Intro
우선순위 지정은 중요하다.
- 사용자는 게으르다.
- 사용자는 무지하다.
똑똑한 검색 엔진이라면 다음과 같은 요소를 고려해야 한다.
-
user history
: 유저의 과거 이력을 기록하고 Ranking에 반영한다. -
user's geographical location
: 사용자의 위치를 기록하고 적절한 언어로 작성된 검색 결과의 점수를 높인다. -
temporal changes in information
-
all possible context clues
: 쿼리에 더 많은 맥락을 제공하기 위한 신호를 찾자.
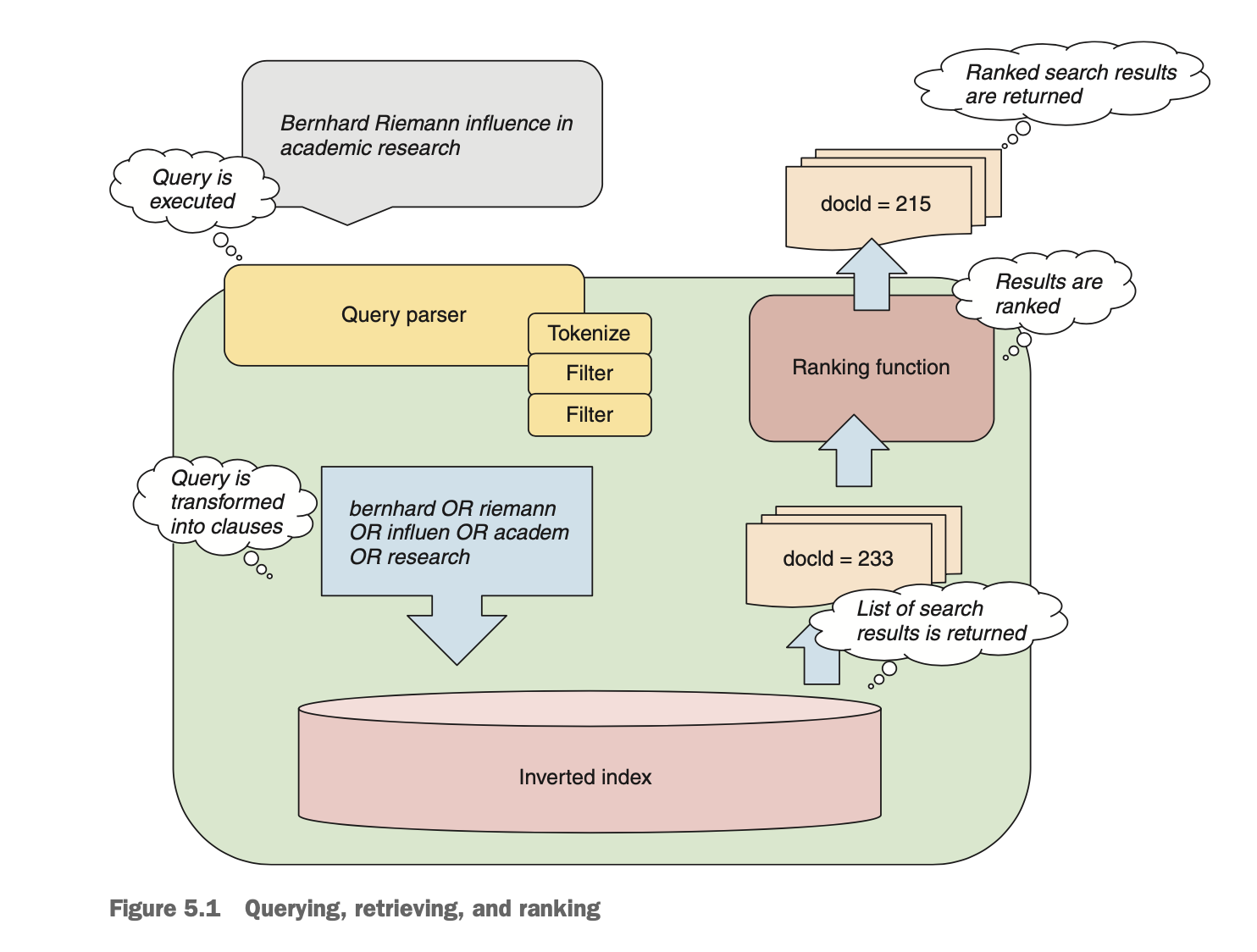
검색모델
쿼리와 색인화된 용어가 정확히 일치하지 않아도 특정 쿼리와 관련있는 문서를 반환해야 한다. 방법 중에 '동의어 확장'과 '대안 쿼리 확장'의 케이스가 있다.
- synonym expansion case
: 'hello'를 입력하든 'hi'를 입력하든 간에 말하는 의미가 동일함. - alternative query expansion case
: 'latest trends'을 입력하면 철자는 다르지만 원본과 비슷한 의미를 지닌 대안 쿼리가 표시된다.
