2017년 NIPS를 통해 발표된 Transformer는 그전까지 NLP(Natural Language Processing; 자연어처리)분야에서 많이 쓰이던 인공신경망 구조(주로 RNN)가 아닌 "Attention"이라는 메커니즘을 활용해 번역부분 SOTA를 차지함으로써 화려하게 데뷔하였다. 그러더니 슬금슬금 분야를 넓혀 Image classification 이나 Image detection, Image retrieval 등 NLP를 넘어 컴퓨터 비전분야까지 다다른, 가히 최근 인공지능계의 핫이슈라고 할 수 있을 것이다.
Transformer
-
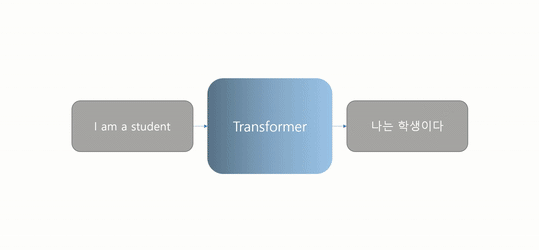
우선 Transformer는, 쉽고 간단히 말해서, 그냥 번역기다.
- A언어로 쓰인 어떤 문장이 Transformer로 입력되면, 여러 개의 인코더 블록과 디코더 블록(논문에서는 각각 6개)을 통과하여 B언어로 쓰인 같은 의미의 문장으로 출력되는 것이다.
-
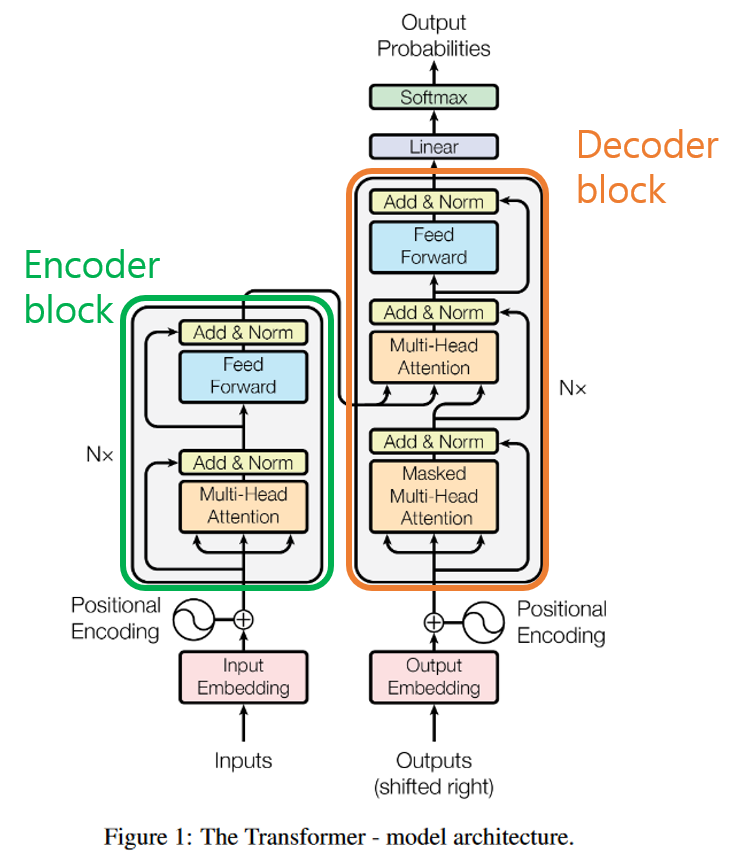
인코더 블록과 디코더 블록의 구조
-
self-attention layer
- 각각 입력된 문장내 단어간의 관계
-
fully connected feed-foward layer
- 모든 단어들에 동일하게 적용
-
디코더 블록에는 이에 더해 encoder-decorder attention layer가 두 layer 사이에 들어가 있다.
