강화학습(Reinforcement Learning)이란?
-
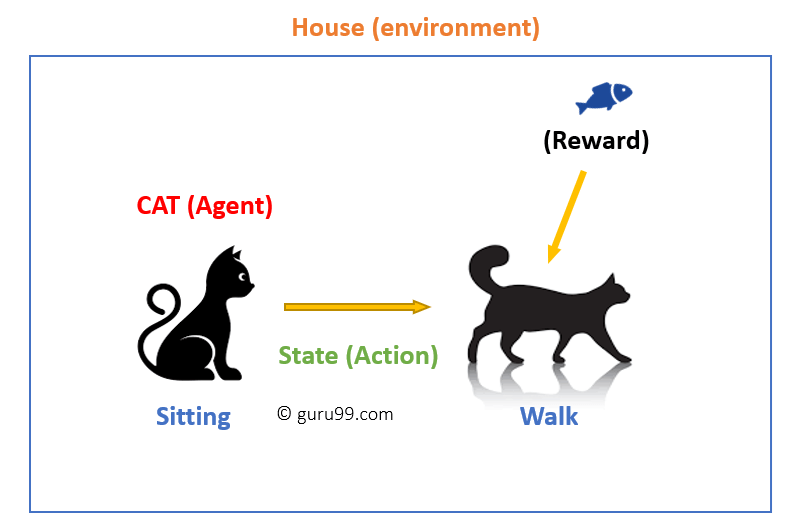
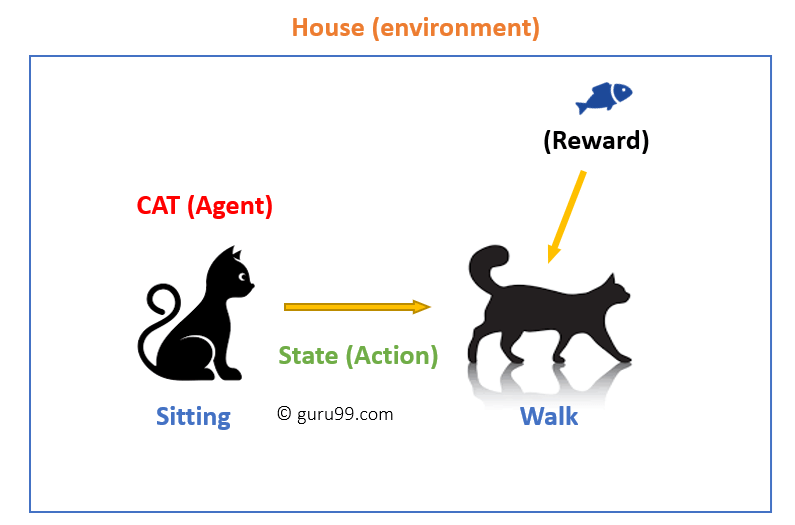
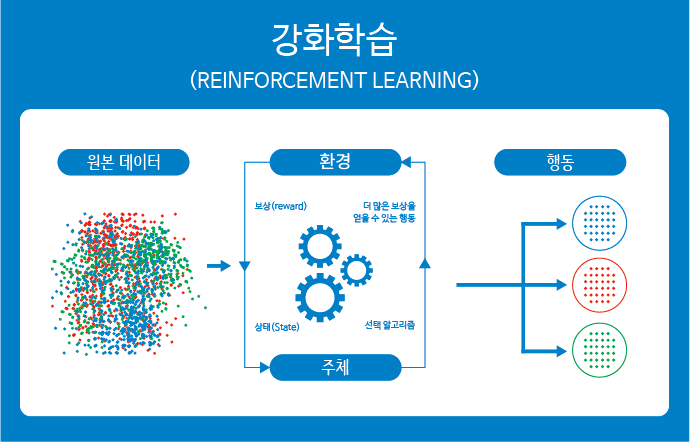
강화학습은 에이전트(Agent)가 환경(Environment)과 상호작용하면서, 보상(Reward) 신호를 통해 최적의 행동(Action) 정책(Policy)을 학습하는 기계 학습 분야입니다.
-
강화학습은 에이전트가 환경과 상호작용하며 최적의 정책을 학습하는 과정입니다.
-
복잡한 상태(State)와 행동(Action) 간의 관계를 추상화하여 에이전트가 환경에서 효율적으로 보상을 극대화할 수 있습니다.
-
신경망은 이러한 상태-행동 관계의 중요 특징을 추출하고 추상화하여 학습을 돕는 핵심 도구입니다.
-
사례로 자율주행차와 Atari 게임 같은 복잡한 문제에서도, 신경망은 데이터에서 학습 가능한 패턴을 추출하고 최적 행동을 결정하도록 에이전트를 도와줍니다.
-
강화학습의 핵심 요소
-
에이전트(Agent)
- 학습을 수행하는 주체로, 환경에서 상태를 관찰하고 행동을 선택합니다.
-
환경(Environment)
- 에이전트와 상호작용하며 행동 결과로 새로운 상태와 보상을 제공합니다.
-
상태(State)
-
현재 환경의 상황을 나타내는 정보.
-
에이전트는 상태를 기반으로 다음 행동을 결정합니다.
-
-
행동(Action)
- 에이전트가 특정 상태에서 선택할 수 있는 모든 가능한 행동.
-
보상(Reward)
-
특정 상태에서 행동을 수행한 결과로 환경이 에이전트에게 제공하는 신호.
