자연어 처리 분야
RNN(Recurrent NN)
-
시계열 데이터, 순차 데이터 에 특화
-
시계열 데이터
- 순서(Order)를 가지고 있는 데이터
- DNA 염기 서열(Sequential Data)
-
세계 기온 변화(Temporal Sequence)
-
샘플링된 소리 신호(Time Series)
MLP의 한계
-
모든 weight 한번에 받아서 처리
-
자연어 문장을 기존 MLP 모델에 적용시키기에는 한계가 있음
RNN의 필요성
-
RNN의 입력값
: (1) 입력데이터 (2) RNN을 거쳐 나온 출력값 상태
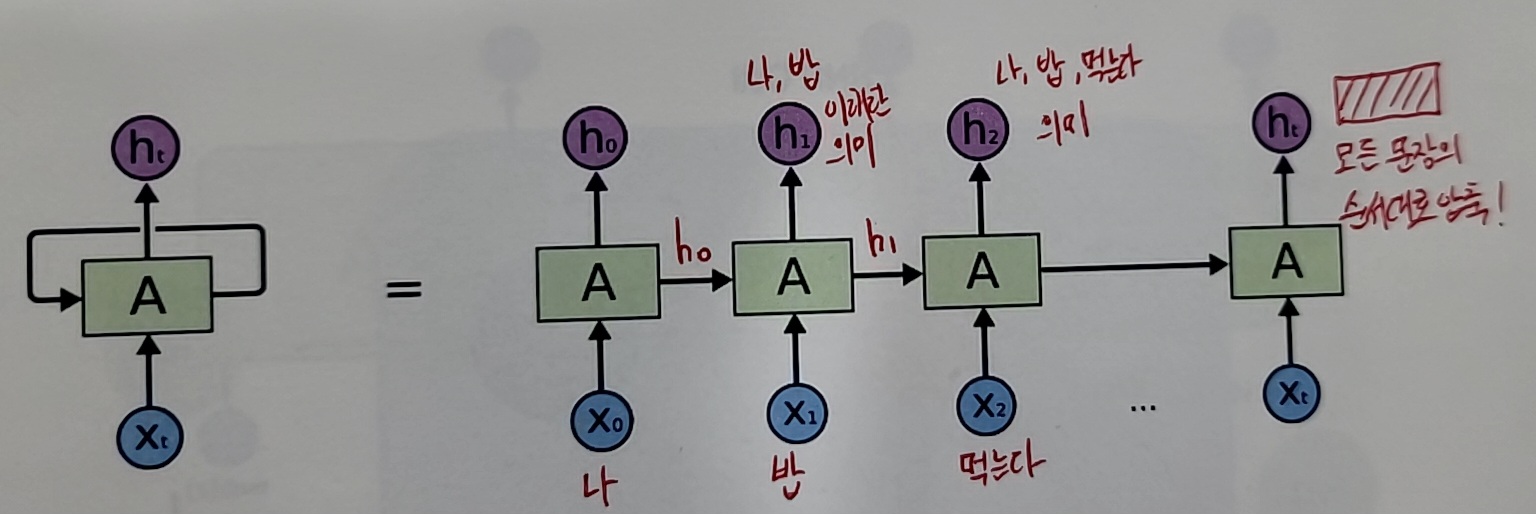
이걸 계속 반복 함으로써 실행RNN의 구조
-
순차 데이터 처리를 위한 딥러닝 모델이 등장
-
출력 값을 두 갈래(Output state, Hidden state)로
나누어 신경망에서 '기억'하는 기능을 부여 -
현재의 Input과 함께 과거의 Input을 함께 고려하기 위해, 네트워크가 병렬적으로 여러 개가 나열되고, 이전(왼쪽)의 네트워크가 이후(오른쪽)의 네트워크에 연결되는 구조임
-
그래서 마지막 만 보면 모든 의미가 다 들어가 있다
-
출력값이 2개가 나오지만 똑같은 h0가 나오는것
Vanilla RNN
-
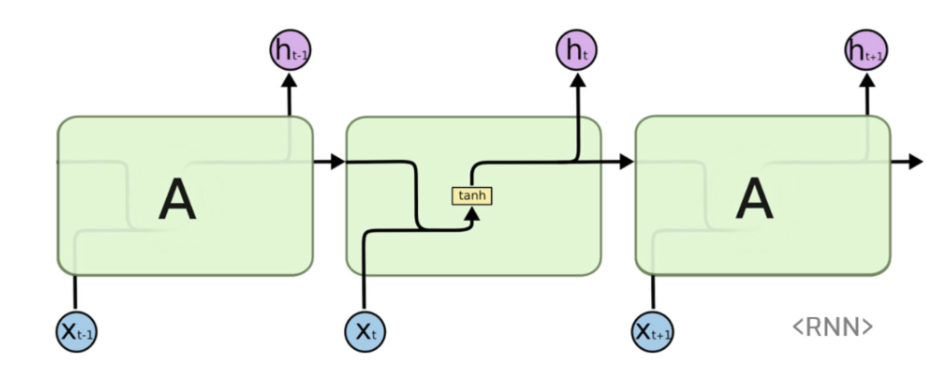
