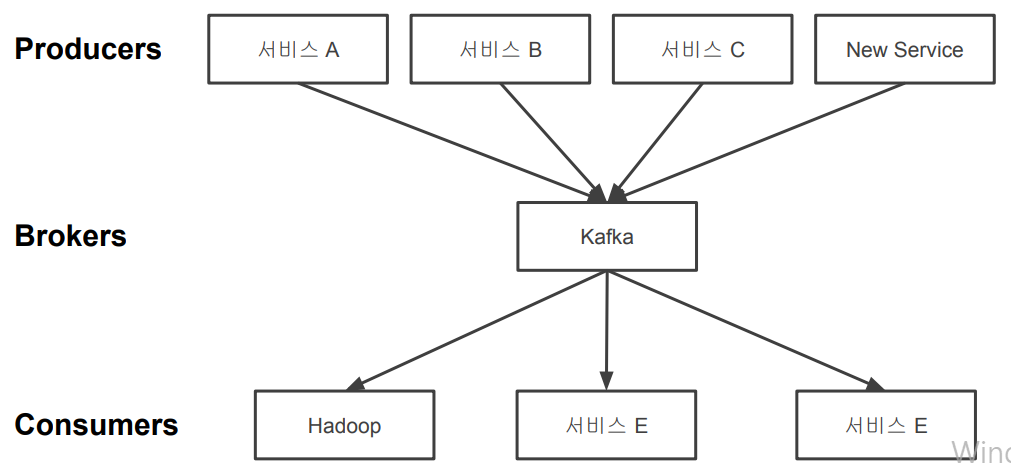
1. Kafka 란?
-
Apache Kafka는 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산 데이터 스트리밍 플랫폼입니다.
-
여러 소스에서 데이터 스트림을 처리하고 여러 사용자에게 전달하도록 설계되었습니다.
-
간단히 말해 A지점에서 B지점까지 이동하는 것뿐만 아니라 A지점에서 Z지점을 비롯해 필요한 모든 곳에서 대규모 데이터를 동시에 이동할 수 있습니다.
2. Kafka VS RabbitQ
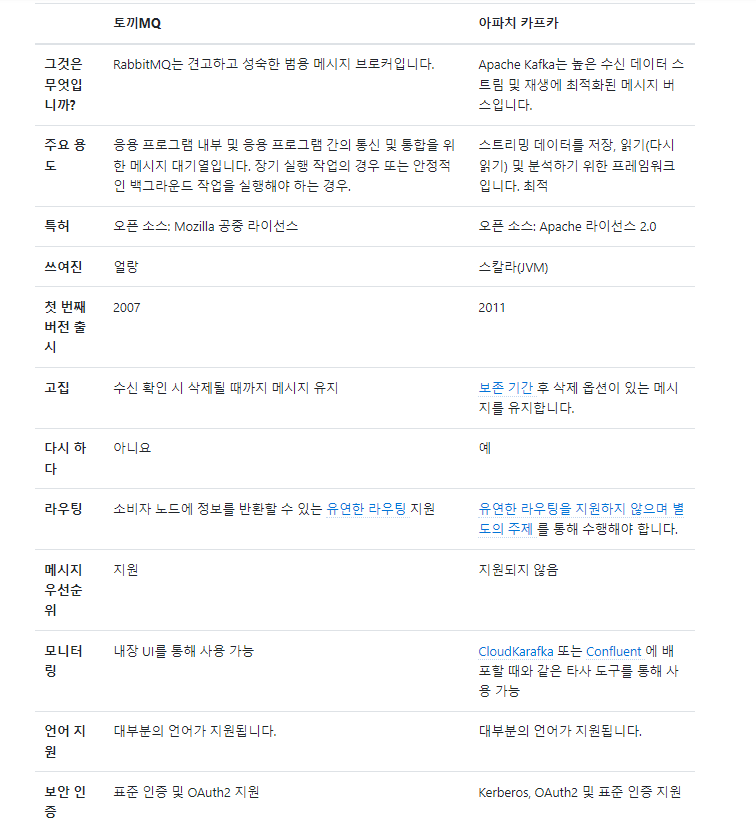
- 모두 비동기 통신을 제공하며, 프로듀서와 컨슈머가 분리되어 있음
-
메시지 큐의 장점
-
비동기(Asynchronous): Queue에 넣기 때문에 나중에 처리할 수 있습니다.
