Intro
EfficientNet: CNN을 위한 모델 스케일링
2019년을 강타한 모델
적은 파라미터 대비 압도적인 성능이 특징이다.
모델 성능 = resolution x depth x width (이 셋의 최적 밸런스가 핵심)

CNN은 일반적으로 고정된 자원의 budget에서 개발되었고, 그리고 나서 더 많은 자원을 사용할 수 있다면 더 나은 정확도를 위해 확장한다.
더 나아가 우리는 새로운 베이스라인 네트워크 디자인과 이전ConvNets보다 더 나은 EfficientNet이라 불리는 모델의 가족을 얻기위해 신경 구조 써치(Neural sa 를 사용한다.
스케일링 업 ConvNets은 better accuracy를 위해 넓게 사용되어지고 있다.
예를 들어, ResNet은 확장되어질 수 있다. ResNet-18에서 RestNet-200으로, 더 많은 레이어를 사용함으로써.;
최근 GPipe는 4배 더 넓은 베이스라인 모델을 가지고 확장하여 84.3%의 ImageNet top-1 정확도를 달성했다.
그러나 ConvNets의 확장의 프로세스는 잘 이해되지 않아 왔다 그리고 현재 매우 많은 방법이 있다.
가장 많은 방법은 그들의 depth와 width를 가지고 ConvNets을 확장하는 방법이다.
다른 가장 적은 , 그러나 증가하는 인기의 메소드는 이미지 리솔루션에 의해 모델을 확장하는 것이다.
이전 작업에서 이 것은 3차원(depth, width 그리고 이미지 사이즈)를 하나로 스케일 하기 위해 일반적이다.
2차원 또는 3차원 확장이 가능하지만 임의로, 임의의 크기를 조정하려면 지루한 수동 조정이 필요합니다.
여전히 종종 차선의 정확도와 효율성을 제공합니다.
이 학습에서 우리는 ConvNet의 스케일링을 위해 학습과 재생각하기를 원한다.
특히, 우리는 중요한 질문을 연구한다. 더 좋은 정확도와 효율을 달성할 수 있는 ConvNet을 확장하기 위한 원칙의 방법이 맞는가?