순환신경망은 동일한 구조의 네트워크(A)가
병렬적으로 연결되어 있는 형태 -
하나의 네트워크를 보면, 이전의 네트워크에서
계선된 값 (h)과 현재 input값(x)를 함께
"가중합"해서 tanh로 은닉층 노드(h)를 계산한다. -
여기서 가장 중요한 핵심은 "동일한 구조"라는 의미인데,
네트워크 안의 weight의 구성까지 모두 동일하다는 것을 의미
Hidden state의 의미
-
특정 시점 t까지 들어온 입력값의 상관관계나
경향성 정보를 압축해서 저장 -
모델이 내부적으로 계속 가지는 값이므로
일종의 메모리(Memory)로 볼 수 있음
Parameter Sharing
-
Hidden state와 출력값 계산을위한 FC Layer에
모든 시점의 입력값이 사용 -
각각의 가중치 Wx, Wh, Wy의 값은 하나의 층에서는
모든 시점에서 값을 동일하게 공유 -
하지만 은닉층이 2개 이상일 경우에는
각 은닉층에서의 가중치는 서로 다르다
RNN 학습
Back-propagation Through Time(BPTT)
-
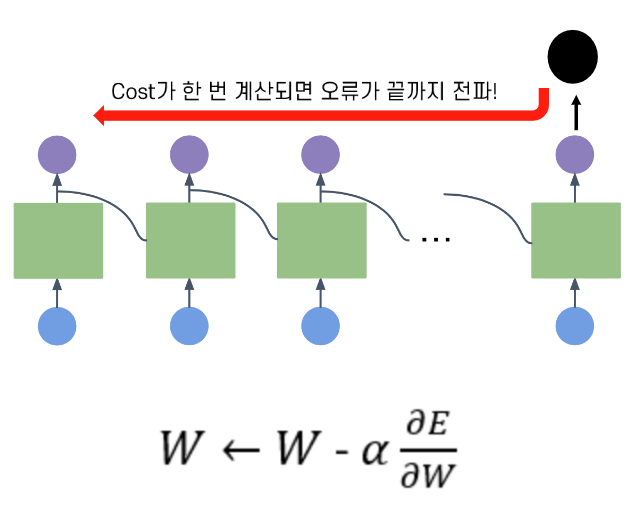
단순분류 예시일 때 상황!! (many to one 일때 상황)
-
순환신경망에서 학습 과정 또한
기존의 살펴본 Back-propagation과 동일함 -
chain-rule 을 이용한, 연쇄 계산!
