
출력 문장을 출력하는 RNN 셀을 디코더라고 함
Encoder
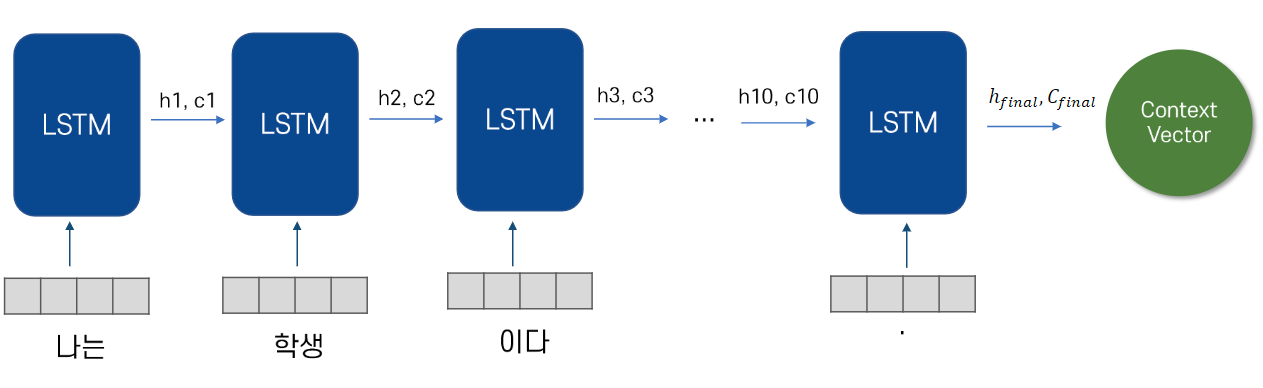
-
입력 문장은 단어 토큰화를 통해서 단어 단위로 쪼개지고
단어 토큰 각각은 RNN 셀의 각 시점의 입력이 됨- LSTM 기준으로 hidden state와 cell state,
GRU의 경우에는 hidden state만 추출
- LSTM 기준으로 hidden state와 cell state,
-
인코더 RNN 셀은 모든 단어를 입력 받은 뒤,
인코더 RNN 셀의 마지막 시점의 은닉 상태를
디코더 RNN 셀로 넘겨줌 -> 이를 컨텍스트 벡터라고 함 -
Encoder
= 문장의 의미를 압축해서 content vector를 만들어 내는 것 -
padding이 앞이면 좋다
Decoder
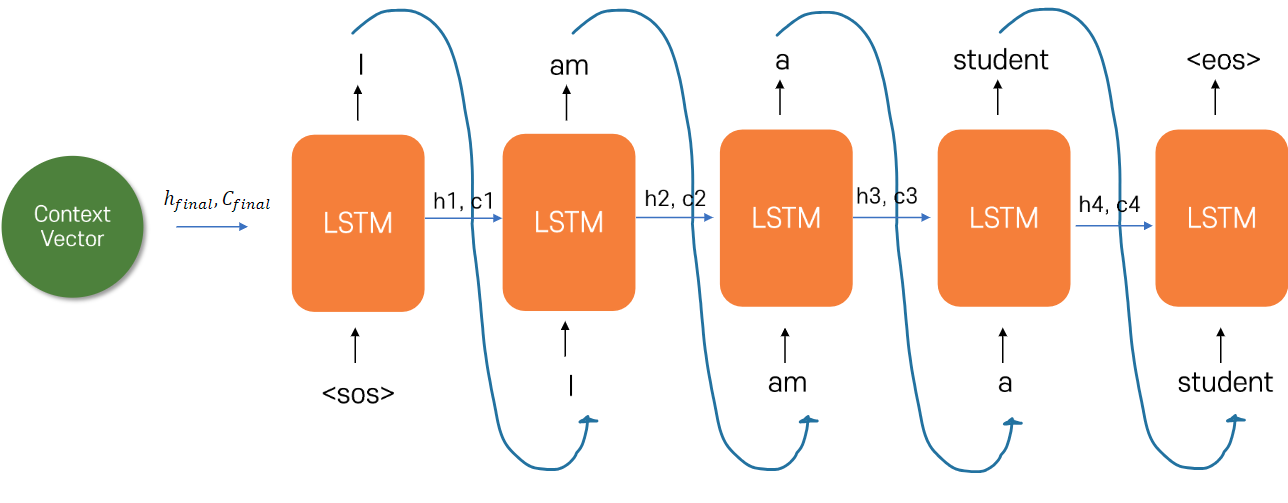
-
디코더는 인코더에서 추출한 초기 상태를 받아
LSTM으로 순차적으로 결과를 출력해주는 파트 -
반복은 하되, EOS 토큰이 출력되면 끝남
-
EOS가 나오면 반복 생성을 끝낸다
-
padding이 뒤면 좋다
인코더와 디코더를 분리하면서 생긴 효과
-
인코더와 디코더가 다른 도메인이여도 가능하다
- ex)
분리가 안되면 = 음계를 넣으면 음계가 나옴
분리가 되면 = 한국어를 넣으면 영어가 나올 수 있음
- ex)
Seq2Seq 학습 - Teacher Forcing
-
훈련 과정에서는 이전 시점의 디코더 셀의 출력을
현재 시점의 디코더 셀의 입력으로 넣어주지 않고,
이전 시점의 실제값(target)을 현재 시점의
디코더 셀의 입력값으로 하는 방법을 사용- 이전 시점의 디코더 셀의 예측이 틀렸는데
이를 현재 시점의 디코더 셀의 입력으로 사용하면
현재 시점의 디코더 셀의 예측도 잘못될 가능성이
높고 이는 연쇄 작용으로 디코더 전체의 예측을
어렵게 하기 때문이다
- 이전 시점의 디코더 셀의 예측이 틀렸는데
-
Teacher Forcing = RNN의 모든 시점에 대해서 이전 시점의 예측값 대신 실제값을 입력으로 주는 방법
-
즉, Seq2Seq는 훈련할 때와 동작할 대의 방식이 다름
Seq2Seq 추론
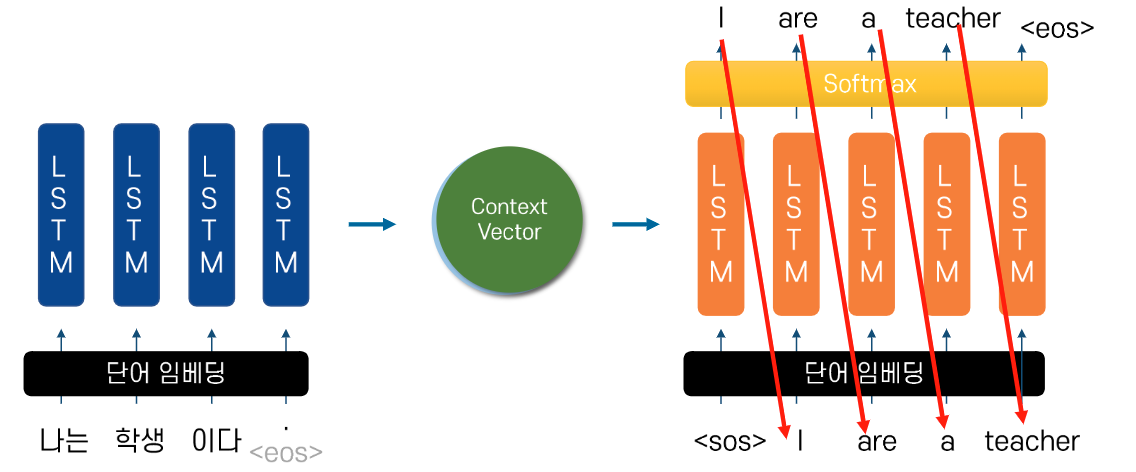
-
이전 시점(t-1)의 추론 결과를 바탕으로 현재 시점을 출력