우리의 경험적 연구는 모든 것의 균형을 맞추는 것이 중요하다는 것을 보여준다.
네트워크 너비/깊이/해상도의 차원과 놀랍게도 이러한 균형은 단순히 각각의 크기를 조정하여 달성할 수 있다.
EfficientNet은 이 세 가지를 효율적으로 조절하는 compound scailing 방법을 제안하다.
이 관찰을 기초로, 우리는 심플함, 아직 효과적이지 않은 조합 스케일링 모델을 제안한다.
Unlike conventional practice that arbitrary scales these factors, our method uniformly scales network width, depth and resolution with a set of fixed scaling coefficients.
이러한 요소를 임의적으로 조정하는 기존 방식과 달리 우리의 방법은 고정된 크기 조정 계수 세트를 사용하여 네트워크 너비, 깊이 및 해상도를 균일하게 조정합니다.
예를 들어 우리는 2^n배 더 계산적 리소스를 사용한다면, 오리지날 작은 모델의 작은 그리드 서치로 결정된(알파, 베타, 감마)로 인해 간단하게 네트워크 깊이를 증가할 수 있다.
- 모델 스케일링 예시
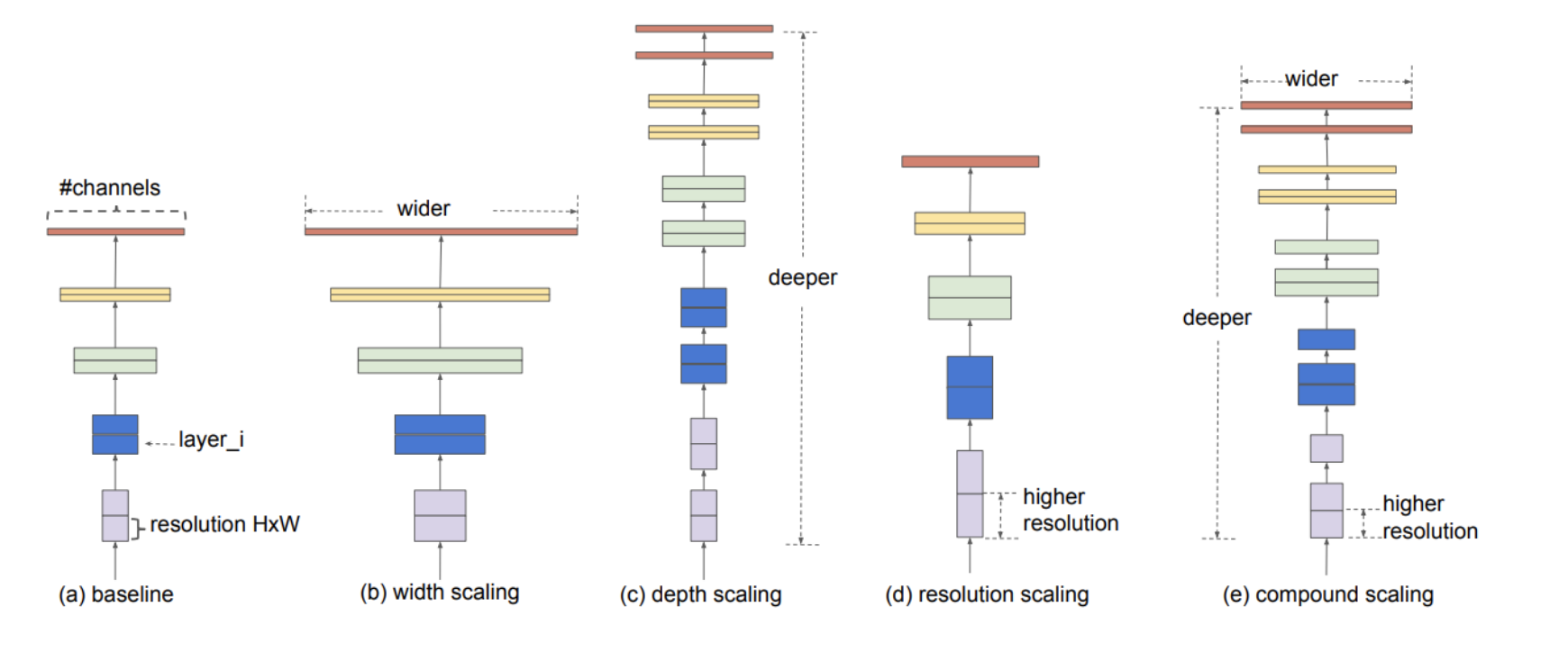
필터(채널)의 개수를 늘리는 wide scailing (MobileNet, shuffleNet)
layer의 개수를 늘리는 depth scailing (ResNet이 대표적)
input이미지의 해상도를 높이는 resolution scailing
우리의 목적은 compound scailing!
그림을 보면 depth/width/resolution을 다 키웠다.
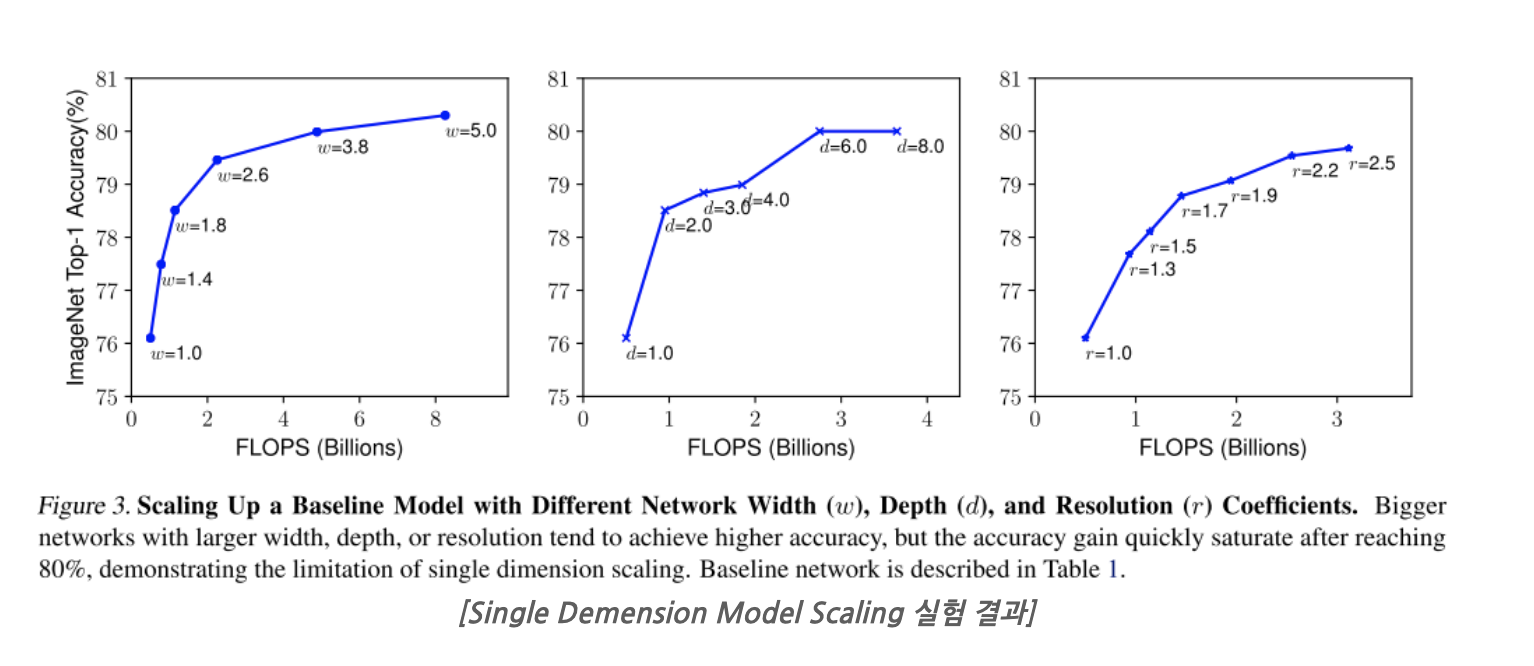
(*FLOPS는 높을수록 느리다.)