단, 여기서의 핵심은 학습하는 weight가
네트워크마다 독립적이지 않고, 동일하다는것! -
한번의 배치를 통해 오른족에서 왼쪽으로 순차적으로
학습을 진행해 나가면서, 최종적으로 업데이트된
Wh, Wx를 가지고 다음 배치를 진행함
RNN의 한계
-
입력값의 길이가 매우 길어질 경우
: 초기 입력값과 나중 출력값 사이에 전파되는 기울기 값이
매우 작아질 가능성이 높음 -
기울기 소실(Vanishing Gradient)문제가 발생하기 쉬움
- 다른 말로 장기 의존성(Long-term Dependency)을 다루기가 어려움 (긴 문장을 이해하기 어렵다)
RNN 한계 극복하기
-
Bidirectional RNN
-
stacked RNN
Bidirectional RNN
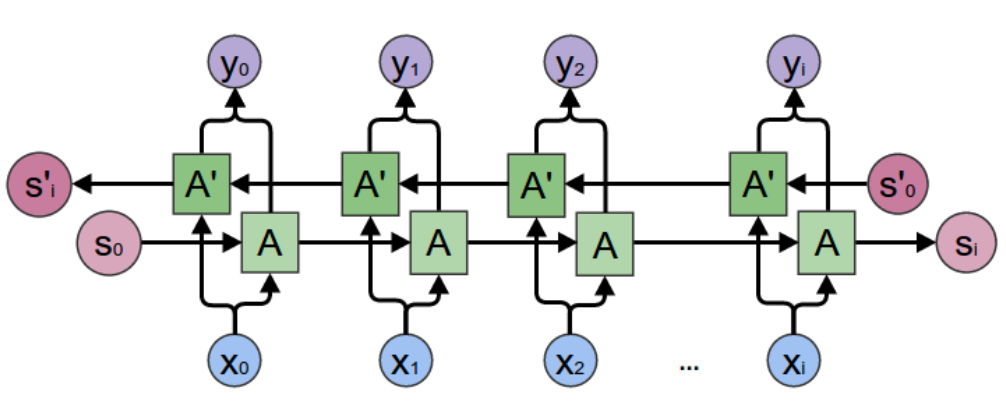
-
양방향 RNN 양방향으로 가서 둘다 비교
-
가운데는 애매모호..
-
RNN은 마지막 단어들에 큰 영향을 받고 처음에 들어온
단어들의 영향이 매우 작아진다. -
이를 보완하기 위해 역방향 RNN을 추가함으로써
문장의 앞도 신경 쓸 수 있게 한다. -
모델이 두 배가 되고 Hidden state도 두 배가 된다
Stacked RNN
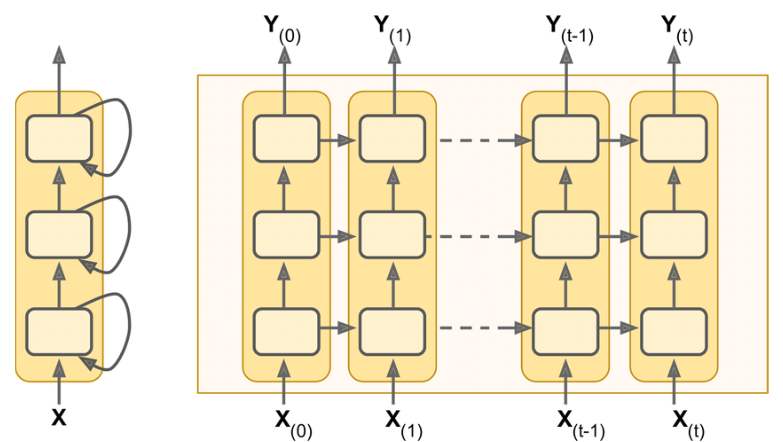
-
어려운 task일 경우 RNN cell 한번만으로
복잡한 의미를 뽑아낼 수 없다. -
MLP가 층을 늘려 비선형적이고 복잡한 문제를 해결한 것 처럼 RNN의 출력결과를 다시 다른 RNN에 넣어 복잡도를 올린다.
-
lv1, lv2, lv3로 하나씩 쌓아서 사용
