CNN 이란?
-
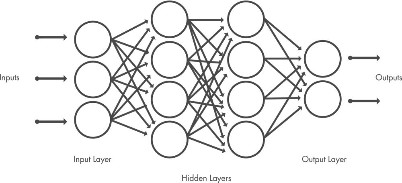
CNN(Convolutional Neural Network)은 주로 이미지나 비디오 인식, 분류 작업에 사용되는 딥러닝 모델의 한 종류입니다.
- CNN은 이미지 데이터를 처리하는 데 매우 효과적이며, 그 구조는 인간의 시각 피질에서 영감을 받았습니다.
-
주요 구성 요소
-
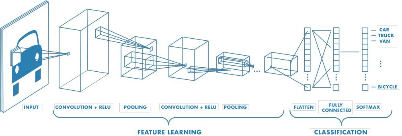
합성곱 층(Convolutional Layer)
-
이 층은 이미지의 특징을 추출하는 역할을 합니다.
-
작은 필터(또는 커널)를 사용하여 입력 이미지에 대해 합성곱 연산을 수행하고, 이를 통해 특징 맵을 생성합니다.
- 필터는 이미지의 특정 패턴이나 엣지를 감지하는 데 사용됩니다.
-
-
풀링 층(Pooling Layer)
-
풀링 층은 특징 맵의 크기를 줄여 계산량을 감소시키고, 모델의 과적합을 방지하는 데 도움을 줍니다.
-
일반적으로 최대 풀링(Max Pooling)이나 평균 풀링(Average Pooling)이 사용됩니다.
-
-
완전 연결 층(Fully Connected Layer)
-
이 층은 추출된 특징을 기반으로 최종 분류를 수행합니다.
-
일반적인 인공신경망과 유사하게 모든 노드가 연결되어 있으며, 최종 출력층에서 클래스에 대한 확률을 제공합니다.
-
-
활성화 함수(Activation Function)
-
각 층의 출력을 비선형적으로 변환하여 모델이 복잡한 패턴을 학습할 수 있도록 합니다.
-
ReLU(Rectified Linear Unit)가 일반적으로 사용됩니다.
ReLU(Rectified Linear Unit) 계층은 음수 값은 0에 매핑하고 양수 값은 그대로 두어서 더 빠르고 효과적인 훈련이 이루어지도록 합니다.
- 이때 활성화된 특징만 다음 계층으로 전달되므로 이를 활성화라고도 합니다. 출처
-
-
-
CNN은 이러한 층들을 쌓아 올려 복잡한 모델을 구성하며, 이미지 분류, 객체 탐지, 얼굴 인식 등 다양한 분야에서 높은 성능을 발휘합니다.
- CNN의 대표적인 아키텍처로는 LeNet, AlexNet, VGG, ResNet 등이 있습니다.
AlexNet, VGG, GoogLeNet, ResNet
1. AlexNet (2012)
-
개발자: Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton
-
특징
-
2012년 ILSVRC에서 우승하며 CNN의 가능성을 널리 알렸습니다.
-
구조: 8개의 레이어 (5개의 합성곱 레이어, 3개의 완전 연결 레이어).
-
기술
-
ReLU 활성화 함수 사용: 비선형성을 도입하여 학습을 가속화.
-
LRN(Local Response Normalization): 특정 부분의 활성화를 높이는 정규화 기법.
-
데이터 증강(Data Augmentation): 좌우 반전, 크롭 등을 통해 데이터셋을 확장.
-
드롭아웃(Dropout): 과적합 방지를 위해 일부 노드를 무작위로 비활성화.
-
-
GPU 활용: 당시 GPU 성능의 한계로 모델을 두 부분으로 나누어 병렬 학습.
-
2. VGG (2014)
-
개발자: Visual Graphics Group, University of Oxford
-
특징
-
구조: 16개(VGG16) 또는 19개(VGG19)의 레이어로 구성.
-
기술:
-
3x3의 작은 필터와 1의 스트라이드를 사용하여 깊이를 증가시킴.
-
단순한 구조로 인해 이해와 구현이 용이.
-
-
장점: 간단한 구조로도 높은 성능을 기록, 널리 사용됨.
-
3. GoogLeNet (Inception, 2014)
-
개발자: Google
-
특징
-
구조: 22개의 레이어, 인셉션 모듈 도입.
-
기술
-
인셉션 모듈: 다양한 크기의 필터를 병렬로 사용하여 네트워크의 폭과 깊이를 확장.
-
1x1 합성곱: 차원 축소 및 계산 효율성 향상.
-
-
장점: VGG보다 깊지만 파라미터 수는 절반 이하로 줄임.
-
4. ResNet (Residual Networks, 2015)
-
개발자: Microsoft Research
-
특징
-
구조: 152개의 레이어, 잔차 학습(residual learning) 도입.
-
기술
-
스킵 연결(skip connection): 이전 레이어의 출력을 다음 레이어의 입력으로 직접 전달.
-
잔차 블록: 입력과 학습된 출력의 차이만을 학습하여 최적화 용이.
-
-
장점: 매우 깊은 네트워크에서도 안정적인 학습 가능, 다양한 대회에서 우수한 성능 기록.
-