-
비동조(Decoupling): Appliction 과 분리할 수 있습니다.
(각 서비스의 연결을 느슨하게 합니다) -
탄력성(Resilience): 일부가 실패 시 전체에 영향을 받지 않습니다.
-
과잉(Redundancy): 실패할 경우 재실행 가능합니다.
-
보증(Guarantees): 작업이 처리된걸 확인할 수 있습니다.
-
확장성(Scalable): 다수의 프로세스들이 큐에 메시지를 보낼 수 있습니다.
-
- RabbitMQ는 메시지 브로커 방식이고 Kafka는 pub/sub 방식입니다.
RabbitMQ
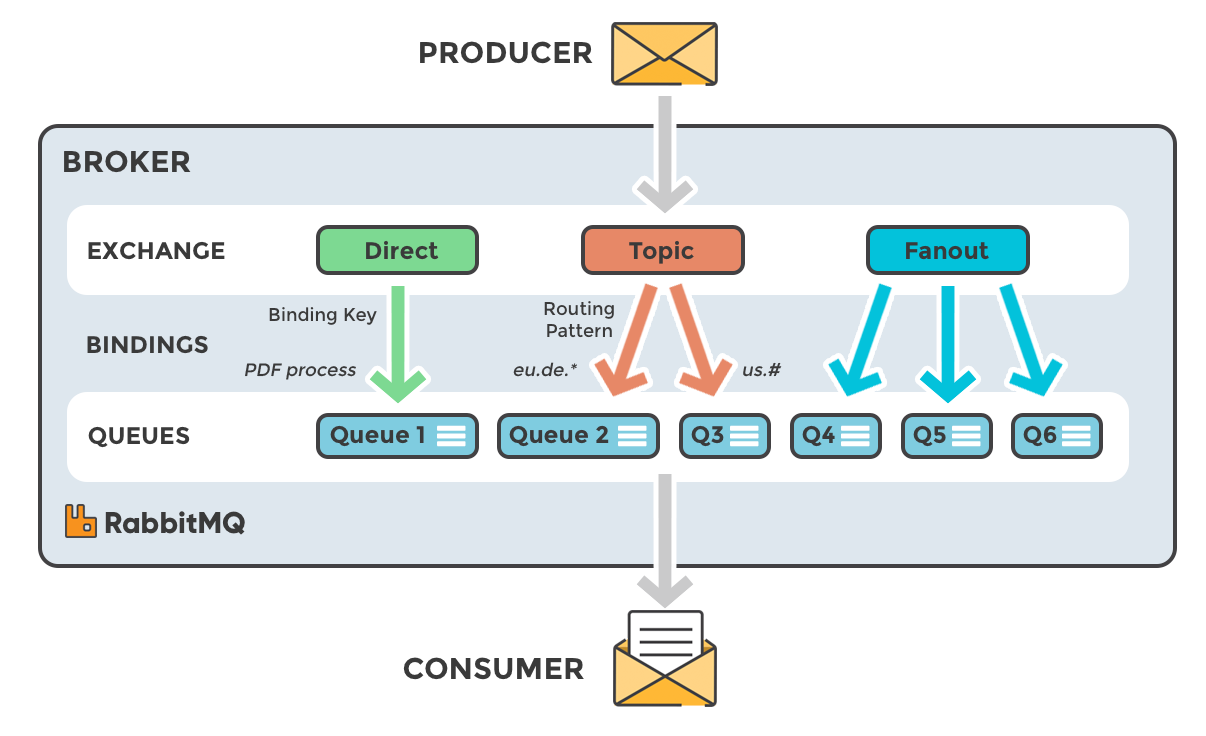
-
AMQP(Advanced Message Queuing Protocol, 클라이언트와 미들웨어간 메시지 교환 개방형 표준 프로토콜)을 위해 개발 되어 다른 AMQP 프로토콜 기반 MQ(ex. RabbitMQ, ActiveMQ, ZeroMQ)등과 데이터 교환이 수월
-
필요에 따라 동기/비동기 구현 가능
-
