RAG(Retrieval-Augmented Generation) 란?
-
RAG (Retrieval-Augmented Generation)는 생성형 AI 모델의 성능을 향상시키기 위한 기술로, 지식 검색(Retrieval)과 생성(Generation)을 결합하여 대형 언어 모델(LLM)이 더 정확하고 유용한 응답을 생성하도록 합니다.
- 특히 최신 정보나 도메인별 데이터베이스와의 작업에서 자주 활용됩니다.
RAG 작동 원리
- RAG는 크게 두 가지 과정으로 나뉩니다.
-
Retrieval (검색)
-
외부 DB/지식 창고에서 관련 정보를 검색하는 단계.
-
벡터화된 데이터와 벡터 검색 기술을 활용.
-
사용 기술
-
임베딩 모델 (Embedding): 텍스트를 벡터화.
-
벡터 검색 (Vector Search): 유사도 기반 검색 수행.
-
주요 알고리즘: FAISS, Pinecone, Weaviate.
-
-
-
Augmented Generation (보강된 생성)
-
검색 결과를 기반으로, LLM이 프롬프트와 컨텍스트를 활용해 답변 생성.
-
예시 단계
-
사용자 입력 질문 → 검색 수행.
-
관련 문서 검색 후 데이터를 읽음.
-
모델이 검색된 컨텍스트를 바탕으로 응답 생성.
-
-
RAG의 장점
-
최신성과 정확성 보장
- 외부 지식베이스 활용으로 최신 정보를 기반으로 응답 생성 가능.
-
효율적인 데이터 활용
- 대규모 지식베이스를 검색해 필요한 정보만 가져옴.
-
모델 경량화 가능
- 모든 데이터를 모델에 직접 포함시키지 않음.
-
도메인 특화 가능
- 특정 산업/도메인에 맞는 데이터로 정확성 향상.
RAG의 동작 구조
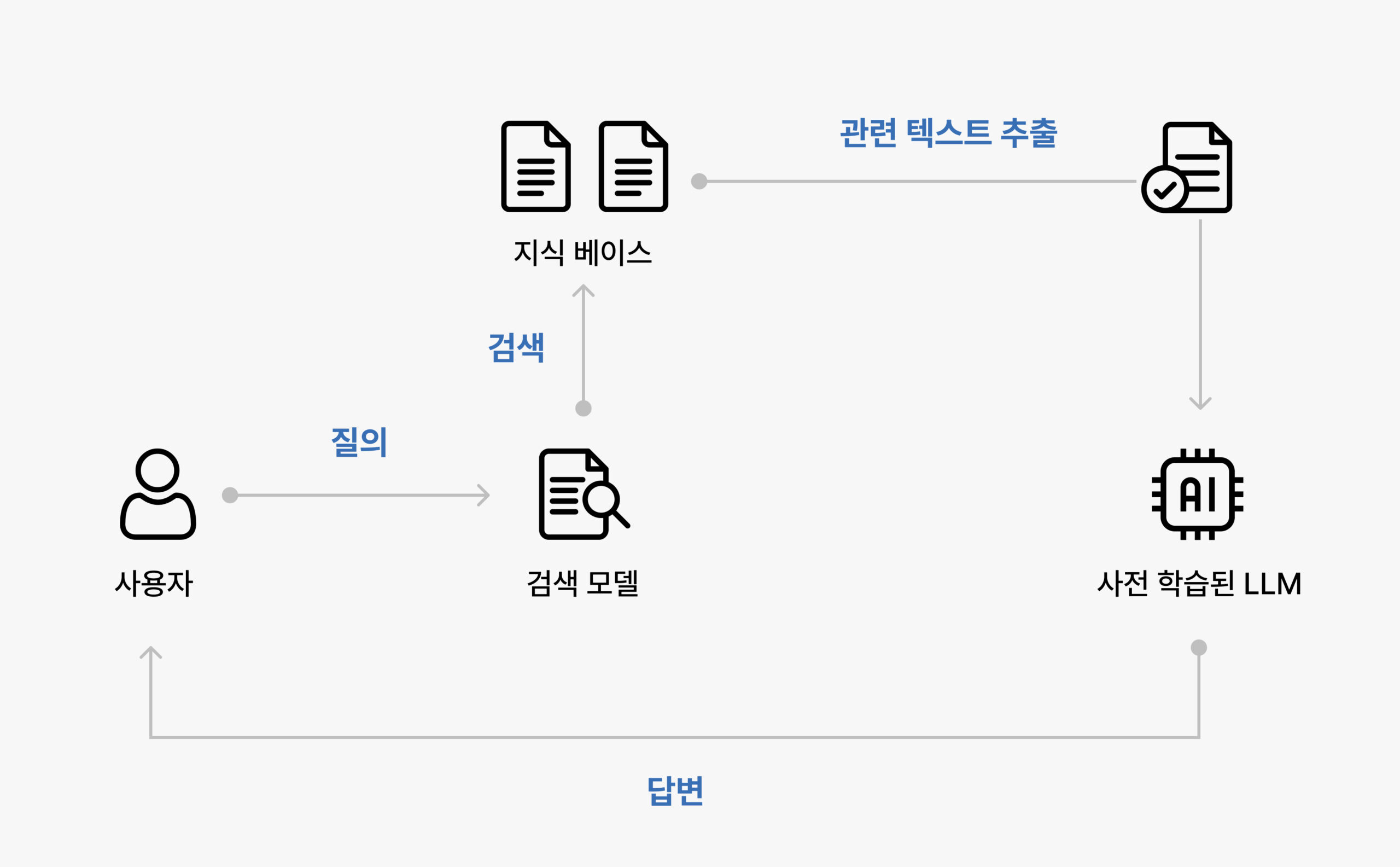
-
단계별 프로세스
-
질문 입력 (Query)
-
질문 벡터화 (Embedding)
-
관련 문서 검색 (Retrieval)
-
프롬프트 생성 (Prompt Augmentation)
-
응답 생성 (Generation)
-
-
시스템 구성
