Deep Reinforcement Learning (Deep RL) 이란?
-
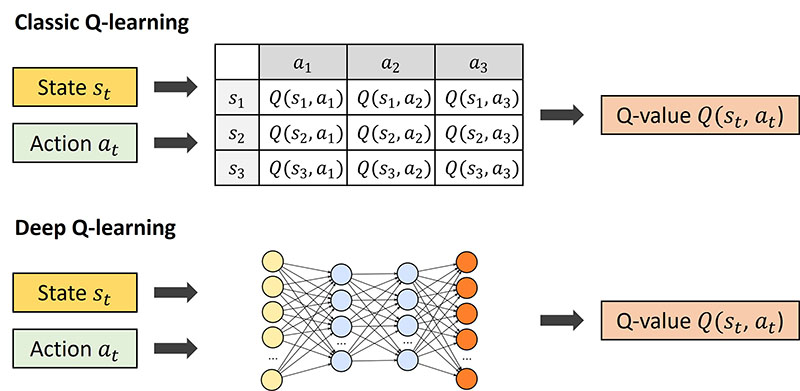
Deep Reinforcement Learning(Deep RL, 딥 강화학습)은 강화학습(Reinforcement Learning)과 딥러닝(Deep Learning)을 결합한 기술로, 복잡한 환경의 상태와 행동 관계를 신경망으로 학습하는 방법입니다.
-
이는 학습 에이전트가 주어진 환경에서 보상을 최대화하기 위해 최적의 행동 정책을 학습하는 강화학습의 목표를 딥러닝의 표현 학습 능력으로 확장한 기술입니다.
-
특히 딥러닝의 특징 추출 능력을 강화학습의 목표 지향적 학습과 결합하여 놀라운 성과를 달성한 기술입니다.
- 그러나 여전히 계산적 비용과 데이터 효율성 문제 등의 한계가 존재하며, 이에 대한 연구가 지속되고 있습니다.
-
-
딥 강화학습은 특히 고차원 데이터(예: 이미지)나 매우 복잡한 상태 공간을 갖는 문제를 처리하는 데 강력합니다.
Deep RL의 개념
강화학습
-
에이전트가 환경과 상호작용하며, 환경에서의 상태(state)를 관찰하고 행동(action)을 선택하여 보상(reward)을 받습니다.
- 목표는 보상을 최대화하는 최적의 정책(policy, π)을 학습하는 것입니다.
딥러닝
-
딥러닝에서는 신경망(Deep Neural Network, DNN)을 사용하여 데이터를 통해 패턴을 학습합니다.
- 딥 강화학습에서는 신경망이 상태(state)를 입력받아 행동(action)에 대한 값을 출력하거나 정책을 직접 학습합니다.
Deep RL의 결합
-
복잡한 환경에서의 상태-행동 관계를 추상화하는 데 신경망을 활용합니다.
-
예: 픽셀 수준의 이미지 데이터에서 에이전트가 "현재 상태가 무엇인지" 학습한 뒤, 이를 기반으로 최적의 행동을 학습합니다.
Deep RL의 작업 흐름
1. 에이전트와 환경
-
에이전트는 환경과 상호작용을 통해 상태(state)를 관찰하고 행동(action)을 선택합니다.
-
각 행동에 따라 보상(reward)을 받고 새로운 상태로 전환됩니다.
2. 신경망을 사용한 학습
-
에이전트는 딥러닝 모델(DNN)을 활용하여 상태와 행동의 관계를 학습합니다.
-
예: 상태 공간이 픽셀로 이루어진 이미지라면, CNN(합성곱 신경망)을 활용해 의미 있는 특징을 추출하고,
학습된 특징에 따라 행동을 예측합니다.
3. 보상 기반 최적화
-
보상을 최대화하기 위해 신경망의 파라미터를 업데이트합니다.
-
에이전트는 지속적으로 환경과 상호작용하며, 자신의 행동 정책을 개선해 나갑니다.
Deep RL의 주요 알고리즘
값 기반(Value-based)
-
값 기반 알고리즘은 Q-값을 추정하여 최적 행동을 선택합니다.
-
DQN(Deep Q-Network)
-
딥러닝을 활용해 상태와 행동의 가치(Q값)를 학습합니다.
-
최적의 행동을 선택하기 위해 다음 상태에서의 최대 Q값을 기반으로 의사결정을 수행합니다.
-
예: Atari 게임 플레이 (픽셀 데이터를 입력으로 처리).
-
정책 기반(Policy-based)
- 정책 기반 알고리즘은 행동 정책(π)을 직접 최적화합니다.
-
REINFORCE
- 정책(행동 확률 분포)을 신경망으로 학습합니다.
- 보상 신호를 따라 행동 확률을 최대화합니다.
-
PPO(Proximal Policy Optimization)
- 안정성과 효율성을 개선한 정책 기반 알고리즘입니다.
Actor-Critic
- Actor-Critic 방식은 정책 기반(Actor)과 값 기반(Critic)을 결합하여 학습합니다.
-
A3C (Asynchronous Advantage Actor-Critic)
- 병렬로 여러 에이전트를 학습시켜 학습 속도와 성능을 개선합니다.
-
SAC (Soft Actor-Critic)
- 탐색-활용(trade-off)을 더 효과적으로 수행하여 안정적인 성능을 제공합니다.
Deep RL의 주요 응용 분야
게임 AI
-
Atari 게임, StarCraft, Dota2, AlphaGo(바둑) 등에서 뛰어난 성과를 보임.
-
학습한 에이전트가 최고의 인간 플레이어와 경쟁하거나 이를 능가하는 사례 다수.
자율주행
- 자율주행차가 환경을 인식하고 최적의 경로를 학습하도록 돕는 데 사용됩니다.
로봇공학
- 로봇이 특정 작업(예: 물건 잡기, 조립)을 수행하거나 복잡한 환경에서 동작을 학습합니다.
금융 모델링
- 주식 거래나 포트폴리오 관리에서 최적의 행동을 학습하여 수익을 극대화합니다.
의료 및 헬스케어
- 치료 조합을 최적화하거나 환자의 건강 상태에 따른 맞춤형 치료 계획을 학습합니다.
Deep RL의 장점과 한계
장점
-
고차원 데이터 처리
- 이미지나 비디오와 같은 복잡한 데이터에서도 학습이 가능합니다.
-
일반화 능력
- 환경 변화에도 적응할 수 있는 정책 학습이 가능합니다.
-
강력한 성능
- 복잡하고 비선형적인 관계를 학습해 매우 높은 성능을 보여줍니다.
한계
-
샘플 효율성 문제
-
환경과의 상호작용 데이터를 많이 필요로 하기 때문에, 학습 시간이 길고 비용이 높습니다.
- 예: 자율주행 학습에서는 수백만 번의 시뮬레이션이 필요합니다.
-
-
불안정한 학습
- 환경, 보상 구조, 네트워크 설계에 따라 학습이 매우 불안정하거나 학습 실패 가능성도 높습니다.
-
해석 가능성 부족
- 신경망 내부 구조 때문에 에이전트의 행동을 해석하거나 신뢰하기 어려운 경우가 있습니다.
-
현실 적용 어려움
- 시뮬레이션 환경에서는 성과가 좋을 수 있으나, 실제 물리적 환경이나 복잡한 환경에서는 적용하기 어렵거나 부정확할 수 있습니다.