-
추론 과정이므로 이전 시점의 결과가 틀렸어도
교사 강요를 할 수 없음!
Seq2Seq의 한계
-
입력 Sequence의 길이가 너무 길어지면,
Context Vector에 충분한 정보를 담지 못하는 한계 -
RNN의 고질적인 문제인
기울기 소실(Vanishing Gradient)문제도 존재
Sequence-to-Sequence with Attention
- 어텐션의 기본 아이디어:
디코더에서 출력 단어를 예측하는 매 시점(time step)마다,
인코더에서의 전체 입력 문장을 다시 한 번 참고한다.
전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보는 것이 핵심Decoder가 time step(t)작업을 할 때
Query를 attention에 날리면
attention은 encoder에서 과거에(Ki)있었던
모든 일을 확인한다 (seq HS)
그 후 관련이 높은 HS를 찾아서 정보를 취합해서
Value들을 비중에 맞춰서 취합한다
decoder에 취합된 정보를 가지고 작업을 완료한다
-
해결 방법:
-
입력 문장의 출력 전체를 디코더의 입력으로 활용하자
-
모두 동일한 비율이 아니라, 해당 시점에서
예측해야 할 단어와 연관이 있는 입력 단어 부분을
좀 더 집중(attention)해서 보자
-
Attention Value
-
Attention(Q, K, V) = Attention Value
-
Q = Query : t 시점의 디코더 셀에서의 은닉 상태
-
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
- Query에 대한 attention 기여도를 계산할 대상
-
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
- Attention 크기를 계산하기 위한 값
Encoder의 모든 hidden state 중 어디에 더 집중할 것인가를 계산
- 어텐션 함수는 주어진 '쿼리(Query)'에 대해서
모든 '키(Key)'와 유사도를 각각 구함
- 해당 유사도를 키와 맵핑 되어있는 각각의 '값(Value)에 반영함
- 유사도가 반영된 '값(Value)'을 모두 더해서 리턴
Attention 의의
-
성능 상승
-
왜 그렇게 예측했는지 알 수 있게됨
(모델 결과 해석이 가능해짐)
