RNN&Attention
시계열 분석을 위한 RNN과 Attention
ML기반 시계열 분석 방법론
- SVM
- Random forest
- Boosting
- Gausian process
- Hidden Markov model(HMM)
DL기반 시계열 분석 방법론
- RNN
- LSTM
- GRU
- Seq2Seq
- Seq2Seq with attention
- Transformer
- GPT-1, BERT, GPT-3
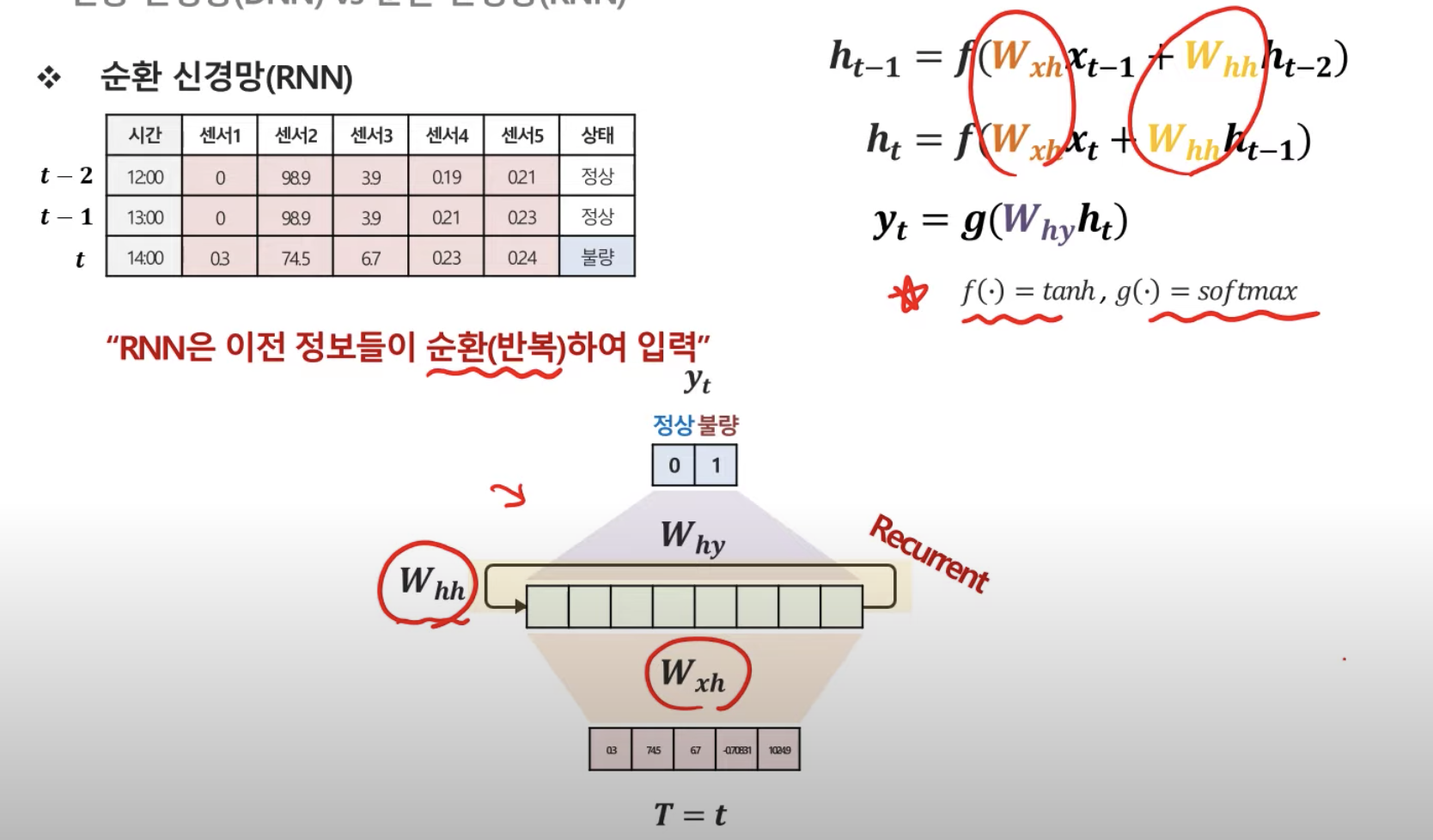
RNN (순환신경망)
DNN은 시점t에서의 설명변수를 가지고 해당 시점의 반응변수 y를 예측한다.
RNN은 시점t의 반응변수 y를 구하기 위해 이전 타임의 설명변수와 은닉층을 사용한다.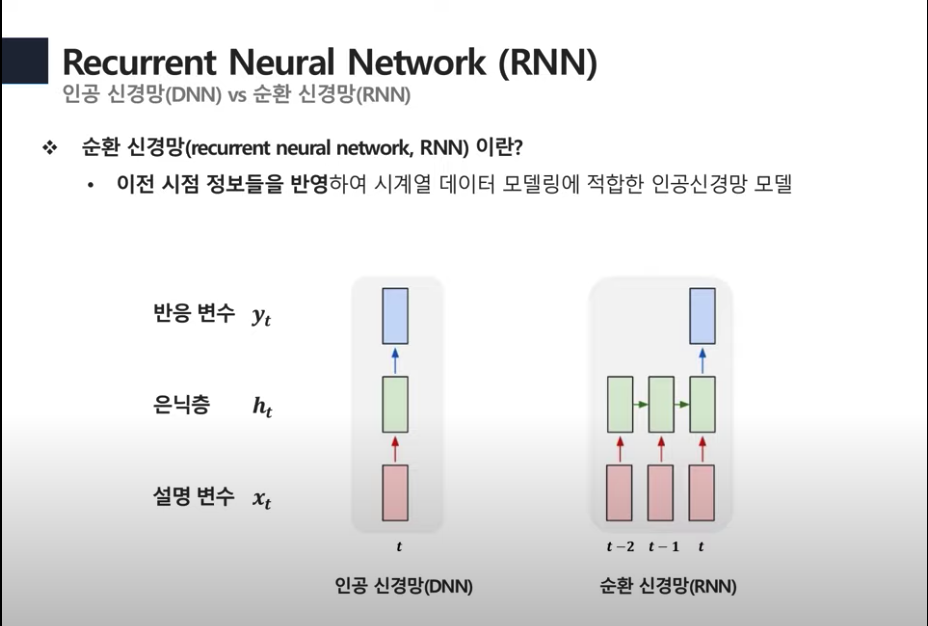
DNN은 한 시점에 대한 정보만을 가지고 y를 예측한다.
