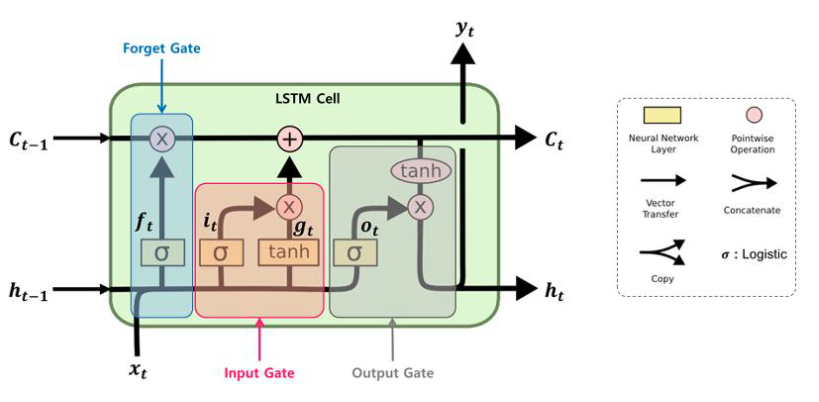
LSTM(Long Short Term Memory)장기 기억 능력을 갖춘 모델
-
RNN의 한계인 문장이 길어질 때 성능이 좋지 못하는걸
보완하기 위해 사용 -
3개를 입력받아 2개를 출력
-
3종류의 게이트를 4개의 FC Layer로 구성
- Wf : 망각 게이트(Forget Gate)
- Wi, WC : 입력 게이트 (Input Gate)
- Wo : 출력 게이트(Output Gate)
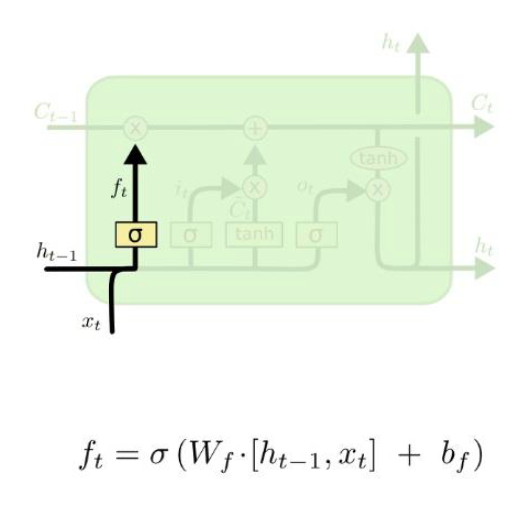
Forget Gate
-
기존 Cell state에서 어떤 정보를 잊을지 결정하는 게이트
-
ft = σ (Wf[ht-1, xt])
-
σ = sigmoid 함수
-> 출력범위가 0~1 비율로 변경 하는것 -
[ht-1, xt] :ht-1 벡터와 xt 백터를 concatenate 하는 연산
-
Concatenate 예시 :
1 2 3 과 4 5 6을 concatenate하면 1 2 3 4 5 6
-
-
입력 : 이전 output, 현재 입력
-
출력 : cell state로 가는 값
- 1이면 이전 cell state가 그대로 가고,
0이면 이전 cell state는 전부 사라짐
- 1이면 이전 cell state가 그대로 가고,
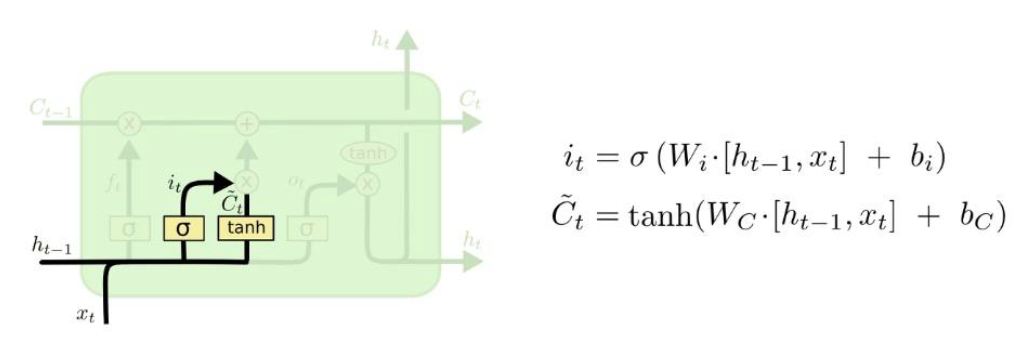
Input Gate
-
현재 입력 받은 정보에서 어떤 것을 cell state에 저장할지 결정
-
sigmoid[0~1]와 tanh[-1~1]를 곱한다
- (tanh : 장기 신호의 방향을 결정(저장할 데이터)
