numpy summary
파이썬에서 대규모 다차원 배열을 다룰 수 있게 도와주는 라이브러리이다.
데이터의 대부분은 숫자 배열로 볼 수 있다.
list대신 numpy를 사용하는 이유는 더 빠른 연산을 지원하고 메모리를 효율적으로 사용하기 때문이다.
-
선형대수 라이브러리
-
numpy 배열은 파이썬 list와 비슷하지만 배열의 규모가 커질수록 데이터 저장, 처리에 훨씬 효율적이다.
-
numpy는 데이터 배열을 사용하여 최적화된 연산을 위한 쉽고 유연한 인터페이스를 제공한다.
-
numpy배열은 백터화 연산을 사용하는게 핵심인데, 일반적으로 numpy의 유니버셜(ufucns) 함수를 통해 구현된다.
-
UFuncs 활용
- 배열 산술 연산
- 절대값 함수
- 삼각함수
- 지수와 로그
- 쌍곡선 삼각 함수, 비트 연산,비교 연산자
- 출력 지정
- 집계
- 외적
About Numpy
ndarray를 편리하게 생성하는 arange, zeros, ones
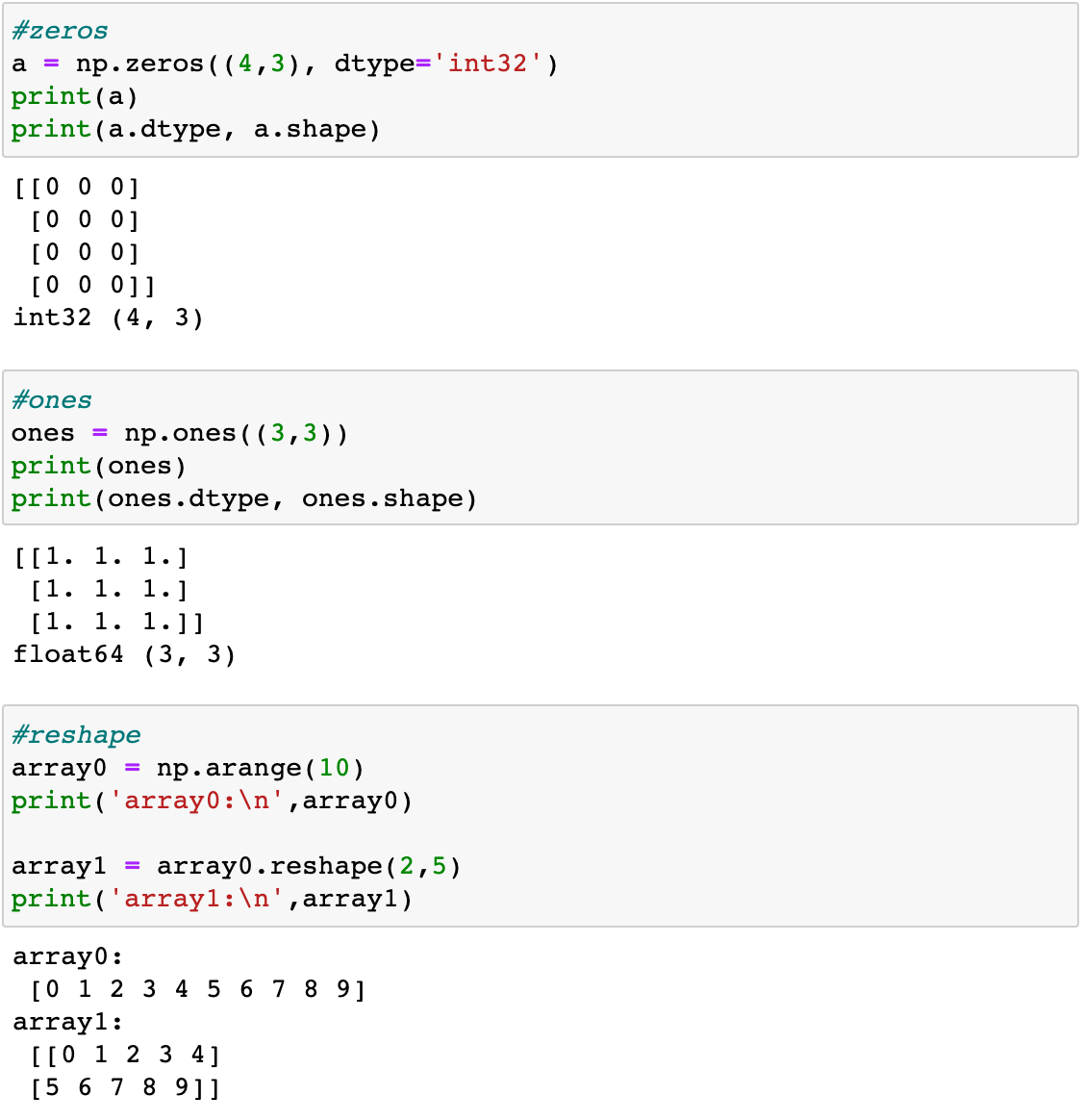