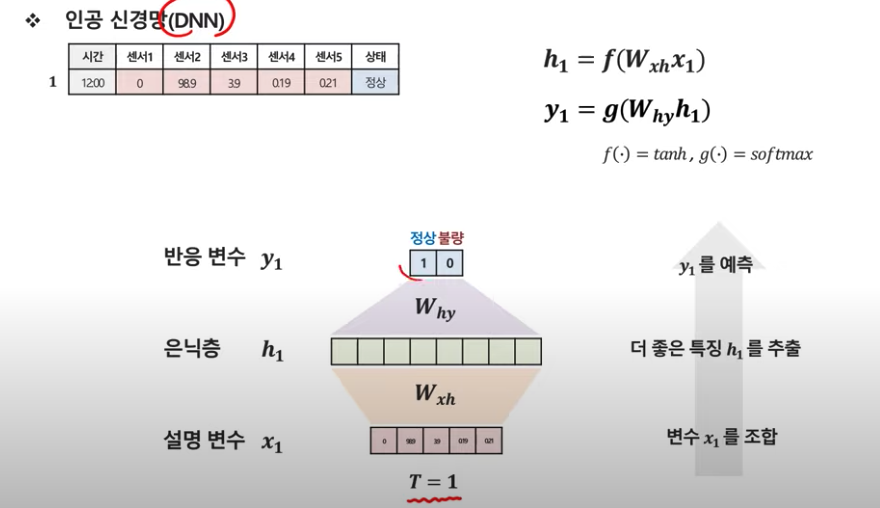
이전 시점 정보를 반영해서 더 정확한 예측을 하려면?
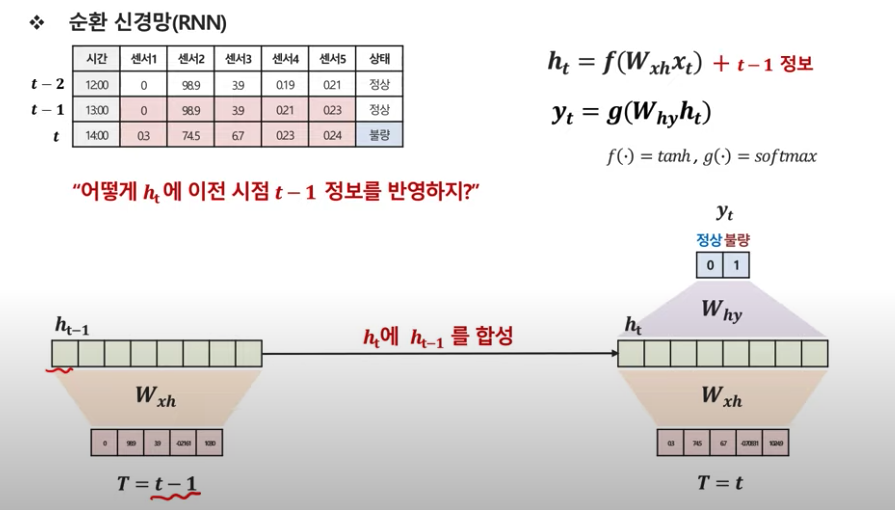
이렇게 t시점의 hidden vector와 previous hidden vector를 합성한다.
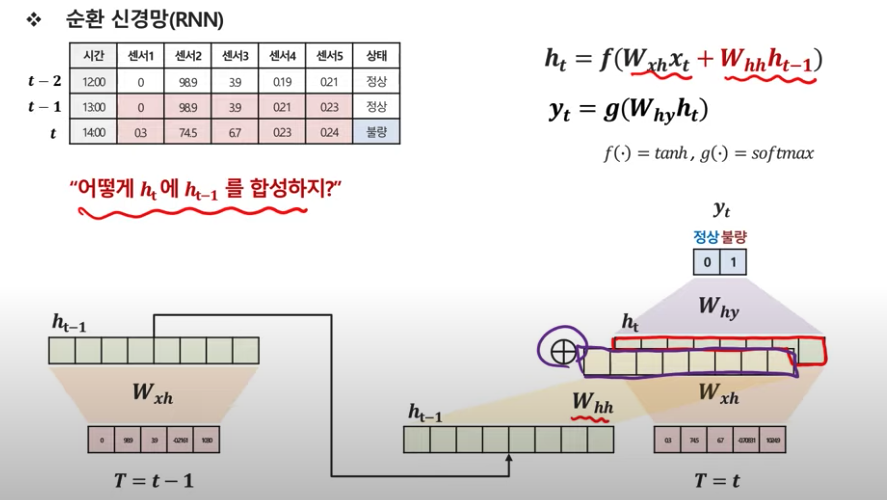
t-2 시점까지 좀 더 넓게 보면.