- 목표: 보상을 최대화하는 방향으로 학습.
-
-
정책(Policy)
- 상태에 따라 행동을 선택하는 전략. 에이전트의 목표는 최적의 정책을 학습하는 것입니다.
-
보상 함수(Reward Function)
- 행동의 결과에 따라 보상을 정의하는 수학적 함수. 학습의 성패를 좌우합니다.
강화학습의 과정
-
상호작용(Interaction)
- 에이전트는 현 상태에서 행동을 선택하고, 그 결과로 새로운 상태와 보상을 받습니다.
-
피드백 기반 학습
- 보상을 최대화하기 위해 에이전트는 행동을 수정하며 학습을 진행합니다.
-
정책 업데이트
- 에이전트는 현재 정책을 개선하여 점점 더 나은 행동을 학습합니다.
-
목표
- 누적 보상(Return)을 최대화하는 최적 정책을 학습하는 것입니다.
상태-행동 관계(State-Action Relationship)
-
상태-행동 관계란, 특정 상태에서 에이전트가 취할 수 있는 행동과 그 행동의 결과 사이의 관계를 말합니다.
-
에이전트는 현재 상태(State)를 보고 행동(Action)을 선택하며, 이 선택이 환경에서 어떤 결과를 만들고 보상이 어떻게 주어지는지 학습해야 합니다.
상태(State)란?
- 상태는 에이전트가 현재 환경에서 얻는 정보로, 무엇을 해야 할지 결정하는 기초 데이터입니다.
-
특징
-
현재 상태는 환경의 상황을 나타냄.
- 예: 자율주행차의 도로 정보, 로봇의 위치 데이터.
-
고차원 데이터로 표현될 수도 있음.
- 예: 이미지, 센서 데이터, 신호 등.
-
-
예시
-
자율주행
- 상태는 차선의 위치, 신호등의 색상, 전방 차량과의 거리 등.
-
게임(Atari)
- 상태는 게임 화면의 현재 화면(픽셀 정보).
-
행동(Action)란?
- 행동은 에이전트가 현재 상태에서 선택할 수 있는 모든 가능한 움직임 또는 명령입니다.
-
특징
-
에이전트는 하나의 행동을 선택하여 환경에 영향을 미칩니다.
- 예: 핸들 조작, 점프, 공격 등.
-
행동은 이산적(Discrete)일 수도 있고 연속적(Continuous)일 수도 있습니다.
- 예: 자율주행의 경우, 핸들 조작 각도는 연속적이고, 브레이크/가속은 이산적입니다.
-
-
예시
-
자율주행
- 현재 상태에서 "가속", "감속", "좌회전", "우회전" 등의 행동 선택.
-
로봇 제어
- 로봇팔이 특정 방향으로 움직이는 행동.
-
상태-행동 관계를 추상화한다는 것
- 복잡한 환경에서 상태-행동 관계를 추상화한다는 것은, 고차원의 상태 데이터와 행동 간 관계를 추출하고 압축하여 의미 있는 패턴으로 표현하는 것을 의미합니다.
왜 추상화가 필요한가?
- 복잡한 환경에서는 데이터가 너무 방대하거나 비선형적인 패턴이 많아, 이를 단순히 수학적 관계만으로 학습하기 어렵습니다. 이때, 신경망을 활용하여 중요한 정보만 뽑아내고 이해하기 쉬운 형태로 재구성(추상화)합니다.
추상화의 역할
-
중요한 관계 파악
- 상태에 포함된 복잡한 원본 데이터를 이해하기 쉬운 특징(feature)으로 변환.
-
행동 결정 간소화
- 고차원의 상태 정보를 효율적으로 처리하여, 적합한 행동을 빠르게 결정.
-
효율적인 정책 학습
- 낮은 차원의 정보를 기반으로 더 빠르고 정확한 강화학습 가능.
신경망을 활용한 상태-행동 추상화
- 강화학습에서 신경망(Deep Neural Network)은 복잡한 상태(State)-행동(Action) 관계의 패턴을 추출하고 학습하는 데 사용됩니다.
신경망의 역할
-
특징 추출
- 이미지, 센서 데이터, 게임 화면 등과 같은 복잡한 상태를 입력받아, 의미 있는 특징(feature)을 뽑아냅니다.
-
상태-행동 매핑
-
추출된 특징과 행동 간의 관계를 학습.
- 예: "현재 상태에서 '좌회전'이 최적의 행동"이라는 패턴을 학습.
-
-
정책 학습:
- 신경망은 보상을 최대화하는 정책(행동 확률 분포 또는 Q-값)을 학습합니다.
예시: 상태-행동 관계 추상화
1. 자율주행차
-
상태: 차량 센서와 카메라에서 수집된 이미지 데이터.
-
행동: 가속, 브레이크, 좌회전, 우회전.
-
추상화 과정
-
CNN(합성곱 신경망)을 통해 도로의 차선, 신호를 인식 및 처리.
-
추출된 정보를 기반으로 최적의 행동(가속 또는 회전)을 선택.
-
2. Atari 게임
-
상태: 2D 게임 화면의 픽셀 데이터.
-
행동: 좌로 이동, 우로 이동, 발사 등의 선택 가능.
-
추상화 과정
-
게임 화면을 CNN으로 처리하여 적 위치, 장애물, 캐릭터 상태 등을 추출.
-
상태를 벡터로 추상화하여 행동과 연계된 규칙 학습.
-