w = 너비
d = 깊이
r = 입력 이미지 해상도
- 실험(width를 고정하고 d와 r을 바꿔가며)
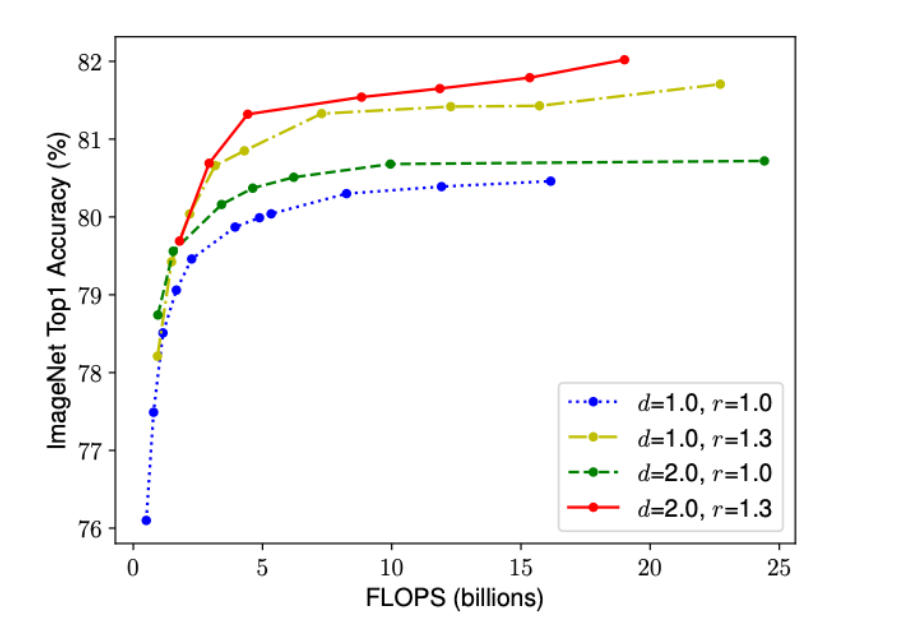
depth보다 resolution가 정확도에 더 예민한 효과를 보인다.
기존 ConvNet보다 최대 21배까지 매개변수를 줄인다.
Related Work
- ConvNet 정확도:
GoogleNet(6.8 M/ 74.8 %) → SENet(145 M/ 82.7 %) → GPipe(557M / 84.3 %) - ConvNet 효율성:
종종 Over-Parameterized 됨 - Model Scailing:
다양한 리소스 제약에 맞게 ConvNet을 확장하는 방법은 많이 있다.
- ResNet- 스케일 다운할 수 있다.(depth를 조절함으로써)
- WideResNet&MobileNets- 네트워크 width로 확장될 수 있다.
이 것은 bigger input image size로 정확도를 더 FLOPS의 오버해드로 인해 높일 수 있다.
** FLOPS(FLoating point OPerationS):
딥러닝 모델이 초당 얼마나 빠르게 동작하는지에 관한 연산량 계산법
Compound Model Scailing
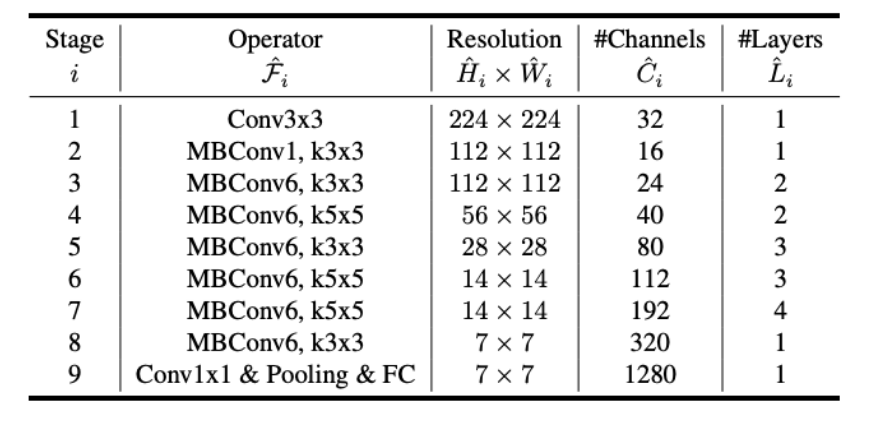
resolution, depth, width를 최적으로 조정하기 위해 baseline network의 구조를 미리 찾고 고정해둔다.