-
Input - Word2Vec
-
우리가 transformer에 어떤 문장을 입력할 때, 가장 먼저 거치는 과정은 그 문장을 모델이 연산할 수 있는 숫자형태로 바꿔주는 것이다.
- 다시말해 각 문장을 의미를 갖는 최소 단위인 단어들로 쪼갠 다음, Word2Vec이라는 알고리즘을 통해 각 단어를 vector형태로 변환한다.
-
우리가 image classification이나 detection 등을 할 때 이미지에서 feature를 추출하듯, 이 과정을 통해 단어는 그 의미를 보존한채 low-dimensional vector로 변한다.
- 이러한 일련의 과정을 word embedding이라고 한다.
Encoder Block
1. Self-Attention
-
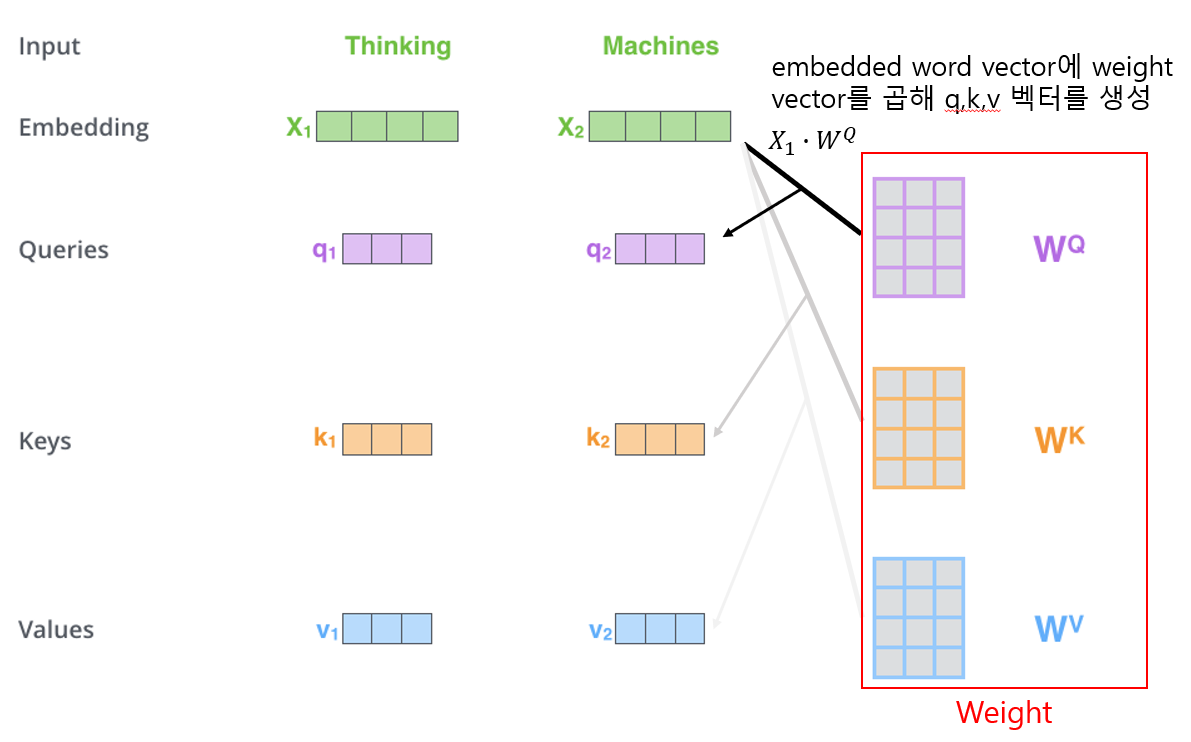
문장은 word embedding을 거쳐 크기가 512인 vector들의
list{X1,X2,...Xn}로 바뀐채 먼저 첫번째 인코더 블록의 attention layer로 입력된다.-
그리고 (우리가 학습시켜야할)
Weight W를 만나 벡터곱을 통해Query,Key,Value라는 3가지 종류의 새로운 벡터를 만들어낸다. -
각 단어의 3가지 vector에 대해 다른 모든 단어들의 key vector와 특정한 연산을 하여 attention layer의 출력을 만들어낸다.