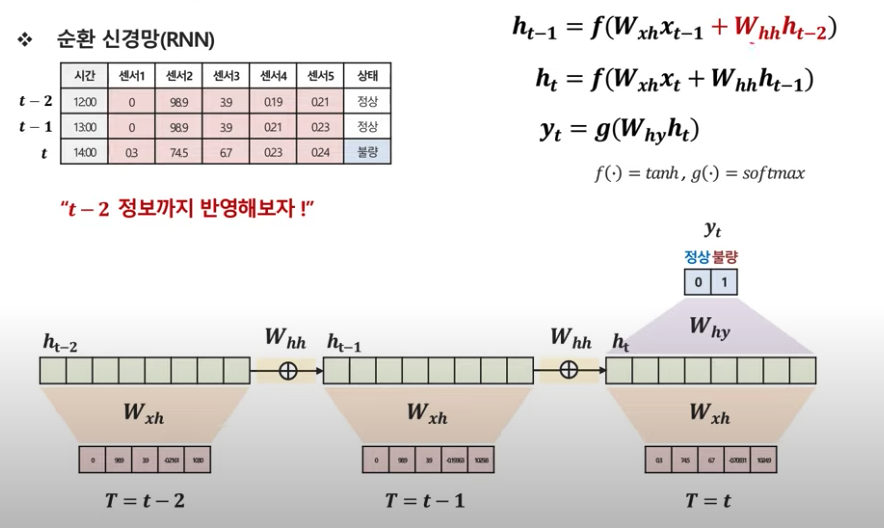
위의 펼쳐진 그림을 하나로 압축한다.
-> 효율성(이전 정보 활용)을 위해 각 시점마다 동일한 parameter W를 사용하기 때문에 마치 순환하는 것처럼 표현된다.
Q. 하지만 이전 정보가 많아진다?
RNN구조의 종류는 다음과 같다.
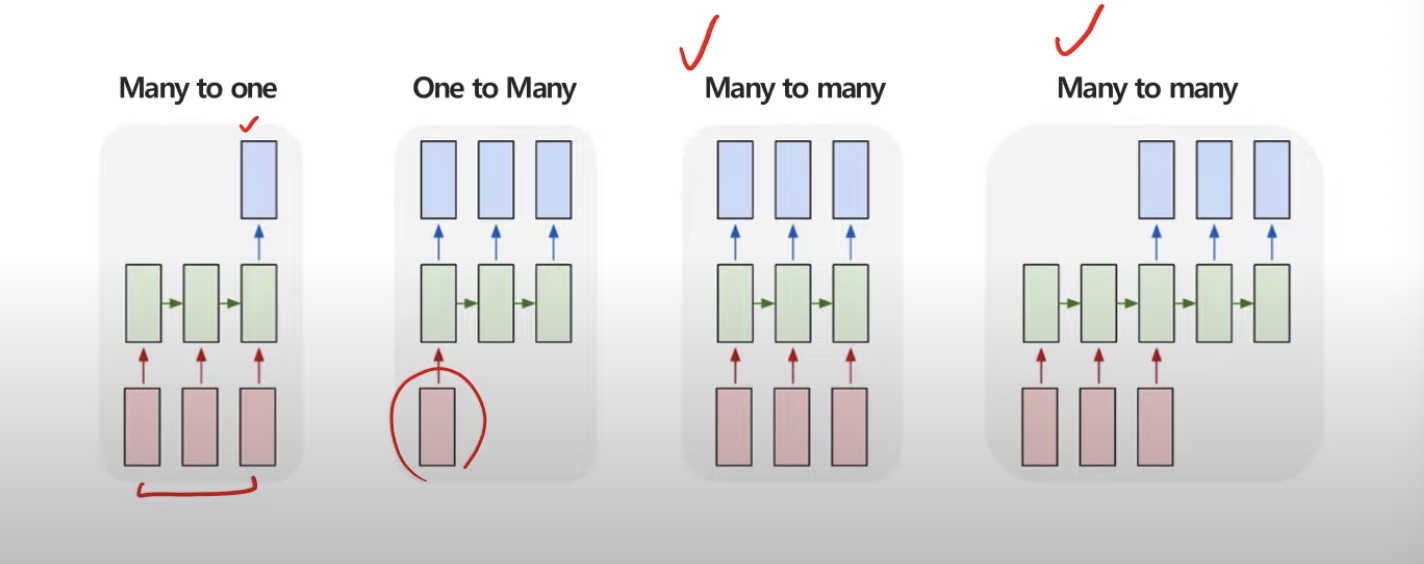
Many to Many는 사용자 설정에 따라 두 가지 종류의 출력을 내보낸다.
Seq2Seq(2014년)
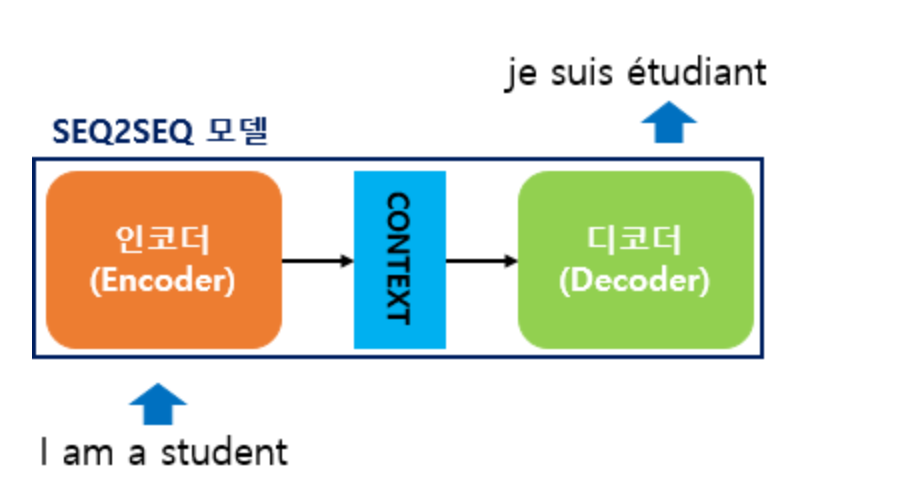
인코더의 정보를 Context Vector C에 저장하여 디코더 출력에 활용한다.