이 세 가지 scailing factor를 동시에 고려하는 compound scailing
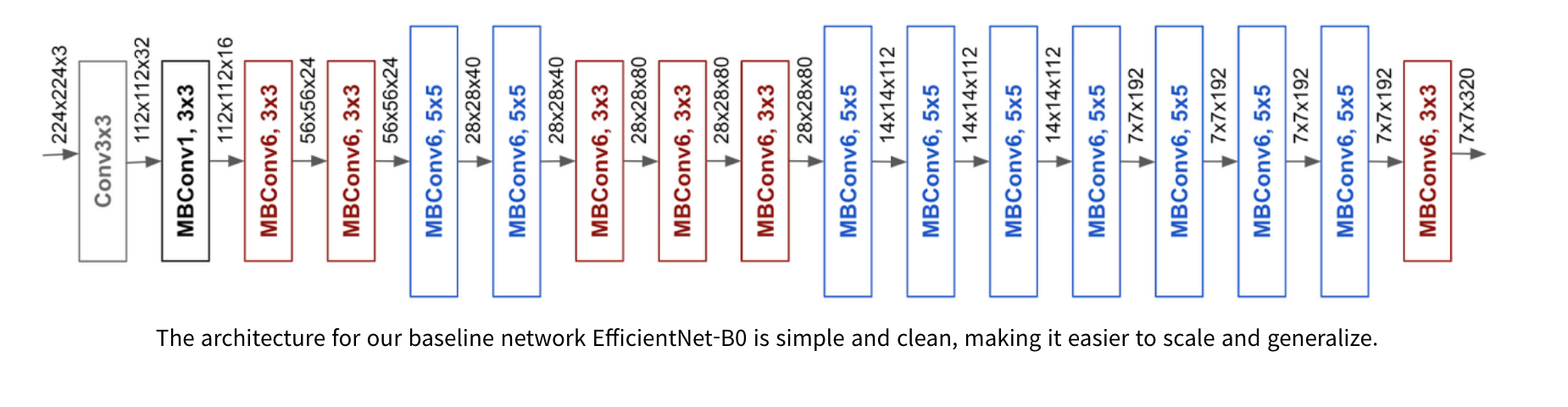
EfficientNet Architecture
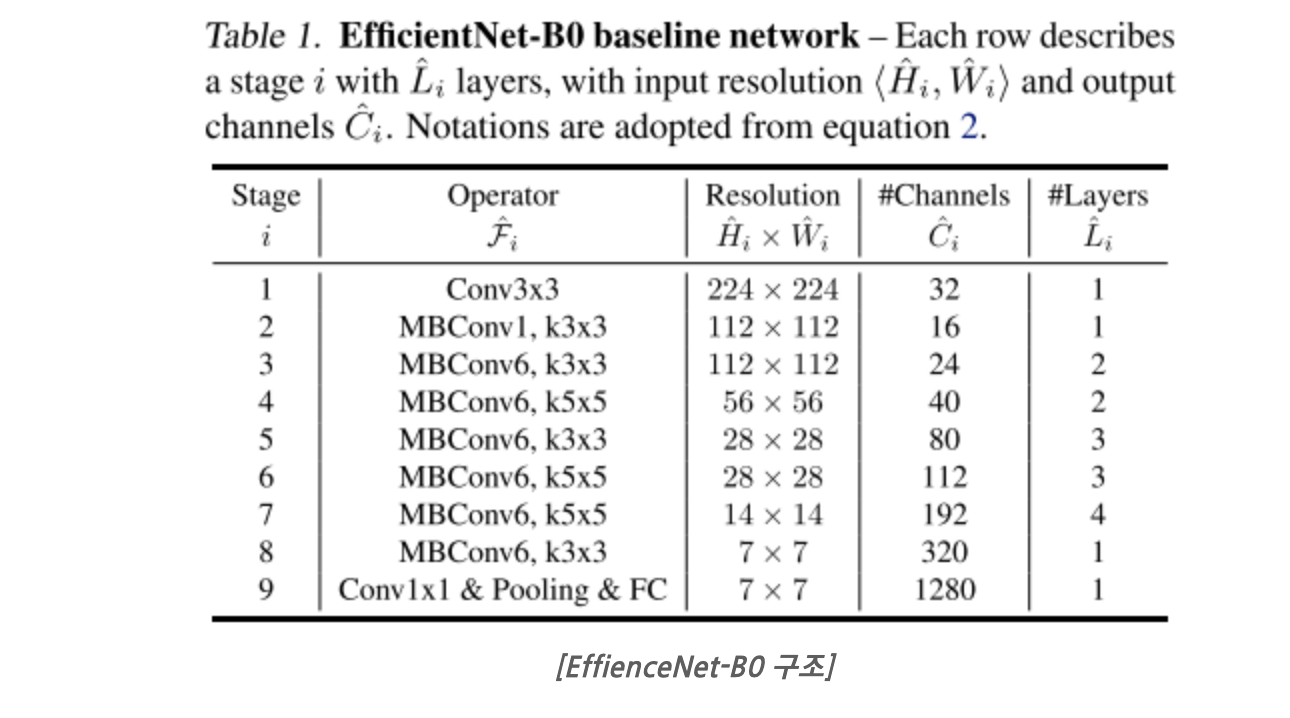
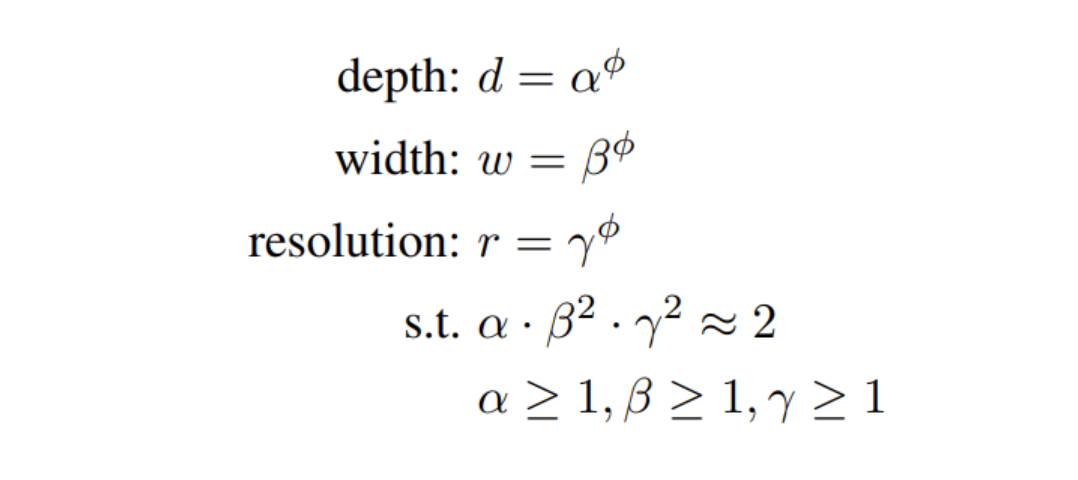
위 식을 통해 레이어의 resolution, depth, width를 각각 조정하는 것이 아니라 고정된 계수에 따라서 변하도록 하면 일정한 규칙에 따라 모델의 구조가 조절된다.?
