Intro
GAN에서 다루고자 하는 모든 데이터는 측정할 때 마다 다른 값을 가지는 확률분포의 랜덤변수이다.
랜덤변수에 대한 확률분포를 안다는 이야기는 데이터에 대한 전부를 이해하고 있는 것과 같다.
다시말해, 확률분포를 알면 그 데이터의 예측 기댓값, 데이터의 분산을 즉각 알아낼 수 있어 데이터의 통계적 특성을 바로 분석할 수 있으며, 주어진 확률분포를 따르도록 데이터를 임의 생성하면 그 데이터는 확률분포를 구할 때 사용한 원 데이터와 유사한 값을 가진다. 즉, GAN과 같은 비지도학습이 가능한 머신러닝 알고리즘으로 데이터에 대한 확률분포를 모델링 할 수 있게 되면, 원 데이터와 확률분포를 정확히 공유하는 무한히 많은 새로운 데이터를 생성할 수 있다.
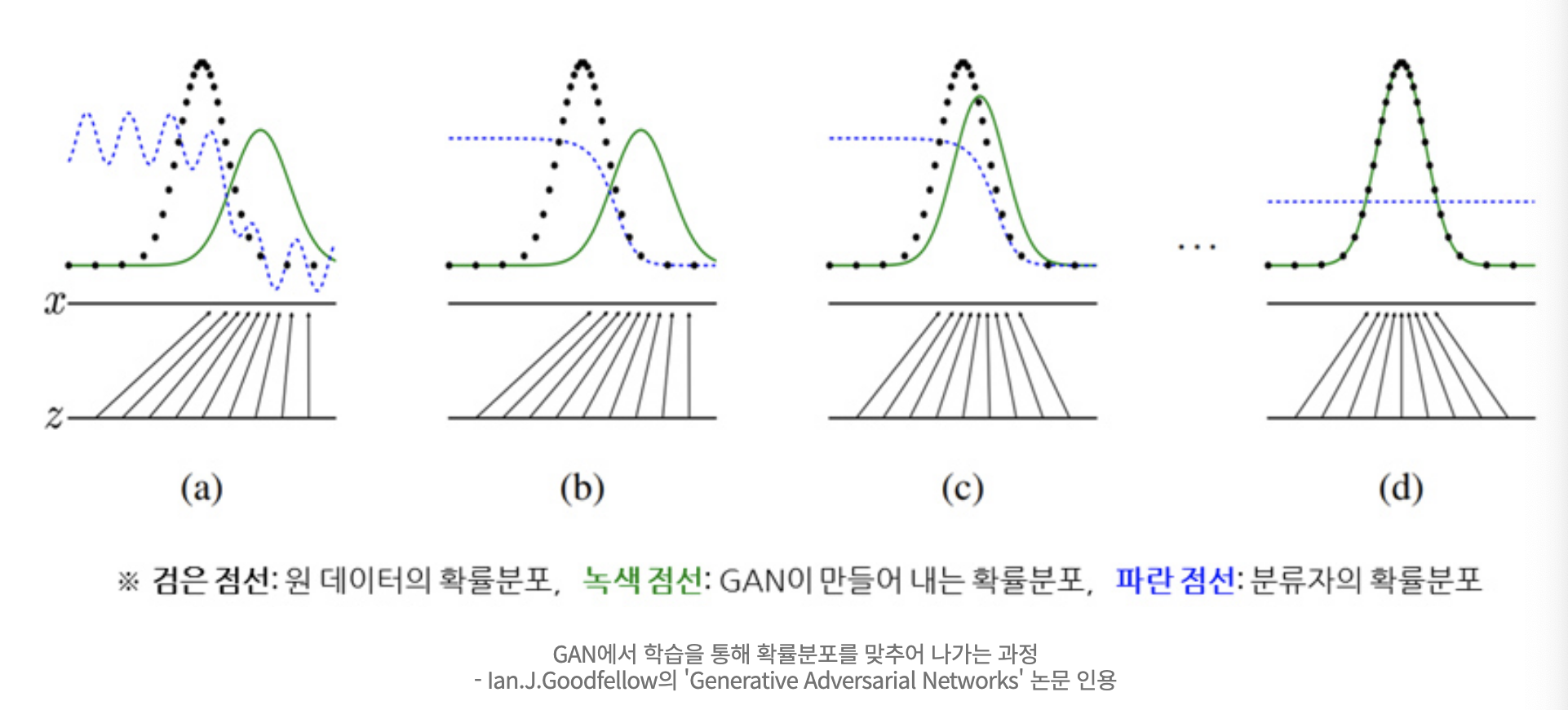
a->d 로 학습이 진행됨에 따라 GAN이 만들어 내는 확률분포와 점점 동일해지고 있다. 이렇게 되면 파란색 점선인 Discriminator D는 더 이상 분류를 해도 의미가 없는 0.5라는 확률 값을 반환한다. 이것은 진실이냐? 거짓이냐? GAN이 맞출 확률이 절반이 되어버려 Discriminator의 의미가 없게 된다. 0.5가 결론적으로 실제 데이터와 거의 유사한 데이터를 만들어 낼 수 있는 상황으로 본다.
Ref)
https://www.samsungsds.com/kr/insights/Generative-adversarial-network-AI.html

Innovation is mine