유연한 라우팅이 가능(exchanger가 메시지를 적절히 각각의 queue에 분배)하여 관리가 쉽고, 관리UI가 직관적이고 편리
-
broker 중심적이며, producer와 consumer간 메시지 전달 보장에 초점을 맞추어 신뢰성이 높음
-
20k+/sec 처리 보장
Kafka
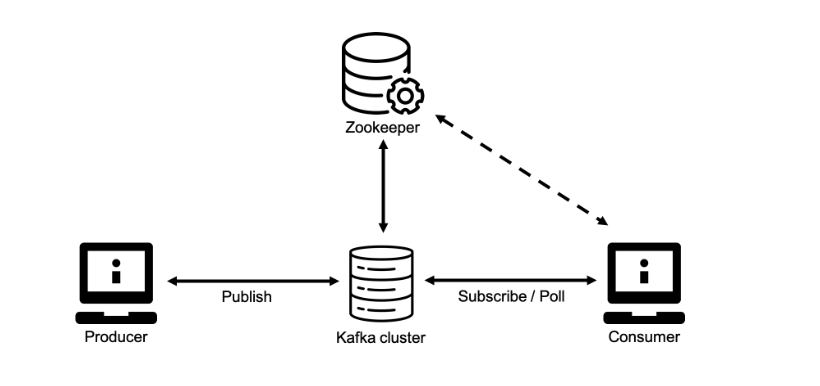
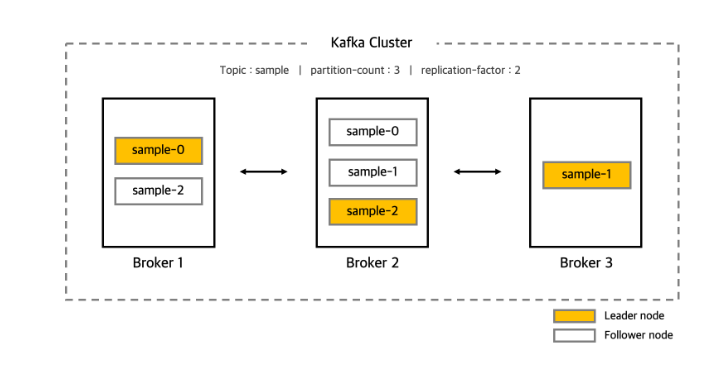
-
고성능, 고가용성, 확장성
-
분산 처리 시스템으로서, 확장성(scalability) 및 고가용성(high available)이 높음
아파치 카프카는 중앙 집중형 메시지 관리 방식으로, 메시지의 생성과 소비와 관리를 완전히 독립시킨 구조이다. 메시지를 관리하는 데이터 큐를 중앙에 두고, 독립적인 데이터의 발행과 소비가 이루어진다. 이 같은 패턴을 publish / subscribe 모델 패턴이라 칭하며 이런 느슨한 결합을 통해 publisher 나 subscriber 에 장애가 발생할 때에도 의존성이 없으므로 안정적인 데이터 처리가 가능해진다.