아래에서 그 과정을 좀더 들여다볼 예정인데, 만약 복잡한 연산과정을 알고 싶지 않다면 self-attention layer는 각 단어의 vector들끼리 서로간의 관계가 얼마나 중요한지 점수화한다 는 개념만 알고 넘어가도 좋다.
-

-
Query vector는 문장의 다른 단어들의 Key vector들과 곱한다.
- 이렇게 함으로써 각 단어가 서로에게 얼마나 중요한지 파악할 수 있다.
- 이때 주의할 점은 자기자신의 key vector와도(Self-Attention) 내적한다는 것이다.
-
이렇게 얻어진 각 값들은 계산의 편의를 위해 key vector 크기의 제곱근으로 나눠진 뒤, softmax를 적용해 합이 1이 되도록 한다.
- 거기에 각 단어의 value vector를 곱한 뒤 모두 더하면 우리가 원하는 self-attention layer의 출력이 나온다.
-
이 출력은 입력된 단어의 의미뿐만 아니라, 문장내 다른 단어와의 관계 또한 포함하고 있다.
-
예를 들어 '나는 사과를 먹으려다가 그것이 썩은 부분이 있는 것을 보고 내려놓았다.' 라는 문장을 살펴보자.
-
우리는 직관적으로 '그것'이 '사과'임을 알 수 있지만, 여태까지의 NLP 알고리즘들은 문맥을 읽기 어렵거나 읽을 수 있다해도 단어와 단어사이의 거리가 짧을 때만 이해할 수 있었다.
-
그러나 attention은 각 단어들의 query와 key vector 연산을 통해 관계를 유추하기에 문장내 단어간 거리가 멀든 가깝든 문제가 되지 않는다.
논문에서는 이러한 self-attention 구조가 왜 훌륭한지에 대해서도 한 장을 활용하여 언급한다.
- 우선 연산 구조상 시간복잡도가 낮고 병렬화가 쉬워 컴퓨팅 자원소모에 대한 부담이 적다는 점이 있다.
- 또한 거리가 먼 단어간의 관계도 계산하기 쉽고 연산과정을 시각화하여 모델이 문장을 어떻게 해석하고 있는지 좀더 정확히 파악할 수 있다는 점에서도 유리하다고 한다.
-
-
2. Multi-Head Attention

-
모두가 알다시피 백지장도 맞들면 낫고, 회초리는 여러 개 묶을 경우 부러뜨리기 어렵다. 논문의 저자도 비슷한 생각을 하지 않았을까? Attention이 문맥의 의미를 잘 파악하는 알고리즘이긴 하지만, 단독으로 쓸 경우 자기자신의 의미에만 지나치게 집중할 수 있기에 논문의 저자는 8개의 attention layer를 두고 각각 다른 초기값으로 학습을 진행하였다.
- 각 layer에서 나온 출력은 그대로 합한 뒤 또다른 weight vecotr를 곱해 하나의 vector로 취합하며, 이것이 multi-head attention layer의 최종 출력이 된다.

-
이 방식의 장점은 8개의 서로 다른 representation subspace를 가짐으로써 single-head attention보다 문맥을 더 잘 이해할 수 있게 된다는 것이다.
-
위에서 예시를 들었던 '나는 사과를 먹으려다가 그것이 썩은 부분이 있는 것을 보고 내려놓았다.' 문장을 다시 보자.
-
그것과 사과는 같은 것을 가르키는 것이 맞지만, 또한 동시에 '썩은 부분'과도 관련이 있으며 '내려놓았다'와도 관련이 있다.
-
single-head attention의 경우 이 중 하나의 단어와의 연관성만을 중시할 가능성이 높지만, multi-head attention은 layer를 여러 번 조금 다른 초기 조건으로 학습시킴으로써 '그것'에 관련된 단어에 대해 더 많은 후보군을 제공한다.