- 한계점이 존재
context vector에 의존하게 된다. -> bottleNeck 현상 유발-
대안?
Attention
Attention
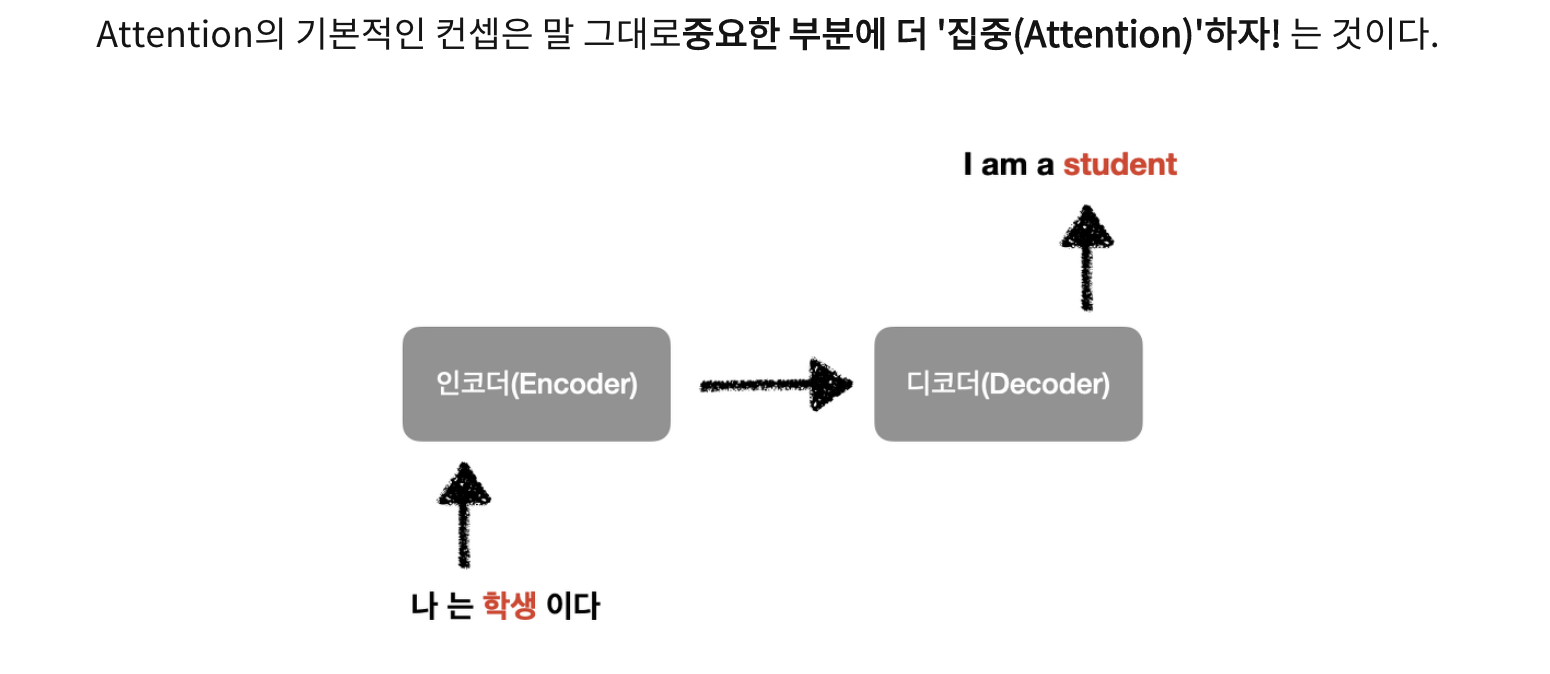
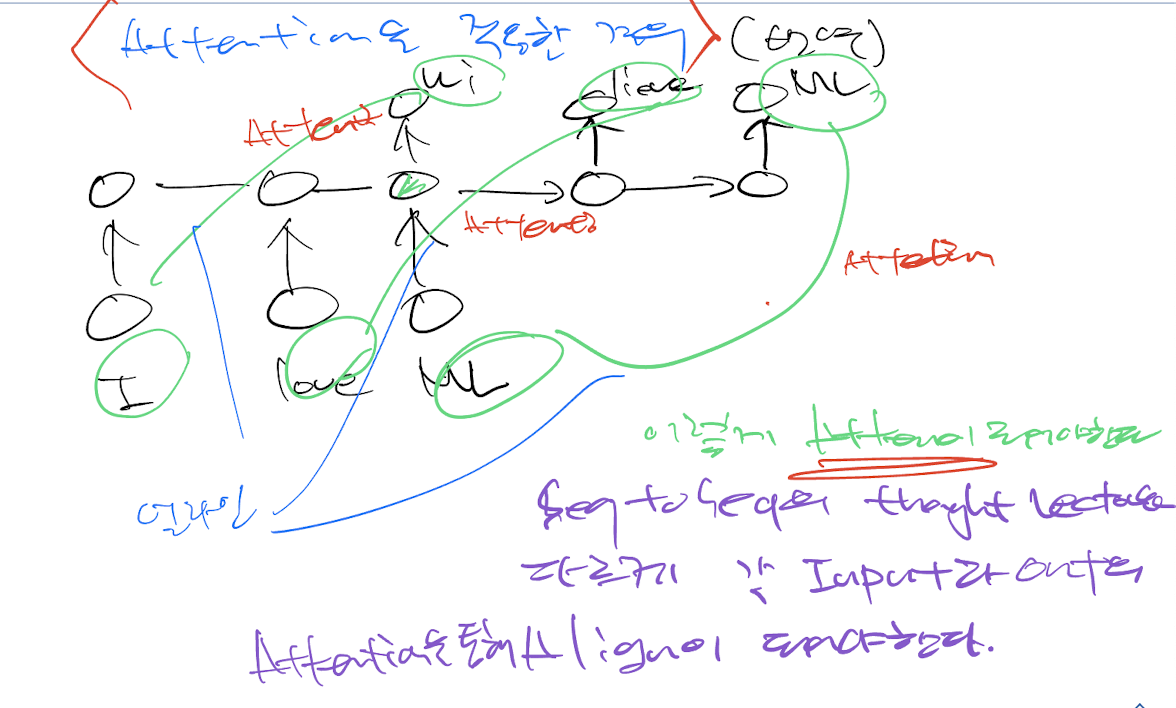
그렇다면 어떻게 중요도를 정의할까?