α, β, γ는 small grid search로 결정되는 상수
ϕ는 사용자가 제어할 수 있는 factor(자원에 따라 설정하길)
Experiments
ImageNet 데이터셋에서의 성능
EfficientNet은 모델 사이즈 별로 B0~B7, B0이 제일 가벼운 모델
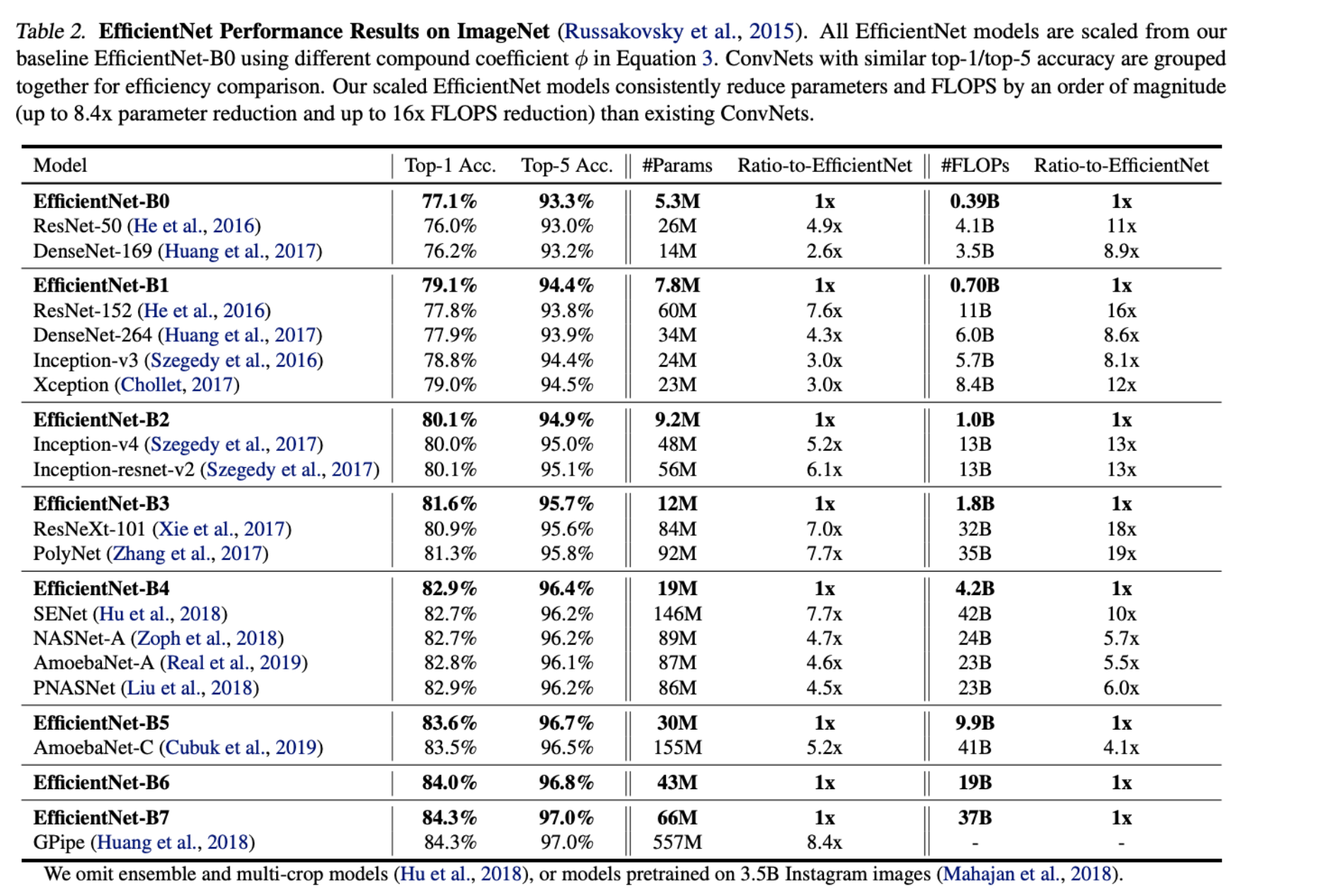
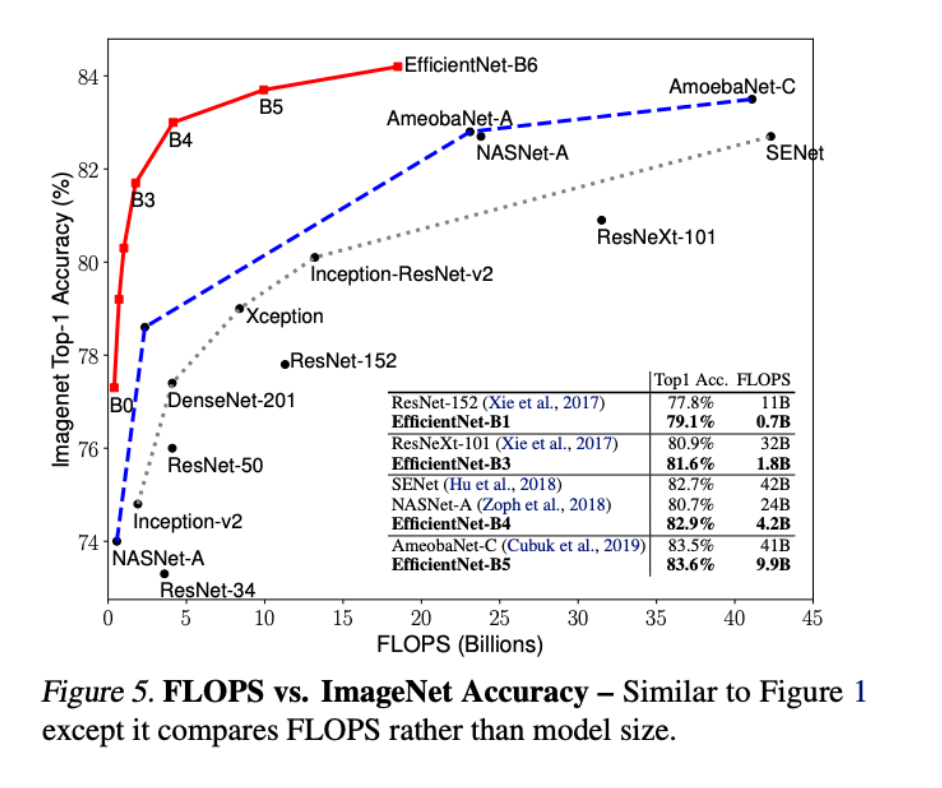
- 추론 속도 비교

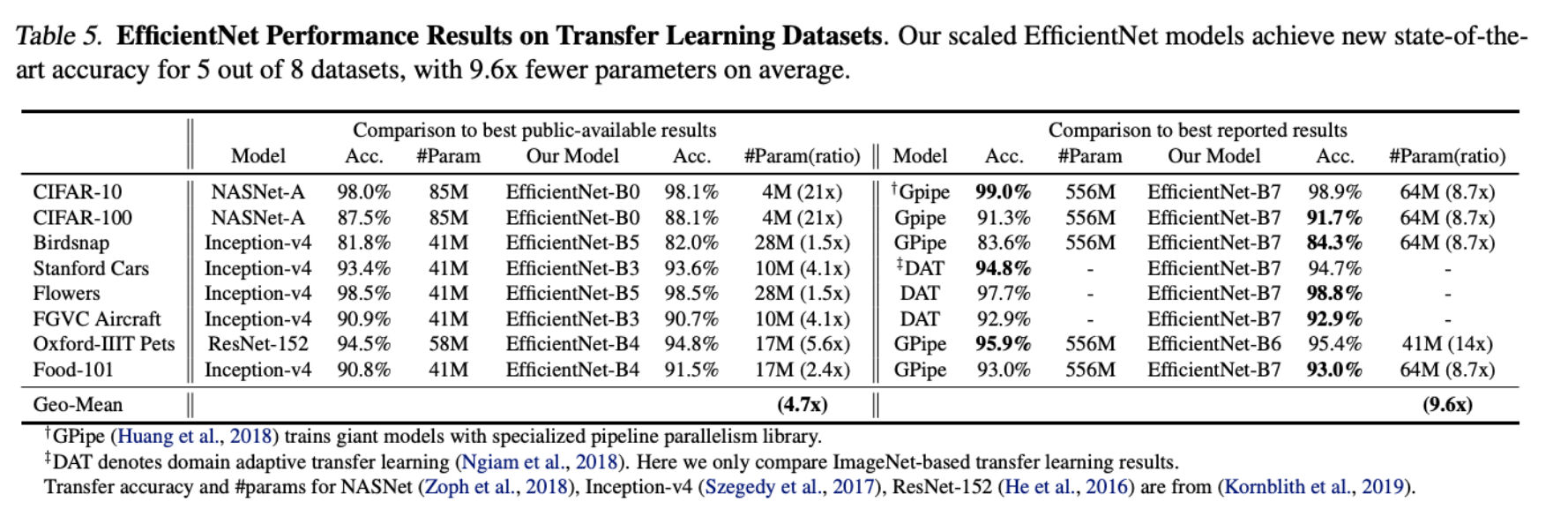
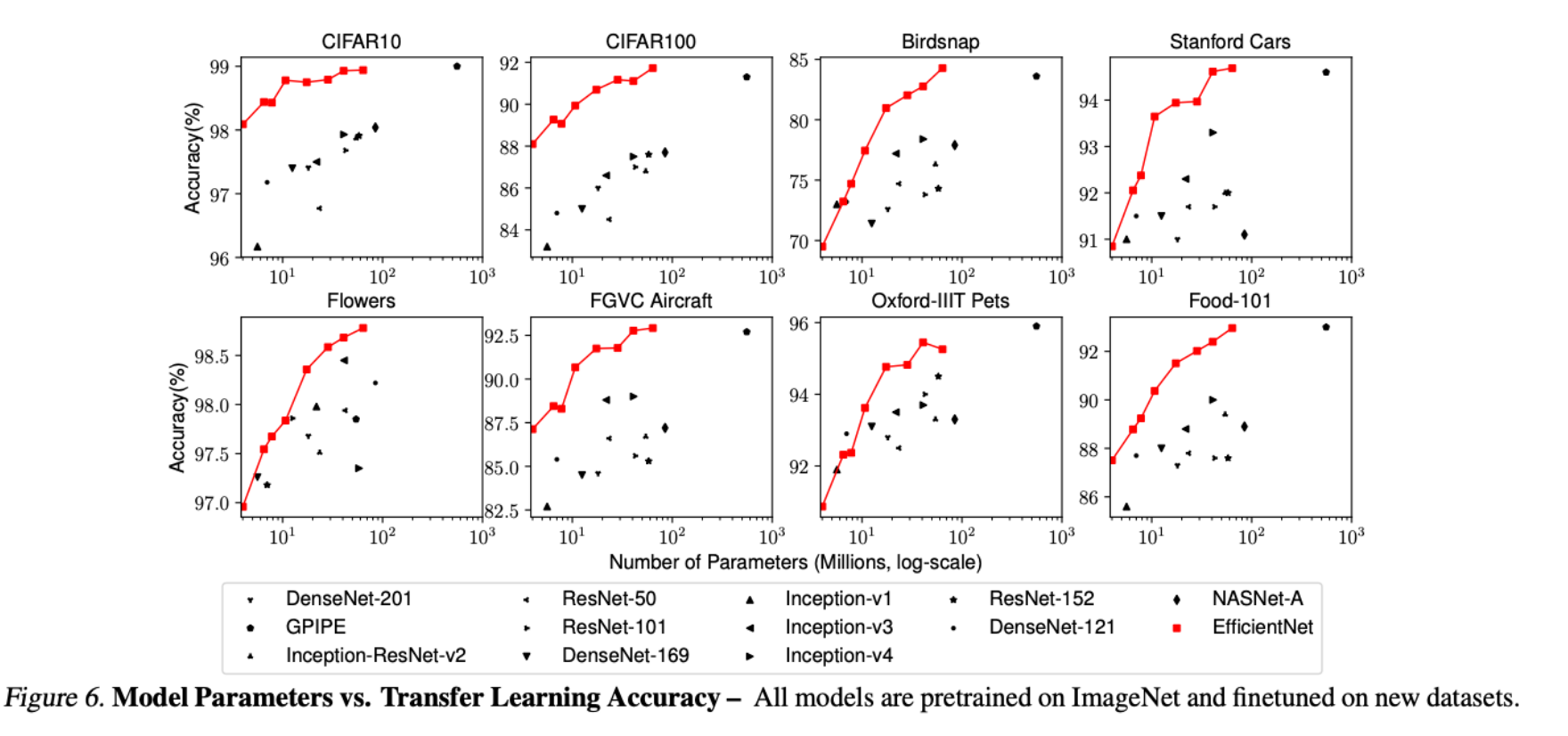