-
-
3. Position-Wise Feed-Foward Networks

-
attention layer를 통과한 값들은 fully connected feed-foward network를 지나가게 된다.
-
이때 하나의 인코더 블록 내에서는 다른 문장 혹은 다른 단어들마다 정확하게 동일하게 사용되지만, 인코더 마다는 다른 값을 가지게 된다.
이 과정의 필요성은 논문에서 특별히 언급하지는 않았지만 학습편의성을 위한 것으로 추정된다.
-
Positional Encoding
-
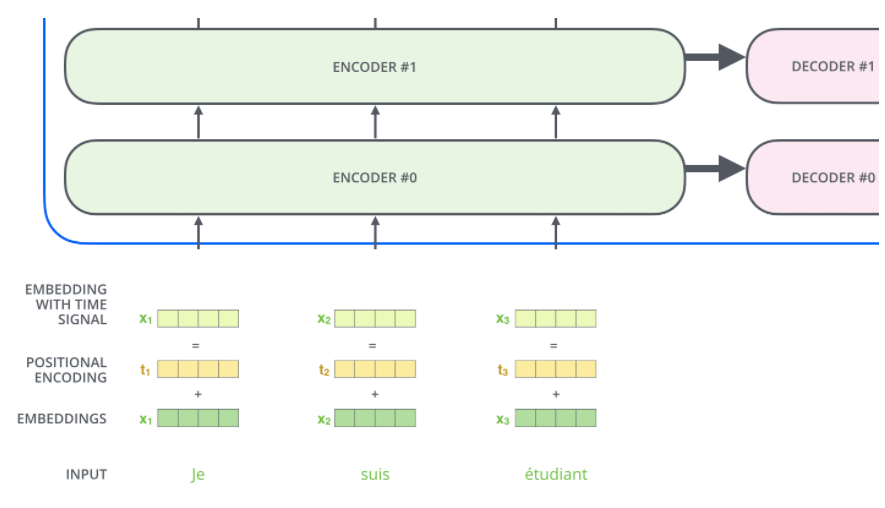
우리는 위에서 단어가 인코더 블록에 들어가기 전에 embedding vector로 변환됨을 보았다. 사실 여기에 한가지가 더 더해진채 인코더 블록에 입력되는데, 그것은 바로 positional encoding이다.
-
여태까지 과정을 잘 복기해보면 단어의 위치정보, 즉 단어들의 순서는 어떤지에 대한 정보가 연산과정 어디에도 포함되지 않았음을 알 수 있다.
-
