Pandas
개요
넘파이는 저수준api가 대부분이다. 판다스는 넘파이 기반으로 작성됐는데, 넘파이보다 훨씬 유연하고 편리하게 데이터 핸들링을 가능하게 해준다.
판다스는 파이썬의 리스트, 컬렉션, 넘파이 등의 내부 데이터와 csv등을 쉽게 DataFrame으로 변경해 쉽게 데이터의 가공/분석을 쉽게 만들어준다.
- Pandas 라이브러리는 numpy 기반으로 만들어지느 새로운 패키지로써 DataFrame이라는 효율적인 자료구조를 제공한다.
- 세 가지 기본 자료구로 나뉜다.
- Series (유연한 1차원 배열)

- DataFrame (유연한 행과 열의 2차원 배열) 핵심!
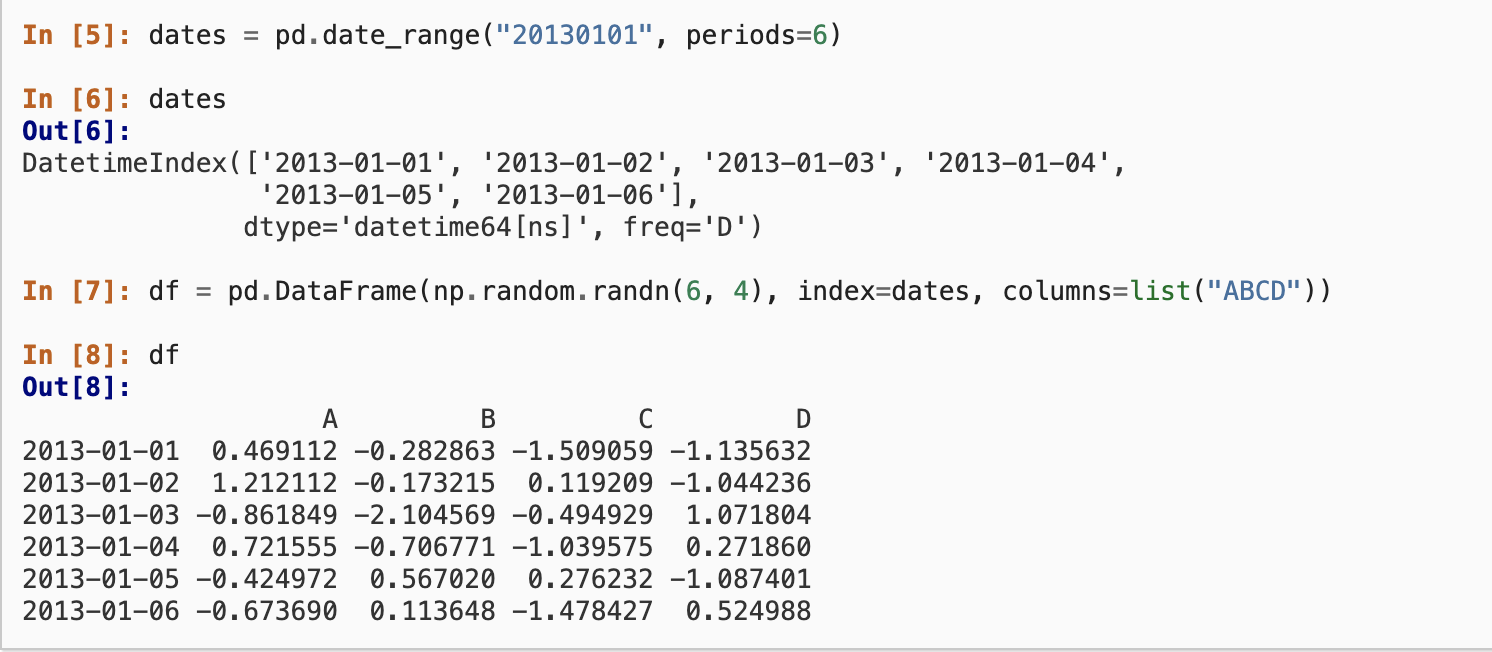
- Index
*Numpy Example