ndarray의 차원과 크기를 변경하는 reshape()
```
array1 = np.arange(10)
print(array1)
=>[0 1 2 3 4 5 6 7 8 9]
array2 = np.reshape(2,5)
print(array2)
=> [[0 1 2 3 4 ]
[5 6 7 8 9 ]]
array3 = np.reshape(5,2)
print(array3)
=> [[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]
```인덱싱
-
데이터 일부만 가져오기
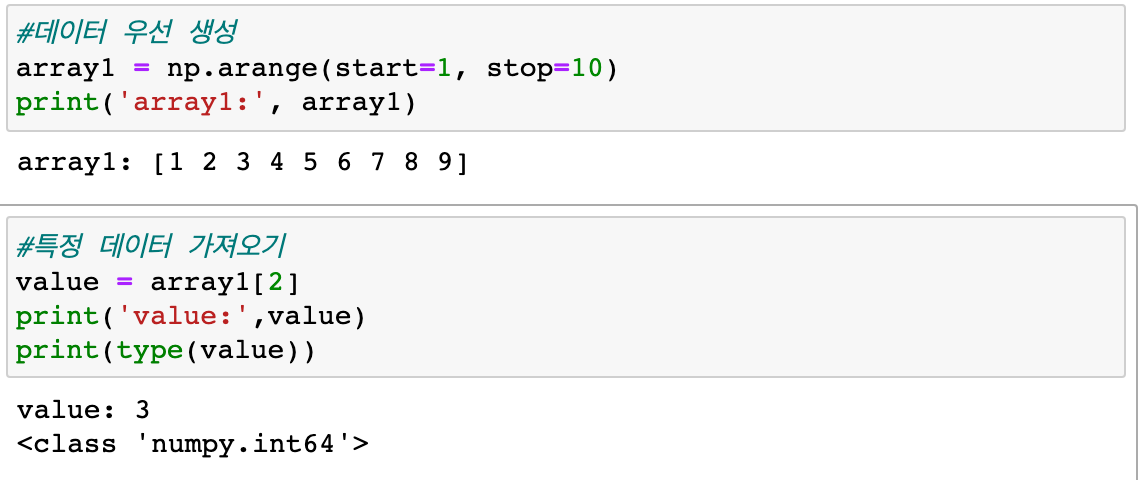
-
다차원 ndarray에서 단일 값 추출하기

슬라이싱
-
2차원 ndarray에서 슬라이싱
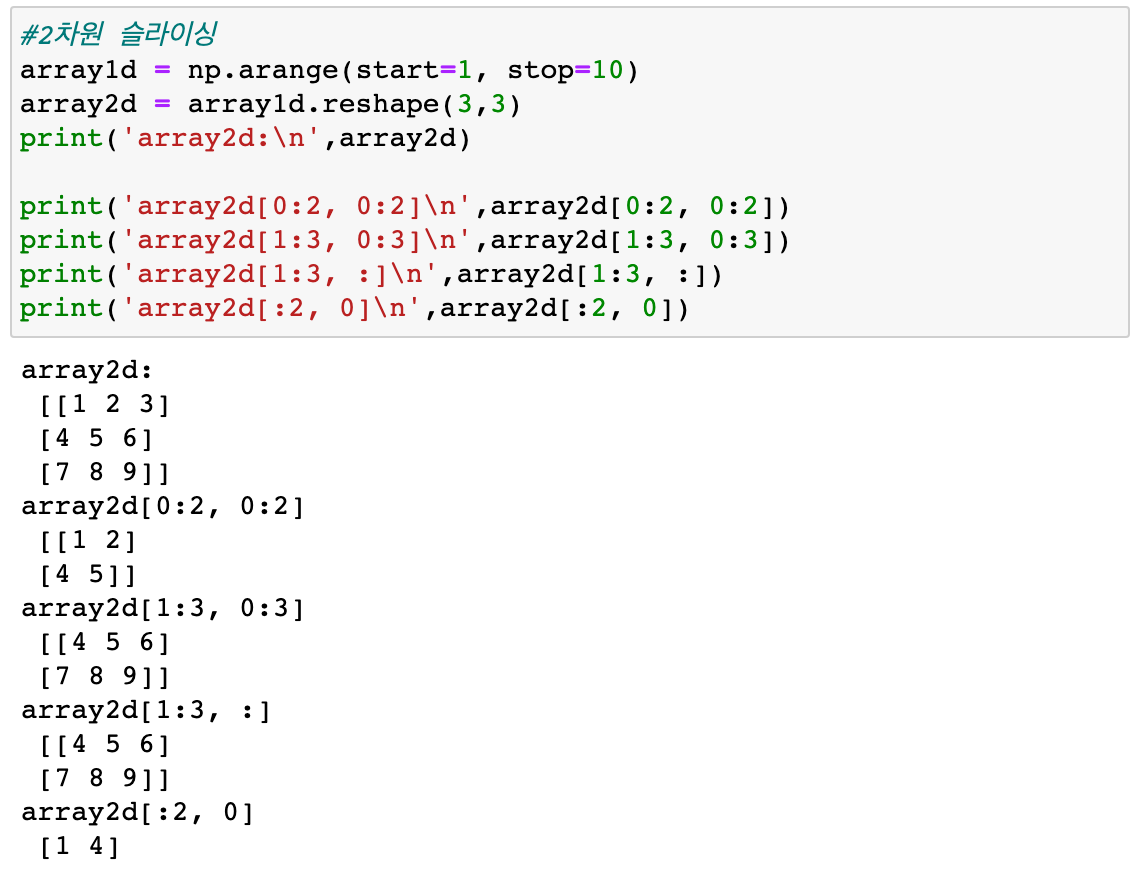
-
불린 인덱싱
조건 필터링과 검색을 동시에 할 수 있다.


그 값의 참거짓을 물을 수 있다.
정렬
- np.sort()와 ndarray.sort(), argsort()가 있다.

*axis 출력값이 잘못나옴.