중요도 = 유사도
간단한 방법으로는.
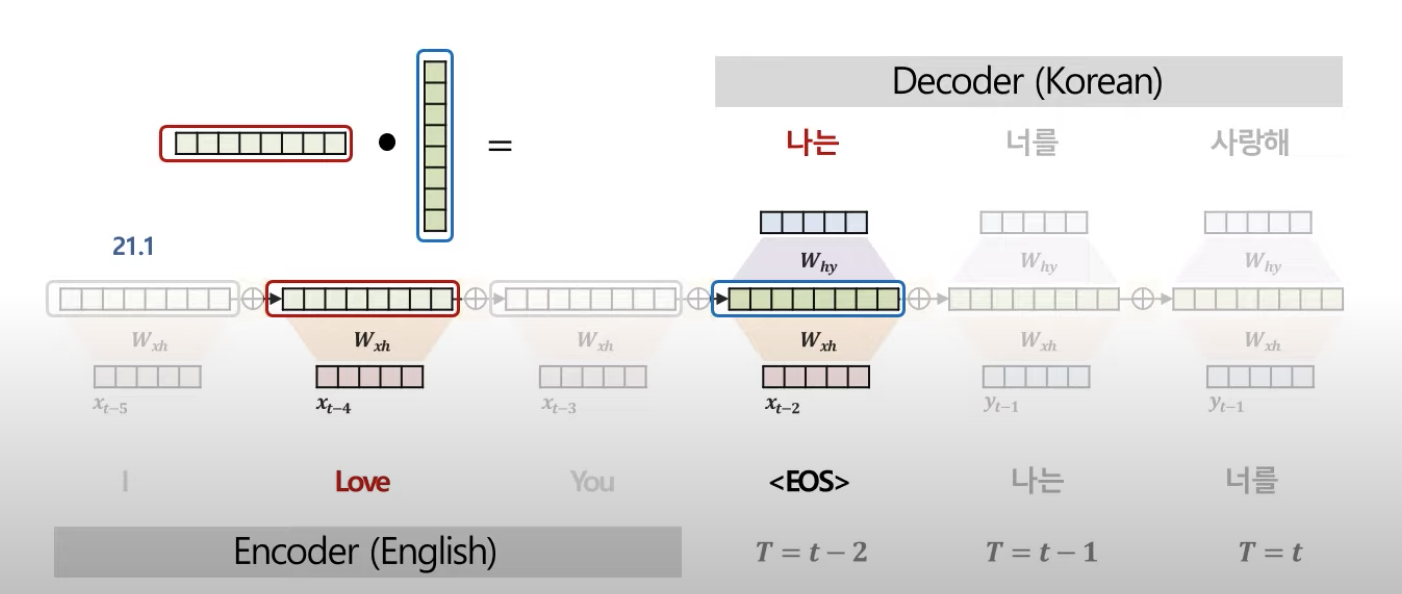
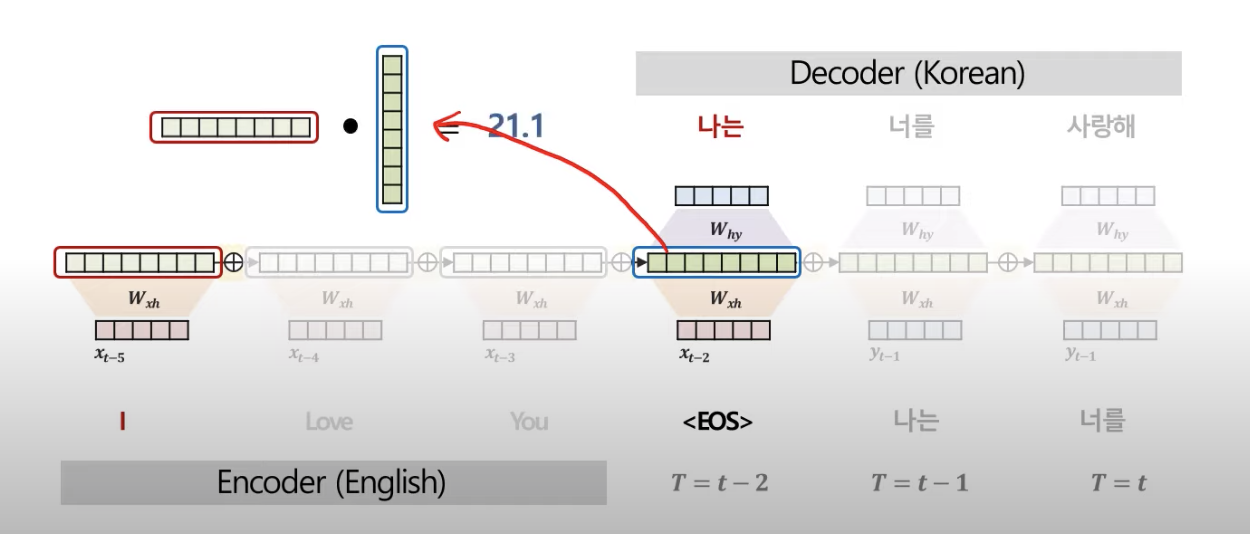
인코더 한 단어의 hidden vector와 디코더 한 단어의 hidden vector를 내적
예시)
'I'와 "나는"