sigmoid 입력의 세기를 결정
- (tanh : 장기 신호의 방향을 결정(저장할 데이터)
Output Gate
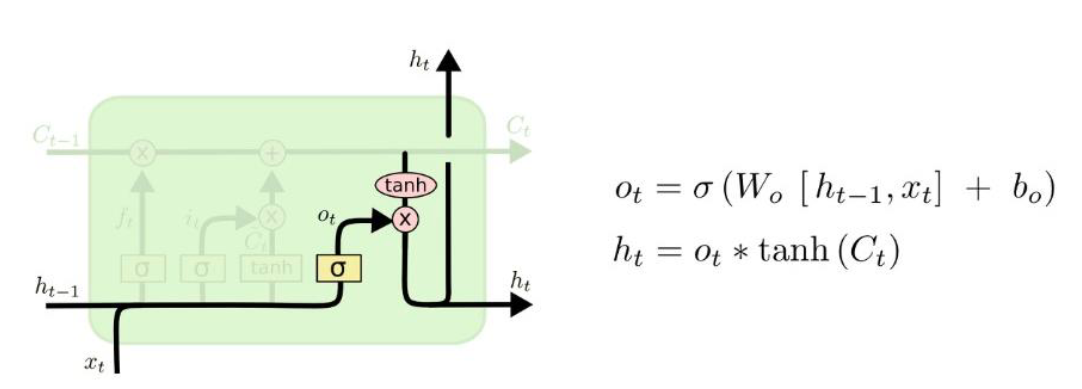
- 다음 hidden state와 출력값을 계산 -> 새로 계산된 cell state를 사용
- 장기기억, 단기기억, 현재 input을 모두 사용하여 예측(ht == Yt)
- 각각의 비중 -> weight -> 학습해야 함
Cell state(Update)
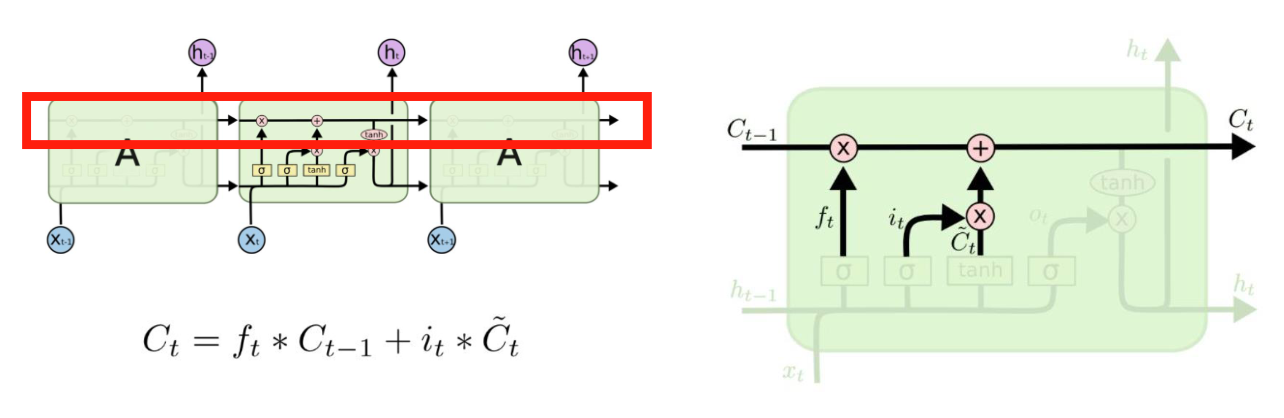
-
Forget Gate 와 Input Gate의 정보를 통해 cell state갱신
-
Update : Forget Gate와 Input Gate의 출력 값을 더해주는 부분
-
*연사자는 벡터의 각 원소 별로 곱하는 연산(Hadamard Product)
- 예) 1 2 3 * 4 5 6 = 4 10 18
- Loss fn, Cost fn
GRU
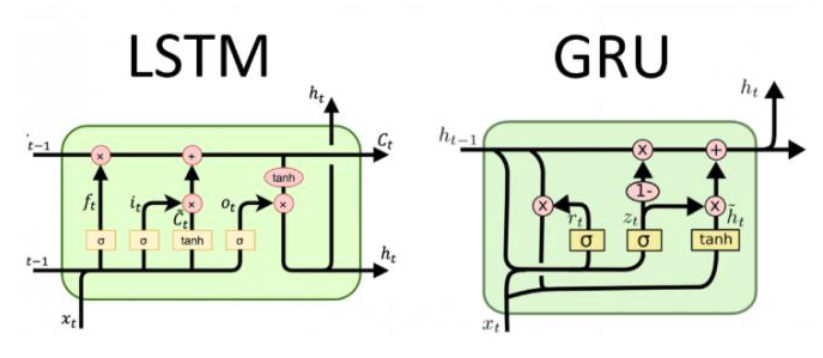
-
Gated Recurrent Unit의 약자
-
LSTM이 가지는 3개의 게이트를 2개로 간소화하고
Cell state를 없앰- 파라미터 수가 감소하여 LSTM보다
빠른 학습 속도를 가짐 - 그럼에도 음악 모델링, 음성 신호 모델링 및 자연어 처리의 특정 작업에 대한 GRU의 성능은
일반적으로 LSTM과 비슷한 수준
- 파라미터 수가 감소하여 LSTM보다
-
hidden state하나로 장기적 기억도 관리 사용
-
내부적으로는 다를지몰라도 외부적으로는 똑같아 보인다.