- Transfer Learning 성능
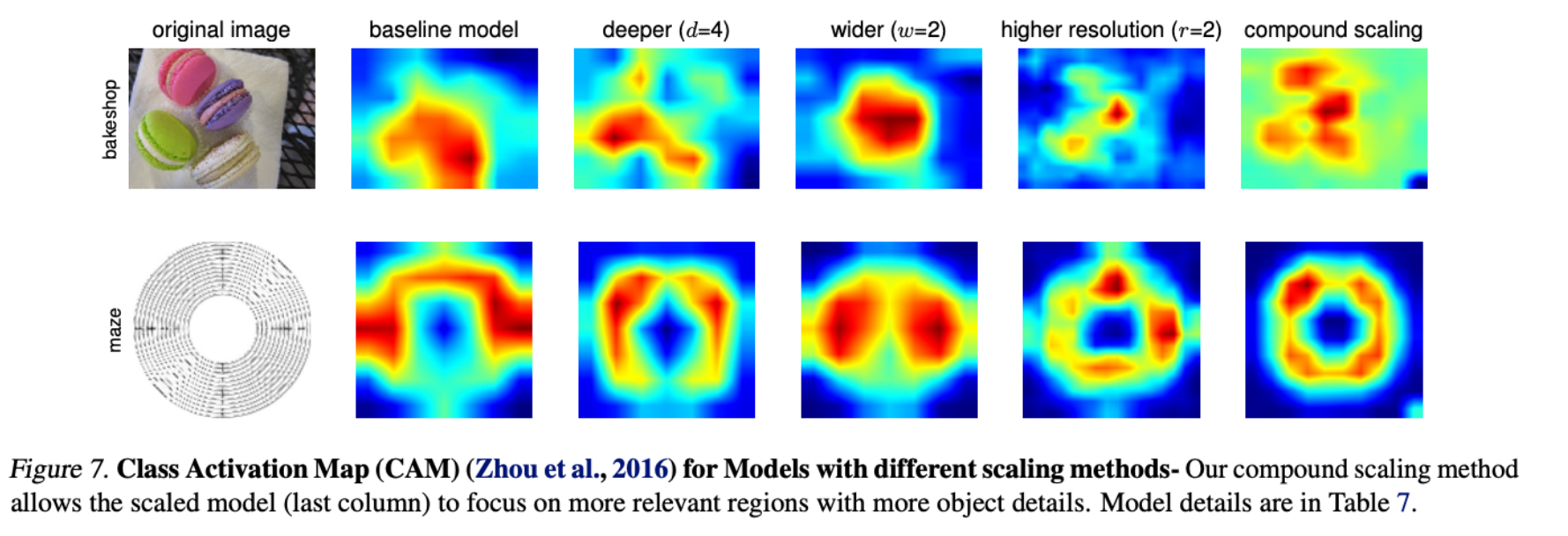
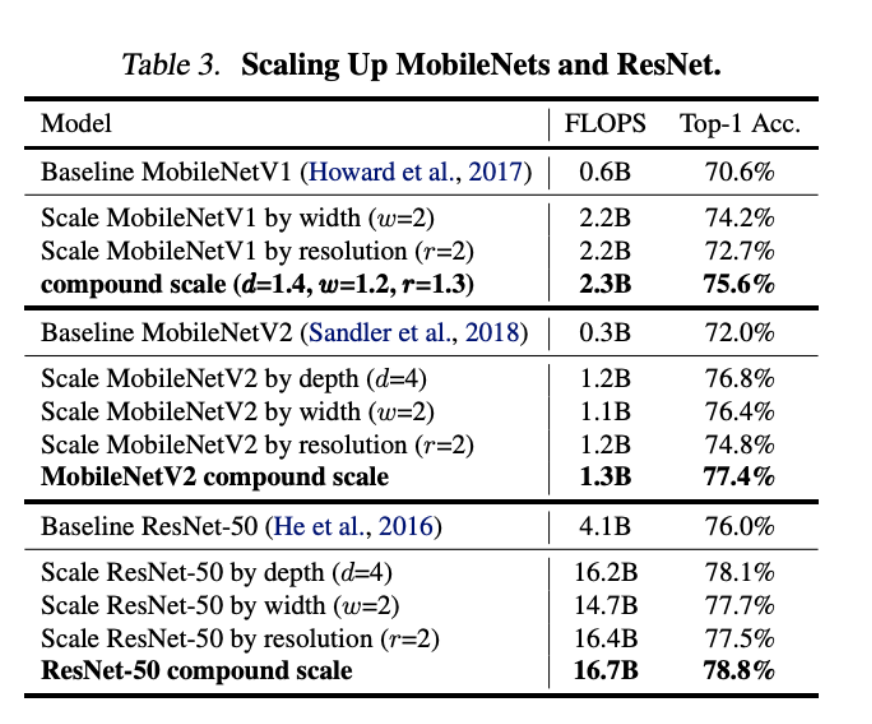
베이스라인 모델에 d, w, r을 컴파운드하니까.