-
따라서, 노드 장애에 대한 대응성이 높음
-
배치 처리가 가능해 네트워크 왕복 오버헤드를 줄일 수 있음
-
디스크 파일 시스템에 데이터를 저장함으로써 영속성(persistency)을 보장 (즉, 오류 시 복구가 가능)
-
Producer 중심적이며, 메시지 전달 보장이 optional
- 메시지 전달 보장을 할 경우 처리속도가 느려져(리더와 팔로워 모두에게 ack(응답 승인)을 받야아 하므로) 카프카의 처리속도 측면의 장점이 상쇄
-
라우팅 기능이 없음 (producer가 직접 적절한 topic과 partion으로 보내줘야 함)
-
100k+/sec 처리 보장
✅Zookeeper
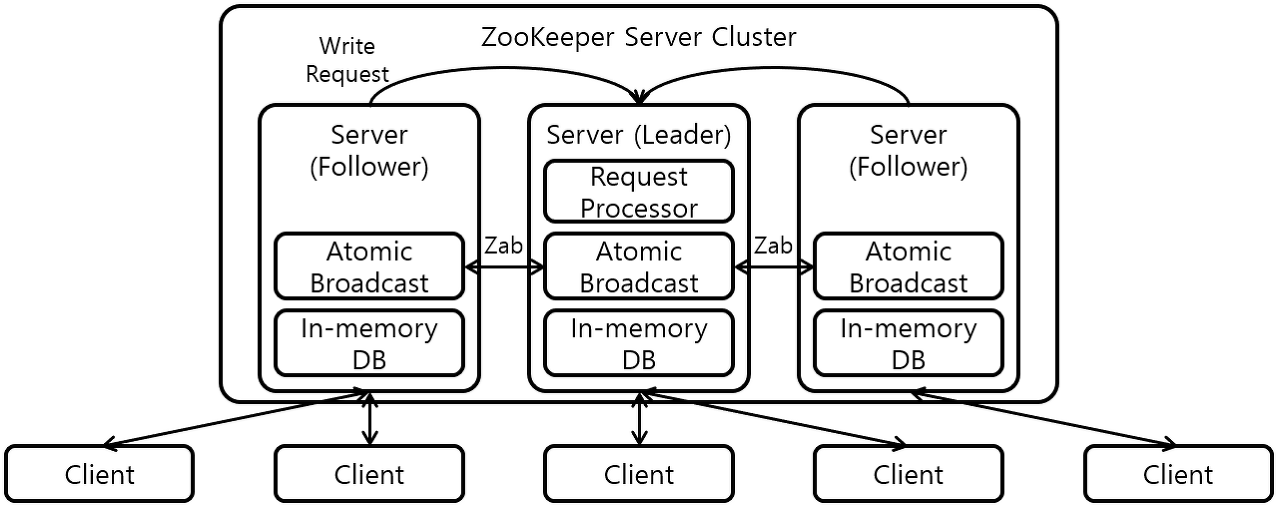
-
분산 코디네이션 서비스를 제공하는 오픈소스 프로젝트
-
주키퍼는 직접 애플리케이션 작업을 조율하지 않고 조율하는 것을 쉽게 개발할 수 있도록 도와주는 도구이다. API를 이용해 동기화나 마스터 선출 등의 작업을 쉽게 구현할 수 있게 해준다.
-
각 애플리케이션의 정보를 중앙 집중화하고 구성관리, 그룹 관리 네이밍, 동기화 등의 서비스를 제공한다.
-
주키퍼의 데이터는 메모리에 저장되고, 영구 저장소에 스냅샷을 저장한다.
[분산 코디네이션 서비스란?]
- 분산 시스템에서 시스템 간의 정보 공유, 상태 체크, 서버들 간의 동기화를 위한 락 등을 처리해주는 서비스
-
카프카에서 주키퍼는?
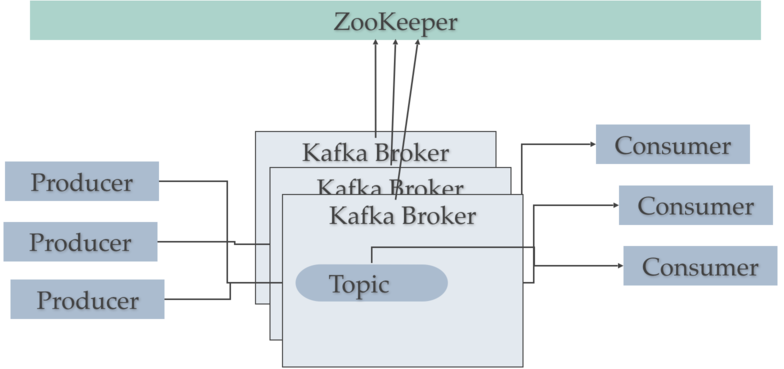
-
주키퍼는 카프카 클러스터를 관리하고 조정하는 코디네이터 역할
-
새로운 브로커 추가나 기존 브로커 감시하고 브로커 목록이 추가나 삭제에 의해서 변화될 경우,
-
주키퍼는 이런 상태를 프로듀서나 컨슈머에게 통보하여 활성화된 브로커과 동작을 원활하게 한다. (리벨런싱)
-
특정 토픽의 파티션에 대해서 리더와 팔로워를 기록하고, 프로듀서나 컨슈머에게 정보를 제공한다.