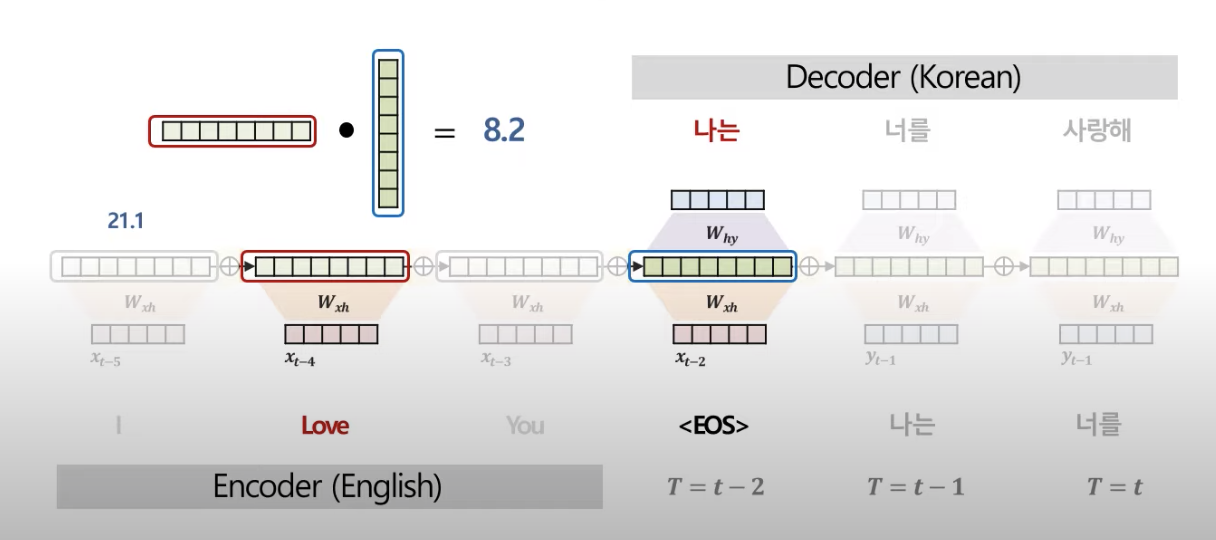
"Love"와 "나는"
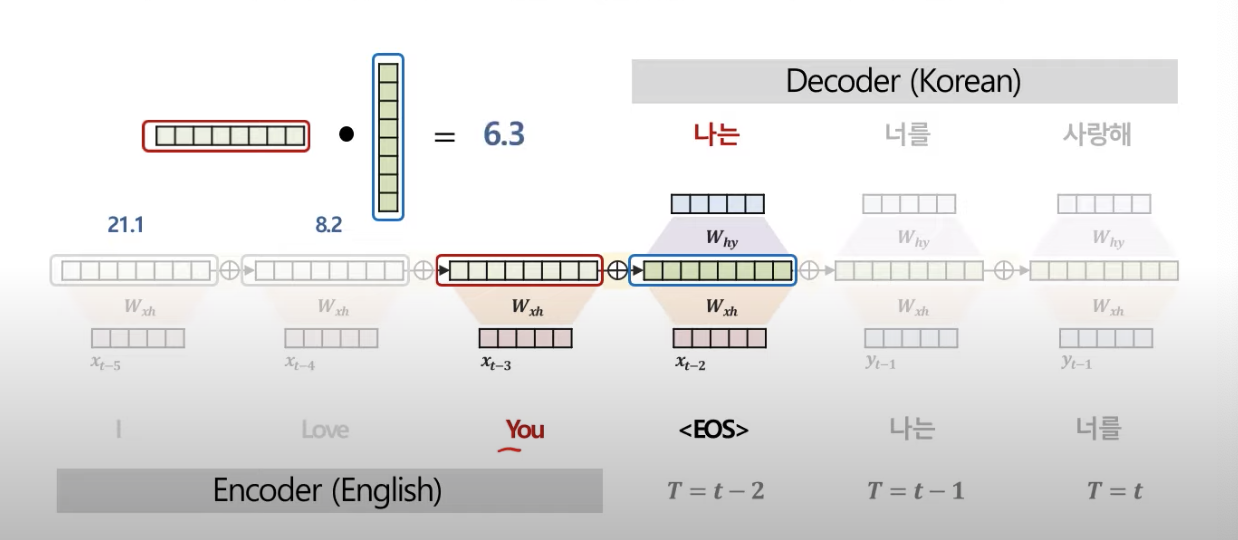
"You"와 "나는"
그래서 나온 유사도는
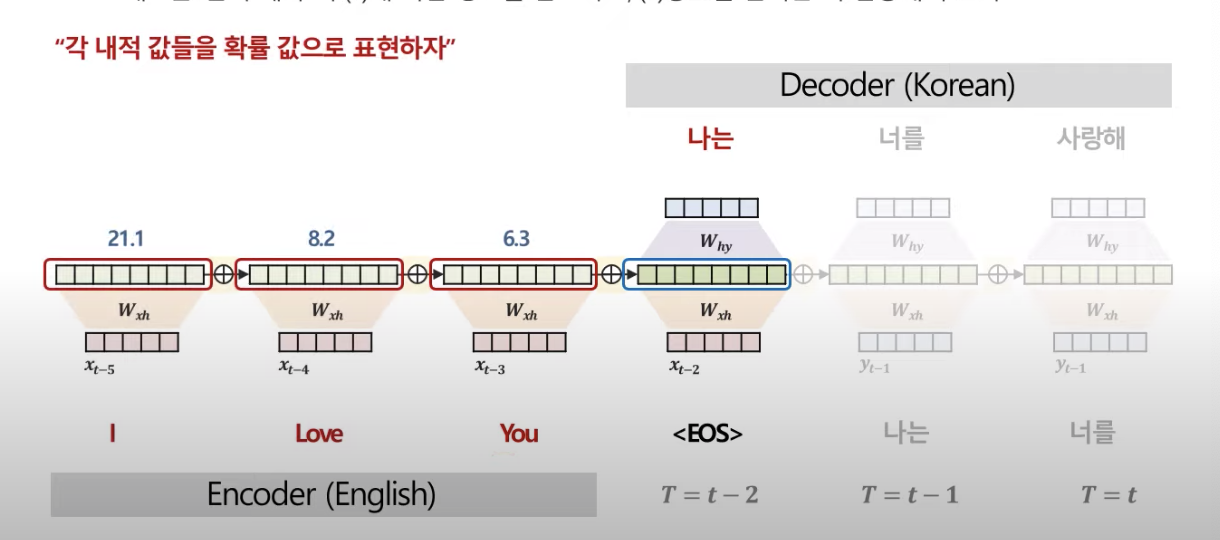
이것을 softmax를 통해 확률값으로 변환