문장의 뜻을 이해함에 있어 단어의 순서는 중요한 정보이므로 Transformer 모델은 이를 포함하고자 하였다.
-
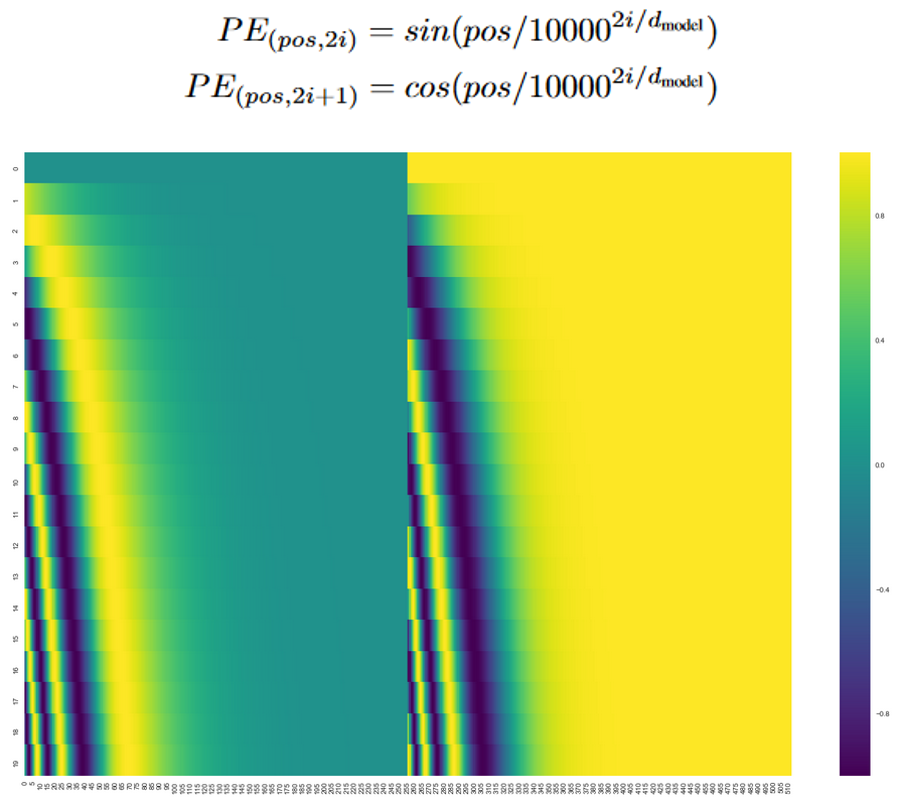
-
Positional encoding vector를 하기 위한 함수는 여러 가지가 있지만 이 논문에서는 sin함수와 cos함수의 합으로 표현(그림x 상단)하였다.
-
그 이유는 함수의 특성상 특정 위치에 대한 positional vector는 다른 위치에 대한 positional vector의 합으로 표현할 수 있기 때문에 모델이 학습당시 보지 못한 길이의 긴 문장을 만나도 대응할 수 있게 되기 때문이다.
Decoder Block
- 그림3에서 알 수 있듯이, 인코더 블록과 디코더 블록은 비슷하지만 약간 다른 구조를 가지고 있다.
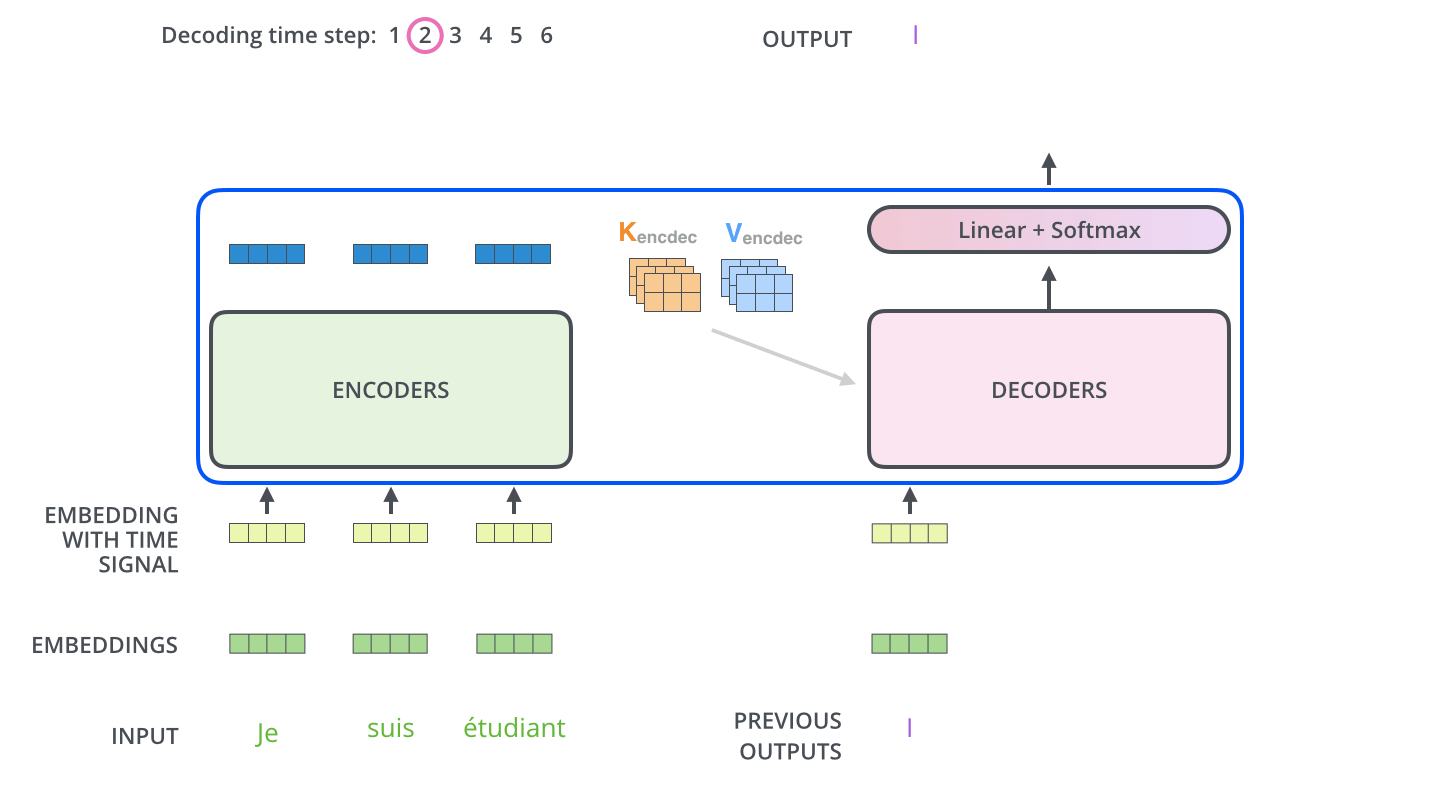
-
먼저 self-attention시 현재 위치의 이전 위치에 대해서만 attention할 수 있도록 이후 위치에 대해서는