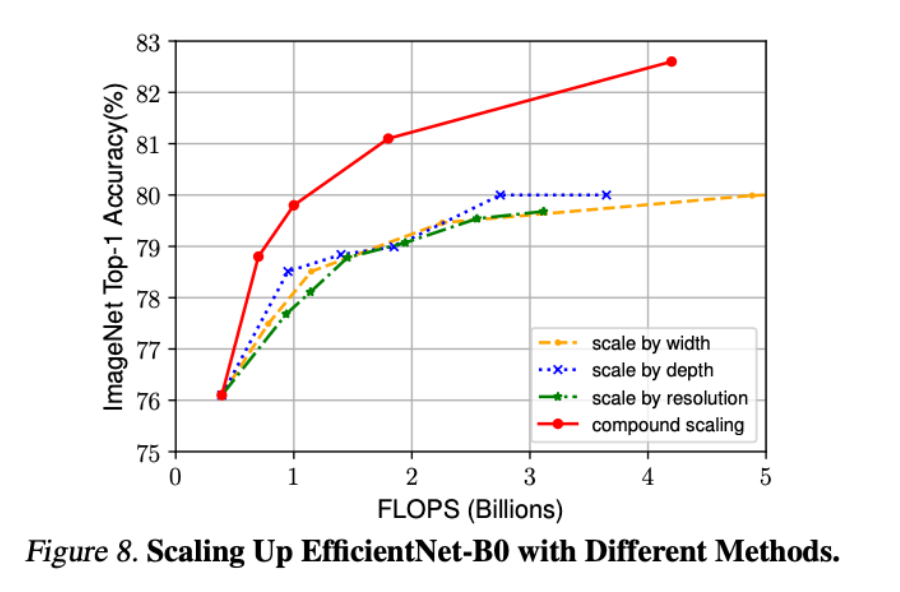
Conclusion
네트워크의 width, depth, resolution의 밸런싱에 따른 결과의 차이를 볼 수 있었다.
단순하고 매우 효과적인 compound scailng 방법은 ConvNet에서 쉽게 확장할 수 있게 했다.