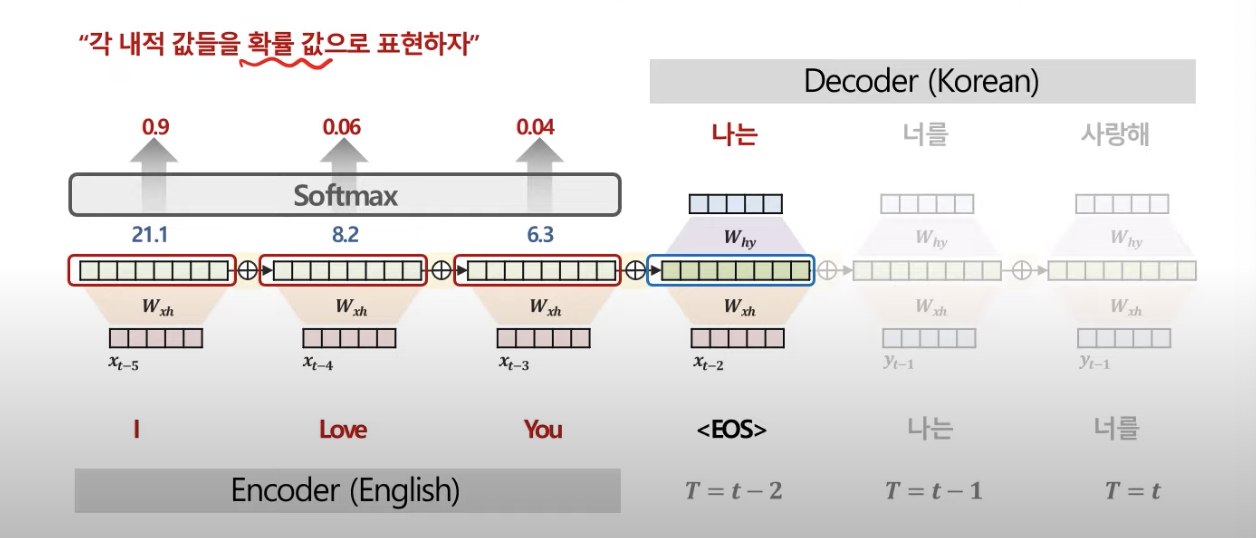
유사도가 21.1이 90%의 확률을 가진 값이 된다.
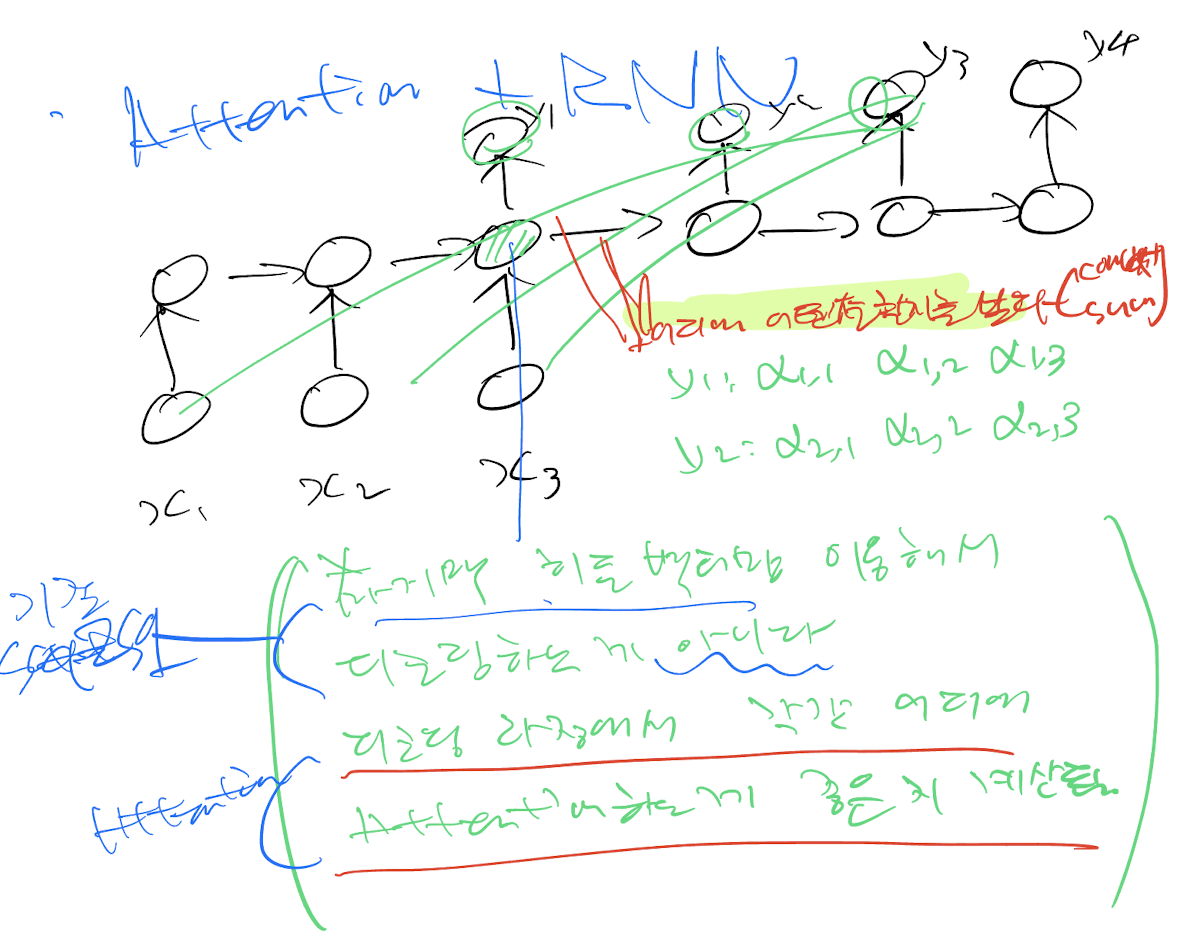
그렇게 만들어진 Decoder 각 단어에 매칭되는 Context vector를 만들고 이를 가지고 Decoder 각 위치에 들어갈 단어를 예측하여 출력하게 된다.