-
-
서버의 상태를 감지하기 위해 사용되며 새로운 토픽이 생성되었을 때, 토픽의 생성과 소비에 대한 상태를 저장한다.
-
주키퍼와 카프카는 대규모 환경에서는 다른 서버에 두는 편이 좋다. 주키퍼 앙상블은 홀수로 구성되어 과반수 이상이 장애가 발생하면 중단되고, 카프카는 그렇지 않아도 되기 때문에 다른 서버에 두는 것을 권장한다.
-
카프카는 주키퍼 없이 동작하지 못한다.
RabbitMQ가 적절한 곳
복잡한 라우팅
-
복잡한 라우팅의 경우 RabbitMQ를 사용합니다.
-
RabbitMQ는 신속한 요청-응답이 필요한 웹 서버에 적합합니다.
-
부하가 높은 작업자(20K 이상 메시지/초) 간에 부하를 공유합니다.
-
RabbitMQ는 백그라운드 작업이나 PDF 변환, 파일 검색 또는 이미지 확장과 같은 장기 실행 작업도 처리할 수 있습니다.
요약하자면, 장시간 실행되는 태스크, 안정적인 백그라운드 작업 실행, 애플리케이션 간/내부 통신/통합이 필요할때 RabbitMQ를 사용하세요.
kafka가 적절한 곳
실시간 처리
-
Kafka는 복잡한 라우팅에 의존하지 않고 최대 처리량으로 스트리밍하는 데 가장 적합합니다.
-
이벤트 소싱, 스트림 처리 및 일련의 이벤트로 시스템에 대한 모델링 변경을 수행하는 데 이상적입니다.
-
Kafka는 다단계 파이프라인에서 데이터를 처리하는 데도 적합합니다.
결론적으로 스트리밍 데이터를 저장, 읽기, 다시 읽기 및 분석하는 프레임워크가 필요한 경우 Kafka를 선택해야겠죠. 정기적으로 감사하는 시스템이나 메시지를 영구적으로 저장하는 데 이상적입니다.
3. 환경 설정
전제 조건
- JDK(Java Development Kit)
- 7-Zip 또는 WinRAR
Windows에 Kafka 설치: Kafka 다운로드
Kafka 설치 및 구성
-
다운로드 후 Kafka 파일 을 추출하거나 압축 을 풉니다. 명령 프롬프트에서 빠르게 액세스할 수 있도록 압축을 푼 폴더를 원하는 디렉터리로 이동합니다.
-
이제 Windows에 Kafka를 올바르게 설치하려면 추출된 Kafka 파일에서 일부 구성을 수행해야 합니다.
-
일반적으로 추출된 Kafka 파일에는 Kafka 서버의 모든 클러스터 및 구성을 관리하기 위해 Kafka와 동시에 실행되는 Zookeeper 파일이 있습니다.
-
기본 임시 폴더에 저장하는 대신 Kafka 및 ZooKeeper 데이터를 별도의 폴더에 저장하도록 Kafka 및 ZooKeeper 파일을 모두 구성할 수 있습니다.
-
Kafka 폴더 안에
Data라는 새 폴더를 만듭니다 .- Data 폴더 안에
Kafka와Zookeeper라는 두 개의 개별 폴더를 만듭니다.
- Data 폴더 안에
-
Kafka와 Zookeeper에 대해 별도의 폴더를 만든 후 새로 만든 폴더를 가리키도록 구성 파일을 약간 변경해야 합니다.
-
이를 위해 먼저 데이터 폴더 내부에 생성된 Zookeeper 폴더의 파일 경로를 복사합니다.