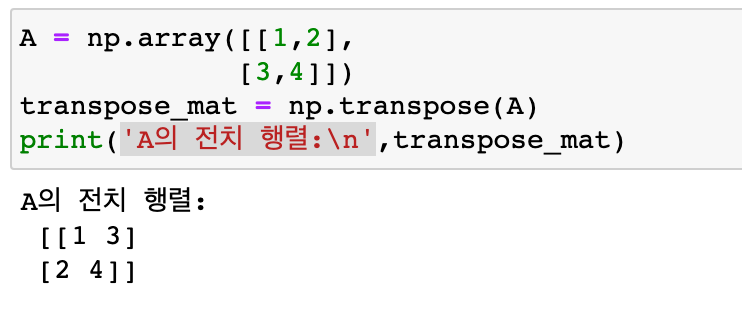
행렬곱과 전치행렬
-
행렬곱(행렬 내적)
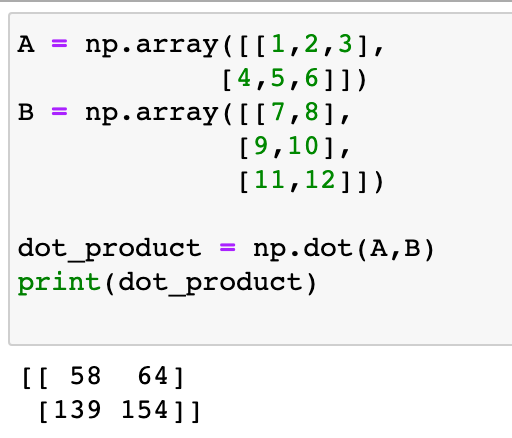
-
전치 행렬
axis 기준으로 연산
a = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[1, 3, 5, 7]])
print(a.sum(axis = 0)
# array([7, 11, 15, 19])
print(a.sum(axis = 1)
# array([10, 26, 16])
print(a.max(axis = 1)) # 각 행에서의 최대값
# array([4, 8, 7])
2차원 ndarray 슬라이싱
array1d = np.arange(start=1, stop=10)
array2d = array1d.reshape(3, 3)
array2d[0:2, 0:2]
=> [[1 2]
[4 5]]
array2d[1:3, 0:3]
=> [[4 5 6]
[7 8 9]]
array2d[:2, 0]
=> [1 4]

Innovation is mine