정리하자면,
Attention은 관측시점 별로 중요도를 따져 결과값을 도출한다.
센서를 예시로 보면,
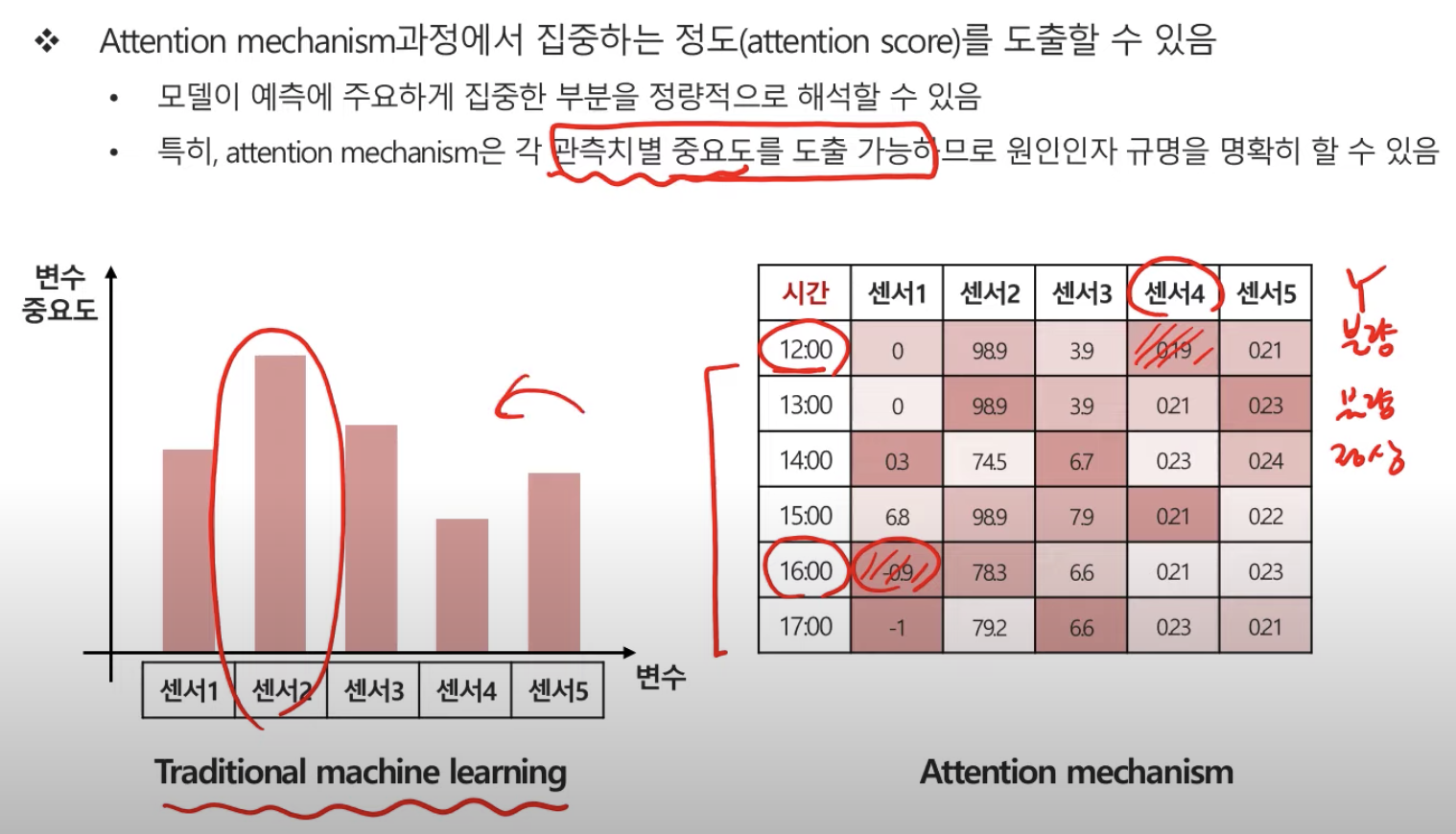
Attention은 정확도를 높이기 위해 적용되었고, 기존 딥러닝 모델에 있어 예측은 되지만 해석이 안되던 단점을 해결한 기법 중 하나이다. 즉, 설명력을 가지게 되었다.
Attention(2015년)부터 Transformer, GPT-1, BERT, GPT-3는 입력 시퀀스 전체에서 정보를 추측하는 방향으로 발전하였다.
