
CHAPTER 4 - 데이터 요약하기
4-1. 통계로 요약하기
핵심 키워드
평균 중앙값 분위수 분산 표준편차 최빈값
기술통계 구하기
기술통계(요약통계)는 데이터를 설명하는 방법이다. 통계량을 통해 전체 데이터의 특징을 요약하거나 데이터를 시각화하여 설명한다. 이러한 방식은 EDA(탐색적 데이터 분석)이라고도 한다.
통계량은 평균, 중앙값, 최솟값, 최댓값, 분위수, 분산, 표준편차, 최빈값이 있다.
판다스의 describe() 메서드는 데이터프레임의 기본적인 통계량을 요약해서 보여준다. 디폴트로 수치형 열(번호나 발행년도 같은)에 대한 요약통계를 보여준다.
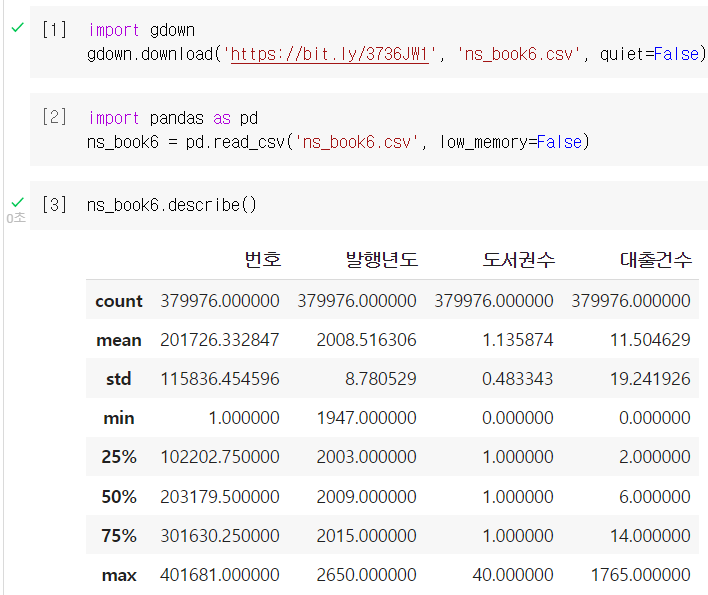
- count: 누락된 값을 제외한 데이터의 개수
- mean: 평균
- std: 표준편차
- min: 최솟값
- 50%: 중앙값
- 25%와 75%: 순서대로 놨을 때 25%와 75% 지점에 놓인 값
- max: 최댓값
예를 들어 대출건수의 평균이 11.5라면 평균적으로 한 권의 도서가 11.5번 대출되었다고 해석할 수 있다.
그런데 도서권수의 최솟값이 0이다. 실제 도서가 없는데도 대출 데이터에 포함되었나보다.
도서권수가 0인 도서의 행 개수를 찾아보면 3206개로 전체 데이터의 1%도 되지 않기 때문에 의미없는 데이터라고 판단했다.
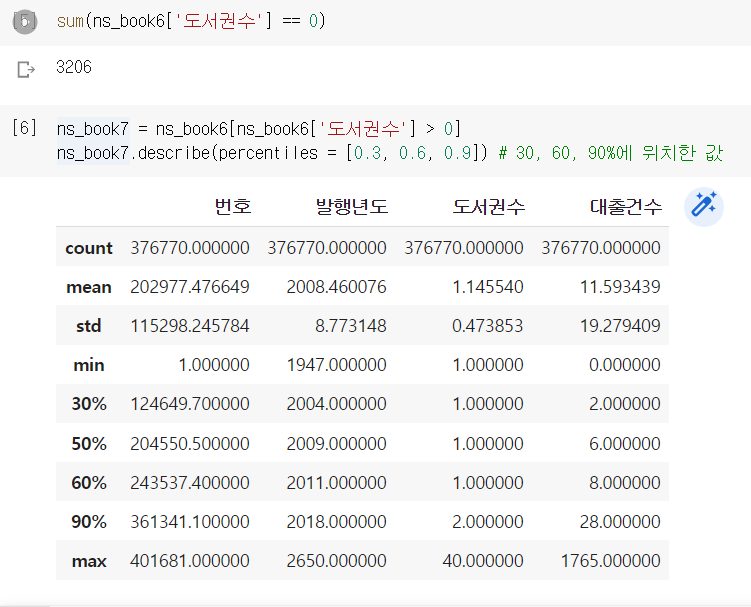
원하는 위치의 값을 보고싶다면 percentiles 매개변수에 위치를 지정한다.
수치가 아닌 다른 데이터타입의 열에 해당하는 기술통계 확인은 include 매개변수에 타입을 지정하면 된다.