-
압축을 푼 Kafka 파일 안에 있는 config 폴더에서 메모장 또는 메모장++과 같은 텍스트 편집기 응용 프로그램으로 " Zookeeper.properties " 파일을 엽니다. 열린 파일 에서 위 이미지와 같이 " datadir " 위치를 복사한 Zookeeper 폴더 경로로 바꿉니다. 백슬래시 대신 슬래시를 사용하여 경로를 변경해야 합니다. 마지막으로 파일을 저장하여 파일 구성에 대한 변경 사항을 업데이트합니다.
-
Zookeeper 속성을 구성한 후 Kafka Server 속성을 구성해야 합니다. 이를 위해 데이터 폴더 내부에 생성된 Kafka 폴더의 파일 경로를 복사합니다.
-
추출된 Kafka 파일 내부에 있는 " Config " 폴더 에서 server.properties 파일을 엽니다 .
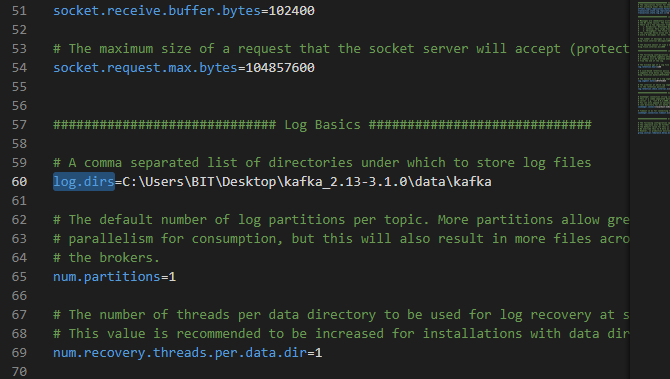
-
server.properties 파일 에서 위 이미지와 같이 " logs.dirs " 위치를 복사한 Kafka 폴더 경로로 바꿉니다. 백슬래시 대신 슬래시를 사용 하여 경로를 변경해야 합니다 . 파일 경로에서 백슬래시를 슬래시로 교체하고 파일을 저장합니다.
-
이제 Kafka 파일에 필요한 변경 및 구성을 수행했으며 컴퓨터에서 Kafka를 설정하고 시작할 준비가 되었습니다.
Zookeeper 시작
- Kafka 경로로 이동합니다. 이제 아래 명령어를 입력합니다.
zookeeper-server-start.bat ....configzookeeper.properties
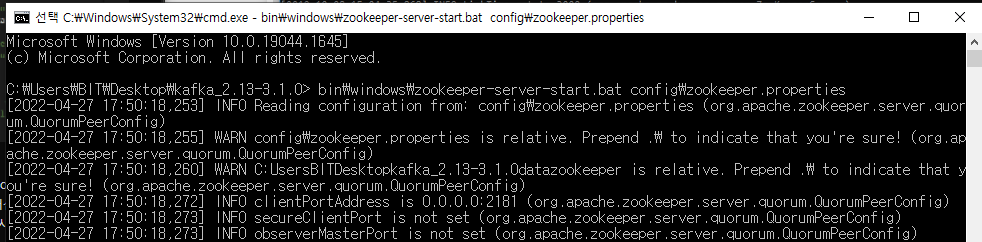
- 출력에서 Zookeeper가 시작되고 포트
2181에 바인딩되었음을 알 수 있습니다 . 이로써 Zookeeper 서버가 성공적으로 시작되었음을 확인할 수 있습니다.
⭐Zookeeper를 계속 실행하려면 명령 프롬프트를 닫지 마십시오.
Kafka 시작
- 다른 명령 프롬프트 창을 열고 아래 명령을 입력합니다.
kafka-server-start.bat ....configserver.properties
- Kafka Server가 성공적으로 시작되었으며 스트리밍 데이터를 사용할 준비가 되었습니다.
이제 Zookeeper와 Kafka가 모두 시작되어 성공적으로 실행되고 있습니다.
