목차
1. 집계함수
2. Group by 절
3. Having 절
1. 집계함수
- 집계함수에 대한 이해가 있어야
group by절과having절을 이해할 수 있다.
1) count() 함수
- 레코드의 수를 출력하는 함수이다.
count(*) :
null을 포함한 모든 레코드를 계산한다.
count(컬럼명) : 해당 컬럼의 값이null인 것을 제외하고 계산한다.

count()를 이용해citykorea의 모든 레코드 수를 출력했다.
2) sum() 함수
sum(컬럼명)의 형태로 사용하며 해당 컬럼의 값을 합산해준다.

sum()을 이용해citykorea의 인구수 합계를 출력했다.
3) min(), max() 함수
min(컬럼명)의 형태로 사용하며 해당 컬럼의 최소, 최대값을 출력한다.

max()를 이용해citykorea의 가장 많은 인구수를 가진 도시의 이름과, 인구수를 출력했다.
4) avg() 함수
avg(컬럼명)의 형태로 사용하며 해당 컬럼의 평균값을 출력한다.

avg()를 이용해citykorea의 평균 인구수를 출력했다.
2. Group by 절
group by는 "집계함수"의 결과를 특정 컬럼을 기준으로 묶어 결과를 출력해주는 쿼리이다.
select
column,
집계함수(컬럼명)
from
table
(where column = data)
group by
column;select절에 Group으로 묶을 column과 집계함수를 사용한다. 마지막으로 group by 절에 Group의 기준컬럼을 입력한다.

group by절을 이용해 대도시별 인구수 합계를 출력했다.
3. Having 절
having절은group by절을 다시 필터링하기 위한 쿼리이다.select절에where절을 이용해 조건을 거는것과 같다.
select
column,
집계함수(컬럼명)
from
table
(where column = data)
group by
column
(having 집계함수(컬럼명) 부등호 data);- 앞의
group by절에 추가로having을 사용하면 된다. - 조건 비교에 사용될 데이터는 반드시
집계함수의 결과를 사용해야 한다.
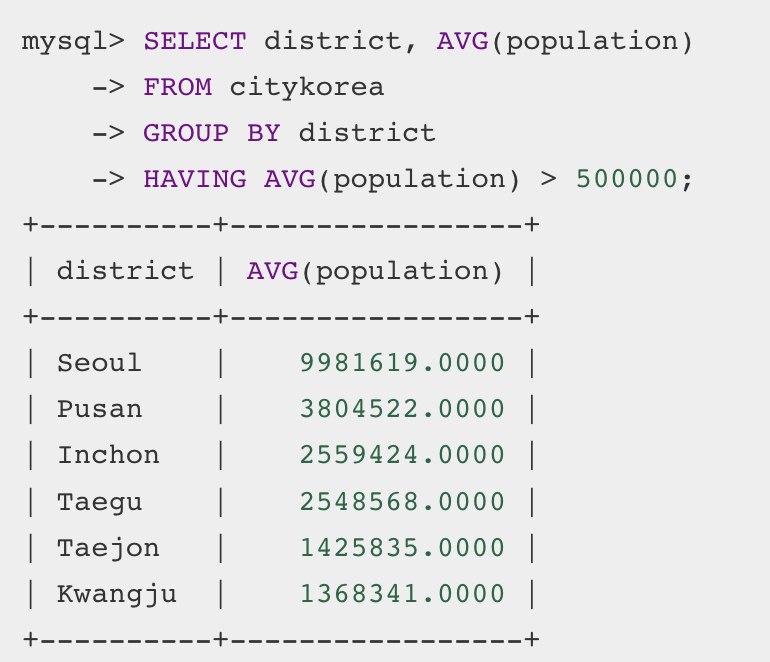
having절에 조건을 부여할 때에는group by처럼 집계함수를 사용해야 한다.
- 그렇다고 꼭
select에 사용된 집계함수를 사용할 필요는 없다.
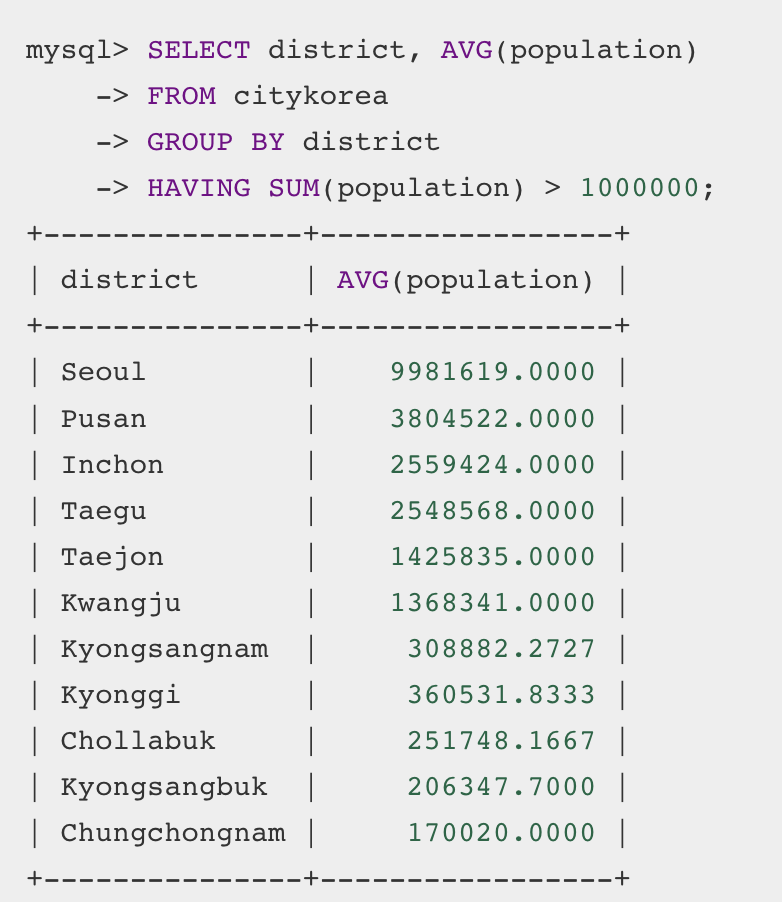
대도시별 인구수 합계가 100만을 초과하는대도시별 인구수 평균을 출력했다.

cornchip