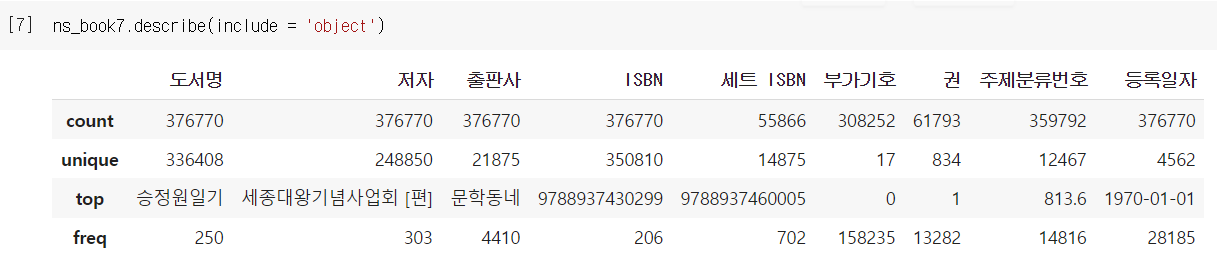
- unique: 고유한 값의 개수
- top: 최빈값(가장 많이 등장하는 값)
- freq: top 행에 등장하는 항목의 빈도 수
평균
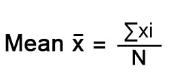
평균은 숫자 값을 모두 더해 개수로 나눈 것이다.
예를 들어 대출건수에 대한 평균은 대출건수 열의 첫 번째 인덱스부터 마지막 인덱스까지 모두 더한 후 인덱스 개수로 나누면 된다.
판다스에서는 데이터프레임과 시리즈 객체의 평균을 mean() 메서드로 구할 수 있다.
중앙값
중앙값은 전체 데이터를 순서대로 쭉 늘어 놓았을 때 중앙에 위치한 값이다.
describe() 메서드의 50%에 해당하는 값이 바로 중앙값에 해당된다.
판다스에서 median() 메서드로 구할 수 있다.
최댓값과 최댓값
중앙값과 더불어 통계량에서 가장 자주 사용하는 값은 최솟값, 최댓값이다.
판다스에서 min() 과 max()로 구할 수 있다.
분위수
분위수(quantile)는 데이터를 순서대로 늘어 놓았을 때 이를 균등한 간격으로 나누는 기준점이다.
가장 많이 사용하는 사분위수는 순서대로 정렬된 데이터를 네 구간으로 나눈다.
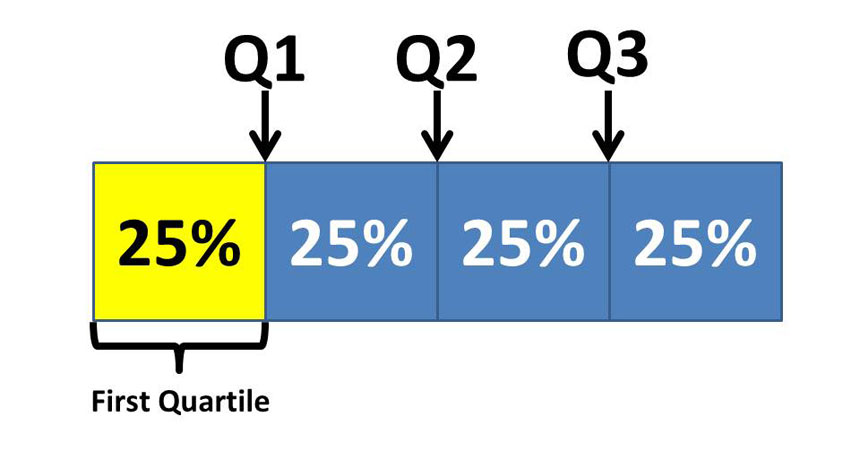
따라서 사분위수는 Q1, Q2, Q3 3개가 나오고 각각 25%, 50%, 75%에 해당한다. 예를 들어 하위 25%에 해당하는 값은 제1사분위수(first quantile)라고 한다.
판다스에서 분위수 값을 계산할 때는 quantile() 메서드를 사용한다.
여러 개의 분위수를 지정하면 각 분위수에 해당하는 값을 담은 시리즈 객체를 반환한다.
quantile() 메서드는 보간(interpolation)을 통해서 분위수를 구한다. interpolation 매개변수가 기본값(linear)이면 선형보간하여(양쪽 분위수에 비례하여) 결정된다.
특정 백분위수를 구할 때는 메서드를 사용하는 것 보다 불리언 배열을 사용해서 비율을 계산하는 것이 더 정확하다.