-∞로 마스킹을 했다.- 또한 이렇게 통과된 vector중 query만 가져오고, key와 value vector는 인코더 블록의 출력을 가져온다.

- 인코더와 마찬가지로 6개의 블록을 통과하면 그 출력은 FCN(Fully Connected Network)과 Softmax를 거쳐 학습된 단어 데이터베이스 중 가장 관계가 깊어보이는 단어를 출력하게 된다.
Model Summary

Train
-
이제 구체적인 학습과정을 알아보자.
-
우선 loss function을 이해하기 위해서 단순한 예를 들어, 프랑스 단어 'merci'(감사하다)를 영어로 번역하는 상황을 가정해보자.
- 그리고 학습 단계전에 미리 데이터 전처리를 통해 만들 수 있는 단어 데이터베이스에는 <a, am, I, thanks, students, > 6가지 단어가 있다고 가정하자.
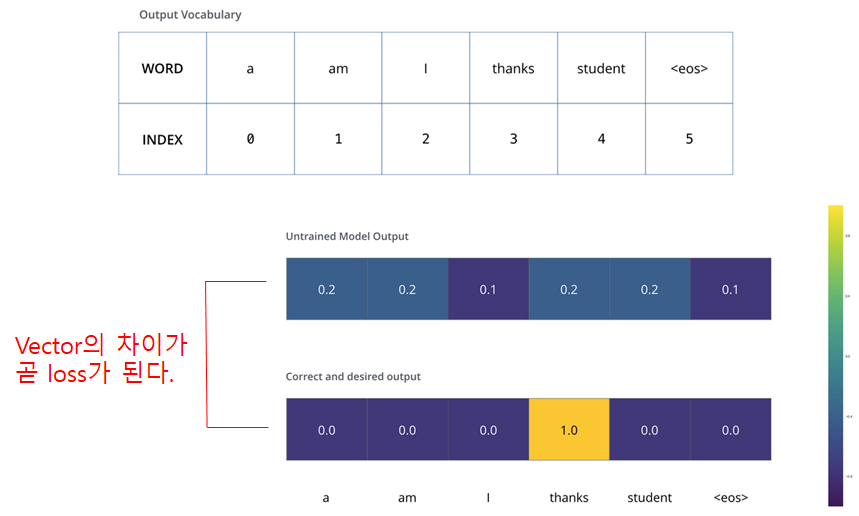
- 처음에는 전혀 학습이 되지 않을 상태이기에 모든 단어에 대해 비슷한 확률값이 나올 것이다.