확인하려면 새로 생성된 Kafka 및 Zookeeper 폴더로 이동합니다. 각각의 Zookeeper 및 Kafka 폴더를 열면 폴더 안에 특정 새 파일이 생성되었음을 알 수 있습니다.
주제를 생성하여 Kafka 테스트
-
Kafka 및 Zookeeper를 성공적으로 시작했으므로 새 주제를 생성한 다음 주제 이름을 사용하여 메시지 게시 및 소비를 생성하여 테스트할 수 있습니다.
-
주제는 파티션이라는 여러 범주 아래에 메시지 스트림을 저장하고 구성하는 가상 컨테이너입니다. 각 Kafka 주제는 항상 전체 Kafka 클러스터에서 임의의 고유한 이름으로 식별됩니다.
4. 사용해보기
✅ Kafka의 동작은 Zookeeper와 함께 작동하기 때문에 Zookeeper 없이는 Kafka를 구동할 수 없습니다.
- 반드시 Zookeeper 서버를 먼저 구동해야 합니다.
C:\Users\BIT\Desktop\kafka_2.13-3.1.0
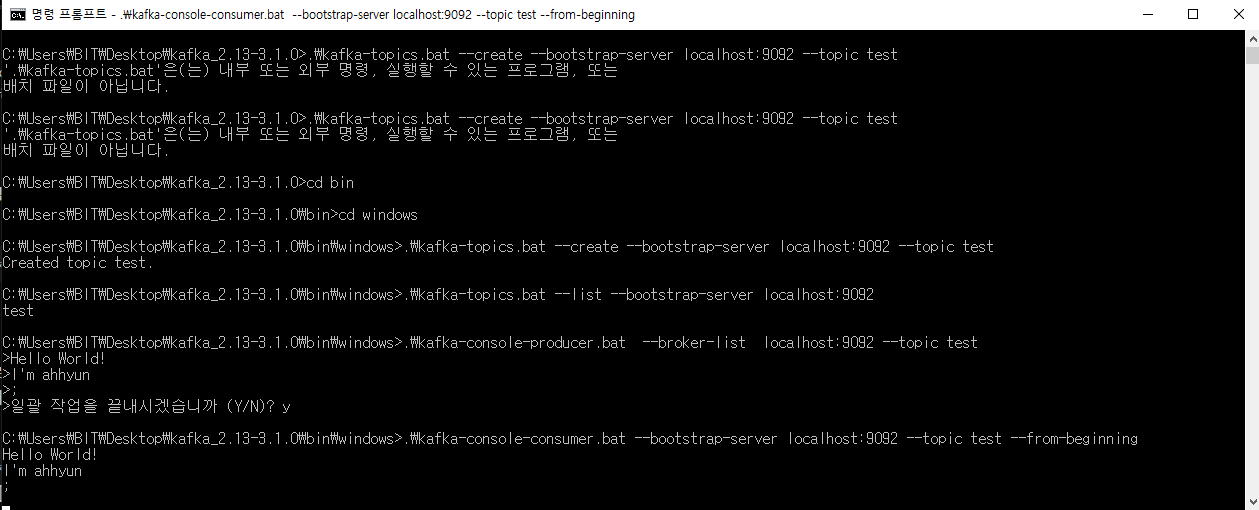
카프카 브로커(broker)에 토픽(topic) 생성하기
cd bin
cd windows
.\kafka-topics.bat --create --bootstrap-server localhost:9092 --topic test

- create 옵션으로 test라는 토픽을 생성하고,
bootstrap-server옵션으로 카프카 서버인9092포트에 연결
생성된 토픽 확인
.\kafka-topics.bat --list --bootstrap-server localhost:9092프로듀서(producer)를 실행하여 토픽(test)에 메시지 보내기(push)
.\kafka-console-producer.bat --broker-list localhost:9092 --topic test>모양이 나타나면 보낼 메시지를 입력하시면 됩니다.
컨슈머(consumer)를 실행해서 토픽(test)에서 메세지를 가져오기(pull)
.\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning--from-beginning명령어는 기존에 입력한 메시지를 가져올지 안가져올지를 설정하는 명령어
5. Kafka의 구조