분산과 표준편차
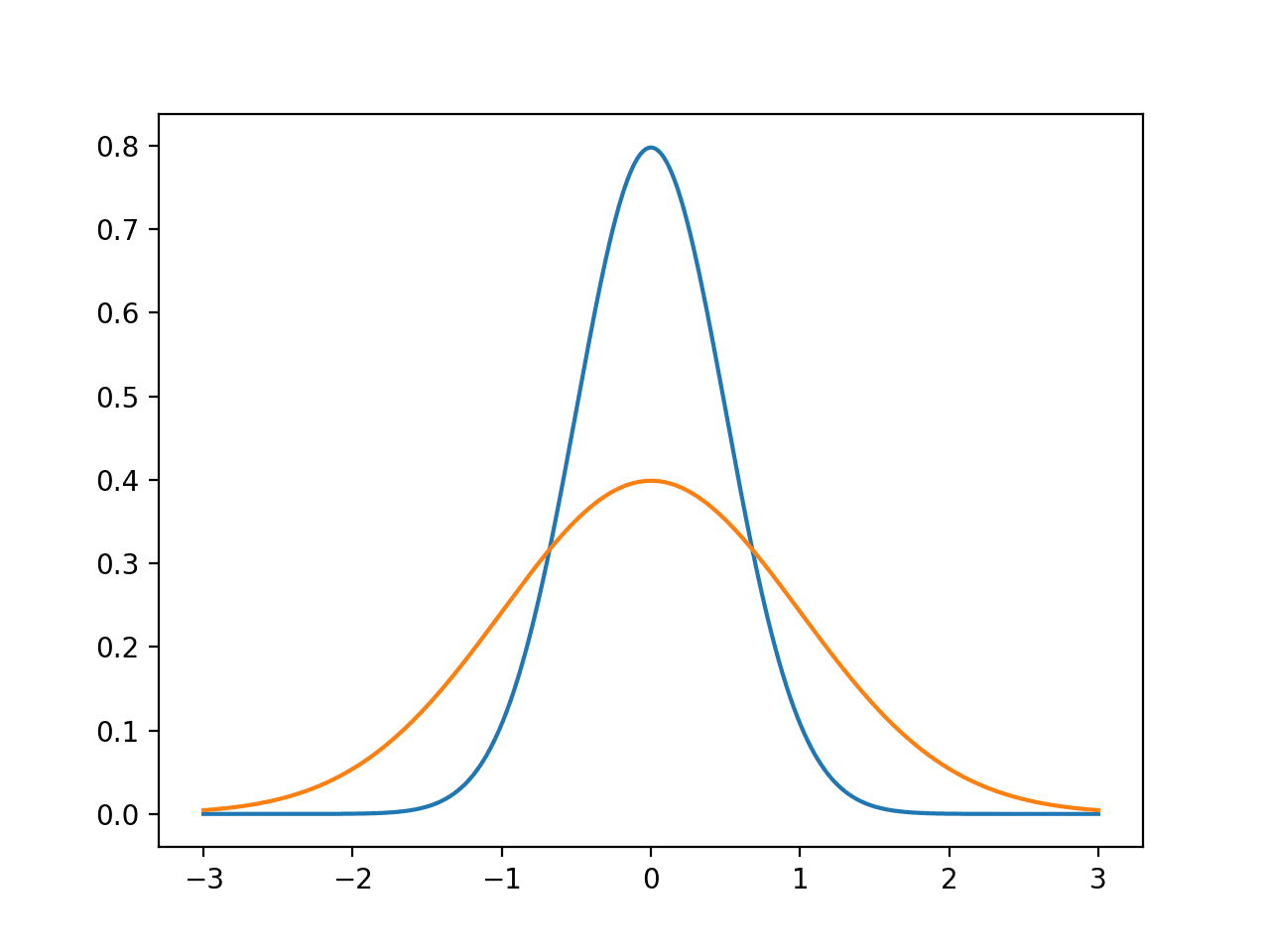
분산(variance)은 평균으로부터 데이터가 얼마나 퍼져있는지를 나타내는 통계량이다. 데이터가 가운데에 몰려있다면 분산이 작고, 넓게 퍼져있다면 분산이 크다.

분산은 데이터의 각 값에서 평균을 뺀 다음 제곱한 후 평균처럼 샘플 개수로 나눠 구할 수 있다.
표준편차(standard division)는 분산에 루트를 취해서 구할 수 있다.
표준편차는 평균을 중심으로 데이터가 대략 얼만큼 떨어져 분포해있는지를 의미한다.
판다스에서는 var() 메서드로 분산을, std() 메서드로 표준편차를 구한다.
최빈값
최빈값(mode)은 데이터에서 가장 많이 등장하는 값이다. 앞에서 describe(include = 'object')의 결과로 나온 top행의 값이 바로 최빈값이다.
판다스에서 mode() 메서드로 구할 수 있다.


데이터프레임에서 기술통계 구하기
위의 메서드들을 데이터프레임에서 사용할 때는 수치형 열만 연산할 수 있기 때문에 해당 열에만 적용되도록 numeric_only 매개변수를 True로 지정해야 한다.
만약 numeric_only 매개변수를 지정하지 않으면 모든 데이터타입 열에 대해 메서드를 수행하기 때문에 실행시간이 매우 오래 걸리고 결국 경고가 발생한다.