- 그 출력과 정답 vector의 차이를 backpropergation하여 학습이 진행되면, 점점 merci 입력에 대해 thanks 출력이 나올 확률이 높아지게 된다.
- 이제 조금 더 복잡한 예시로 프랑스어 문장 "je suis étudiant" (나는 학생이다)에 대한 학습 과정을 보자.

-
target vector가 단어들의 list로 바뀌었을 뿐, 같은 과정을 거친다.
-
그런데 다음 단어를 예측할 때, 그자리에 올 단어 중 무조건 가장 높은 확률을 가진 단어만을 골라나가는 것이 올바른 예측방법일까?
- 가령, 산을 오른다고 가정했을 때, 매순간 무조건 가장 경사가 급한 방향으로만 가는 것이 가장 빨리 정상에 도달하는 방법일까?
-
- 위 예시는 각 timestep에서 가장 높은 확률만을 선택했을 때의 결과
- 아래 예시는 2번째 timestep에서 2번째 높은 확률을 선택해서 결과를 만들었을 때의 예시이다.
- 위의 결과는 전체구간에 계산하면 0.048의 확률이지만, 아래의 결과는 0.054이다.
- 이는 특정 timestep에서 국소적으로 살짝 낮은 확률이 있더라도 전체구간에 대한 확률은 더 높을 수 있음을 보여준다.

-
물론 그렇지 않다. 당장 눈앞에 경사가 급한 방향으로 간다해도 사실 그 방향은 멀리 보면 골짜기로 이어져 있을 수도 있는 것이다.
-
비슷한 원리로 Transformer에서도 정답 문장을 예측할 때 각 위치별로 n개의 확률이 높은 단어 후보들에 대해 m번째 timestep까지의 경우를 모두 계산하면서 정답을 찾아간다.
- 이러한 방식을 Beam search라고 하며, n(beam size)과 m(top beams)은 우리가 학습전에 미리 설정할 수 있는 hyperparameter이다.

Result
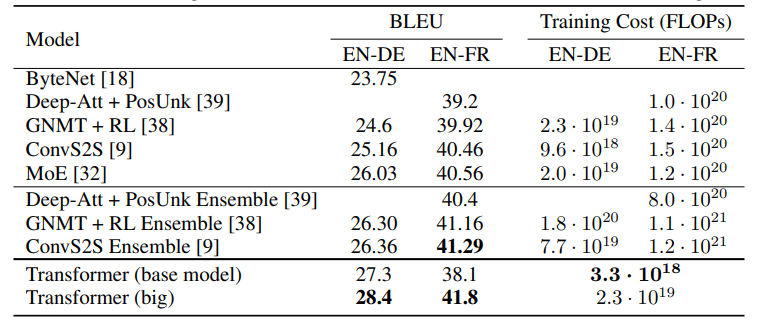
- Transformer는 기존의 CNN, RNN 구조를 전혀 쓰지 않고도 등장하자마자 WMT 2014 English-to-German translation, WMT 2014 English-to-French translation 두 번역 부분에서 SOTA를 차지해서 NLP 연구자들에게 충격을 주었다.
Visualization of an attention layer

- 영어문장 'The animal didn't cross the street because it was too tired.'에 대한 영어-프랑스어 번역 Transformer 모델 인코더에서 5번째 블록의 attention map. 'animal'과 관계깊은 단어로 'it'을 예측하고 있다. 이처럼 visualize를 통해 모델에 대한 직관적인 이해가 쉽다는 점도 Transformer의 장점 중 하나로 꼽힌다.