구성 요소 설명 사용자 입력 질문 또는 검색 요청. 예: “기후 변화 연구”벡터 데이터베이스 외부 지식을 벡터화해 저장 및 검색. 텍스트 검색기 벡터 검색 엔진 (예: FAISS, Pinecone). 언어 모델(LLM) 검색된 문서를 프롬프트 보강 후 적합한 응답을 생성. 지식 출력 최종 응답. 사용자 질문에 맞는 컨텍스트 포함.
주요 활용 사례
-
고객 지원
- FAQ 챗봇 설계, 고객 문의 응답 자동화.
-
문서 요약 및 검색
- 대규모 문서에서 필요한 정보 검색 후 요약.
-
의학 및 금융 서비스
- 최신 논문 응답, 금융 보고서 검색 및 분석.
-
교육 및 학습
- 학습 자료 요약 및 질문 응답.
RAG 구현에 필요한 기술
-
벡터 데이터베이스
- 주요 툴: FAISS, Pinecone, Milvus, Weaviate.
-
임베딩 모델
- OpenAI
text-embedding-ada-002, Hugging Face 모델.
- OpenAI
-
생성형 언어 모델
- GPT-4, Anthropic Claude, Google Palm.
-
텍스트 검색 알고리즘
- BM25, Vector Search, Inverted Index.
한계와 도전 과제
-
검색 정보 품질
- 잘못된 정보 검색 시 응답 정확도 저하.
-
도메인 지식 한계
- 설계된 도메인 외 검색 정확도 낮아질 수 있음.
-
대규모 데이터 성능
- 대규모 데이터베이스 부하 시 처리 속도 저하.
-
최신 정보 유지
- 데이터베이스 업데이트 지연 시 정밀성 감소.
RAG 활용 플랫폼
-
OpenAI
- RAG 기반 질문 응답 시스템 구축,
text-embedding-ada-002활용.
- RAG 기반 질문 응답 시스템 구축,
-
LangChain
- Python 프레임워크로 벡터 DB와 LLM 통합.
-
LlamaIndex
- 문서 검색 및 LLM 연결을 위한 도구.
-
Pinecone
- 벡터 검색 솔루션, RAG 통합 지원.

For the sake of someone who studies computer science
실제 시스템에서는 어떻게 사용해야 하는걸까요..?