- 배열에서 요소 찾기
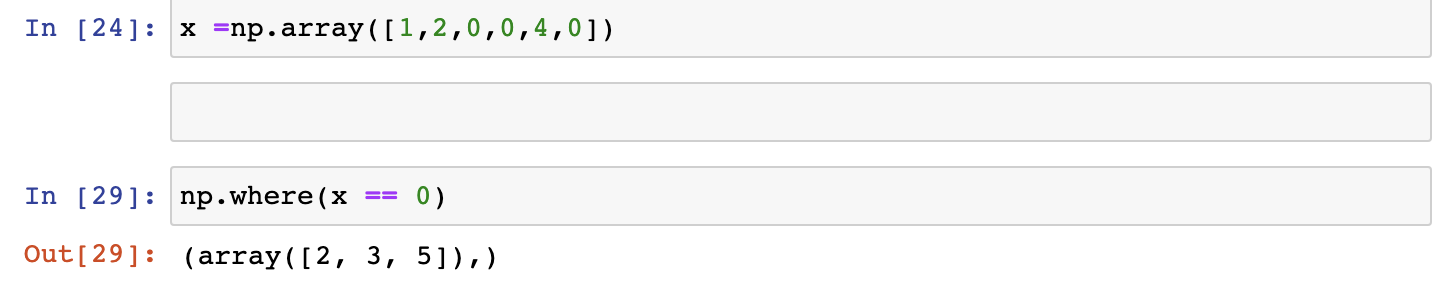
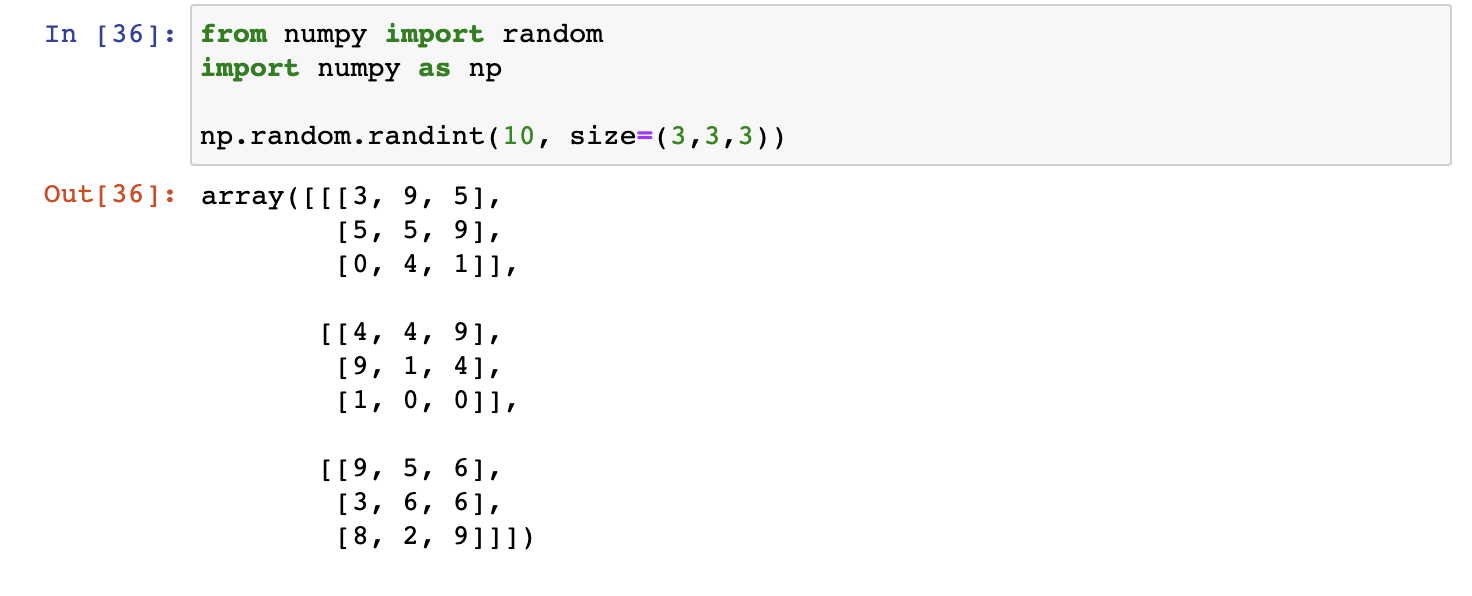
- Create a 3x3x3 array with random values
- create a random vector of size 30 and find the mean value

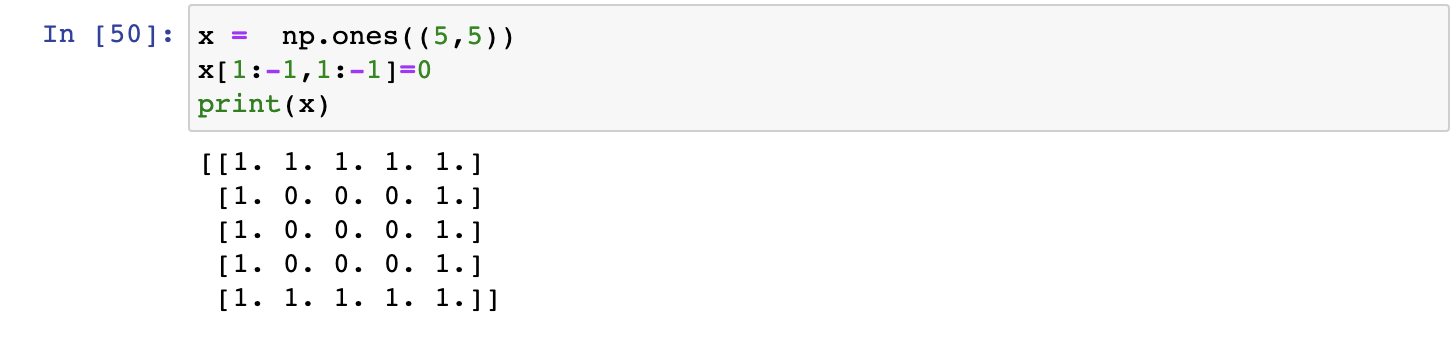
- Create a 2nd array with 1 on the border and 0 inside
- apply()
복잡한 로직을 처리하면서 새로운 변수를 만들 때
데이터를 조건별로 다르게 처리하고 싶을 때 apply와 lambda를 사용하면 독립적 case로 나눌 수 있다.
DataFrame 데이터 삭제
DataFrame에서 데이터 삭제는 drop()
ex)
a_drop_df = a_df.drop('someColumn', axis = 1)
(inplac=True로 설정하면 반환 값이 None이 됩니다.)
데이터 불러오기, 쓰기
pandas의 read_csv()를 사용하면 된다.
pandas.read_csv('file_path')
Innovation is mine