-
2종류의 게이트를 2개의 FC Layer로 구성
- Wr : 리셋 게이트(Reset Gate)
- Wz : 업데이트 게이트(Update Gate)
Reset Gate
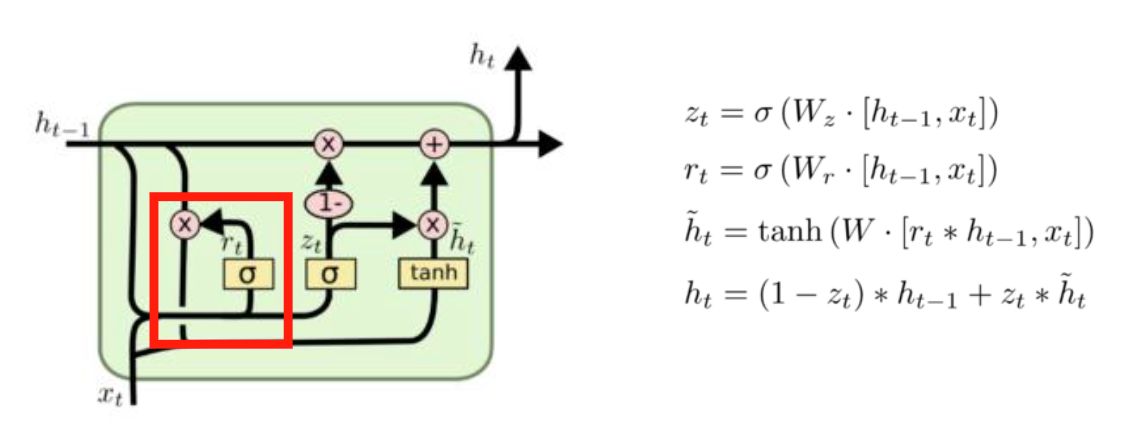
-
기존 hidden state의 정보를 얼마나 초기화할지
결정하는 게이트 -
rt = σ (Wr[ht-1, xt])
- Sigmoid -> 0 ~ 1 사이 값으로 출력
Update Gate
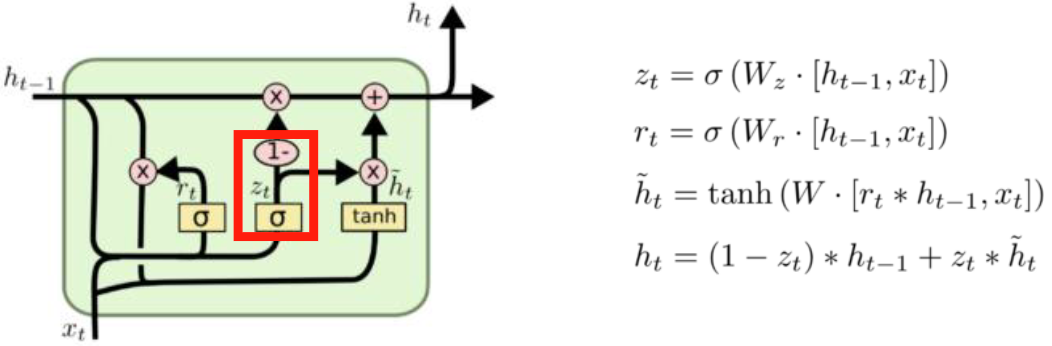
- 기존 hidden state의 정보를
얼마나 사용할지 결정하는 게이트- 과거와 현재의 정보 업데이트 비율을 결정하는 게이트
- 과거와 현재의 정보 업데이트 비율을 결정하는 게이트
- zt = σ (Wz[ht-1, xt])
- Sigmoid -> 0 ~ 1 사이 값으로 출력
LSTM VS GRU
결국 해보고 좋은거 사용하면 된다..
-
GRU와 LSTM 중 어떤 것이 모델의 성능 면에서 더 낫다고 단정지어 말할 수 없으며, 기존에 LSTM을 사용하면서 최적의 하이퍼 파라미터를 찾아낸 상황이라면 굳이 GRU로 바꿔서 사용할 필요는 없다
-
경험적으로 데이터 양이 적을 때는 매개 변수의 양이 적은 GRU가 조금 더 낫고, 데이터 양이 더 많으면 LSTM이 더 낫다고도 함
-
GRU보다 LSTM에 대한 연구나 사용량이더 많은데,
이는 LSTM이 더 먼저 나온 구조이기 때문이다