의미론적 이해 능력이 뛰어난 검색엔진을 만들기는 어렵다.
하지만 여러 방법을 통해 이 능력을 향상시킬 수 있다.
TF-IDF&Vector space model
순위지정 함수의 기본 목적은 쿼리 문서 쌍에 점수를 할당하는 것이다. 이러한 검색 모델을 statistical models for information retrieval이라고 한다.
- term frequency:
단어가 얼마나 자주 발생하는지를 나타내는 척도 - document frequency:
모든 색인화된 문서 내에서 단어의 빈도
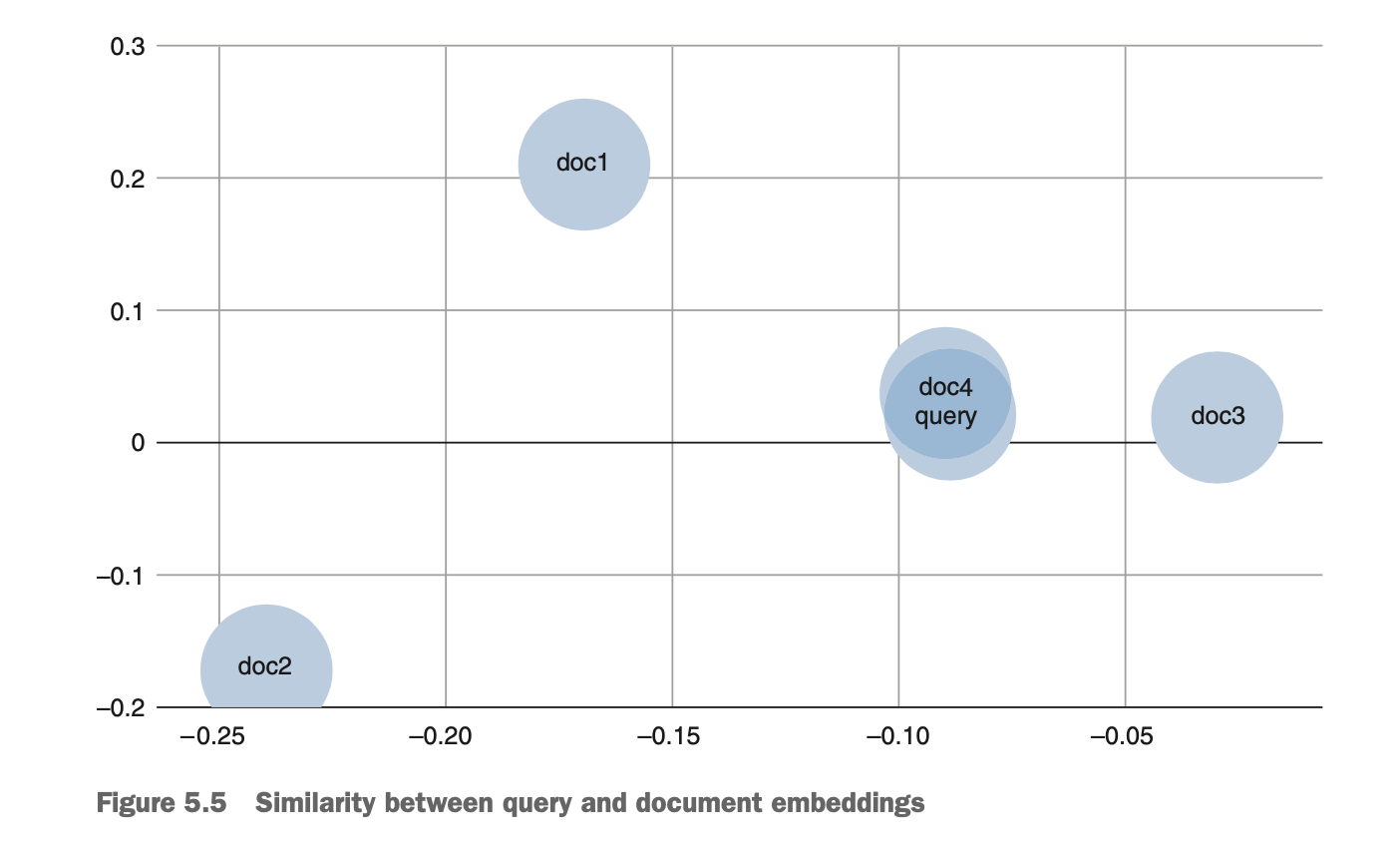
Cosine similarity
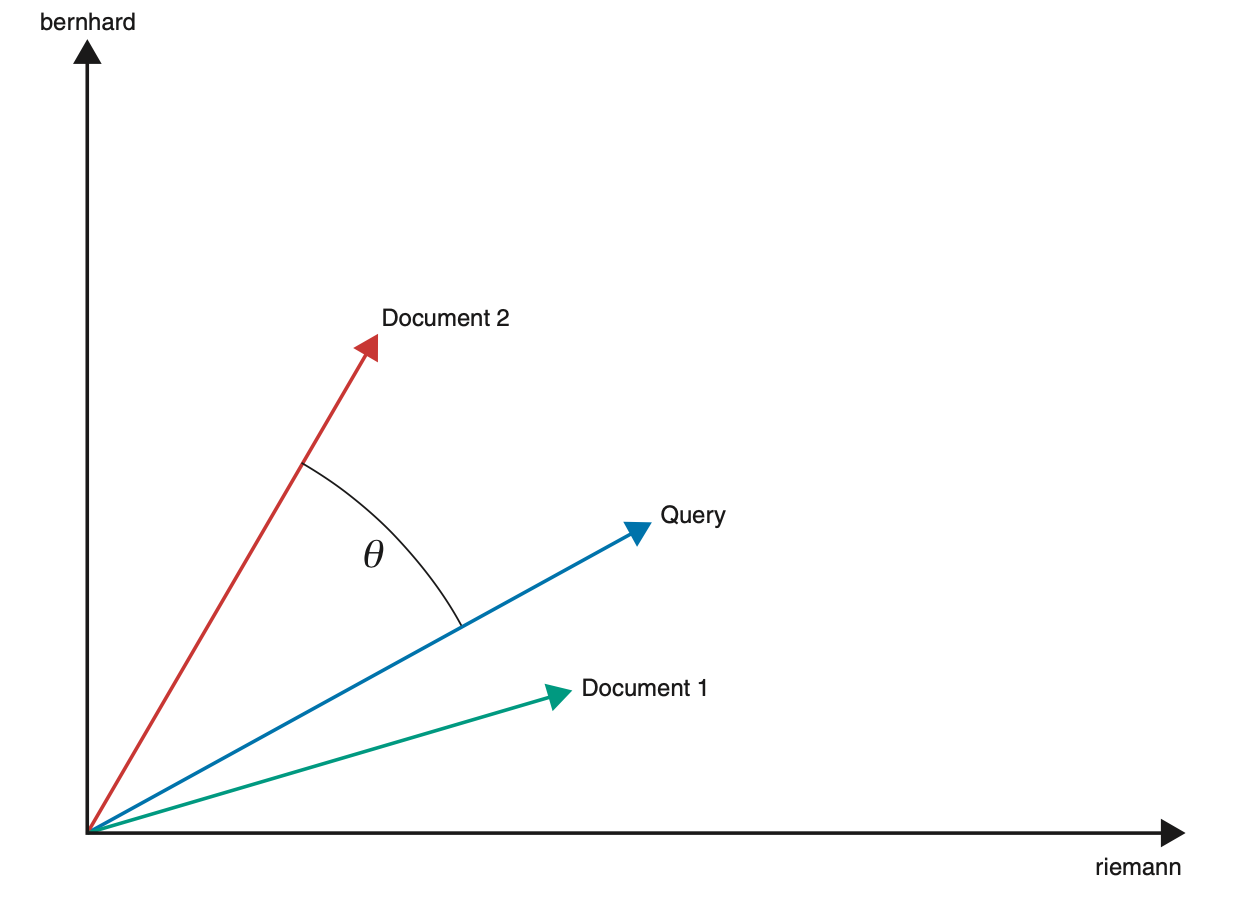
qeury vector와 document의 similarity는 이 두 vector 간의 각도를 보고 평가한다.(각도가 작을수록 유사하다고 본다.)
ex)
cosineSimilarity(q, doc1) = 0.38
cosineSimilarity(q, doc2) = 0.51
BM25
루씬의 확률론적 텍스트 스코어링 모델이고 이것은 TF-IDF의 단점을 보완한다.
- 자주 반복되는 용어를 토대로 과도한 점수를 받지 않도로고 용어빈더의 영향을 제한한다.
- 확실한 용어의 문서빈도 중요도에 대한 더 나은 추정치를 제공한다.
하지만 몇 가지 제약도 있다.
- TF-IDF처럼 BM25도 bag-of-words model이라 순위를 지정할 때 term순서를 무시한다.
- 일반적으로 잘 수행되지만, BM25는 휴리스틱스에 기반한다.
- BM25는 확률 처정에 대한 근사 및 단순화를 수행하기 때문에 수용할 수 없는 결과가 발생하기도 한다.(긴 문서에는 잘 작동하지 않는다.)
Neural information retrival
더 나은 방법을 위해 신경망을 사용하려면 벡터라는 관점에서 생각해야 한다.
데이터에서 좋은 representation을 학습해 내는 일은 딥러닝이 가장 잘 할 수 있는 일 중 하나이다. ranking을 위해 벡터 표현을 사용한다.
- Word2vec
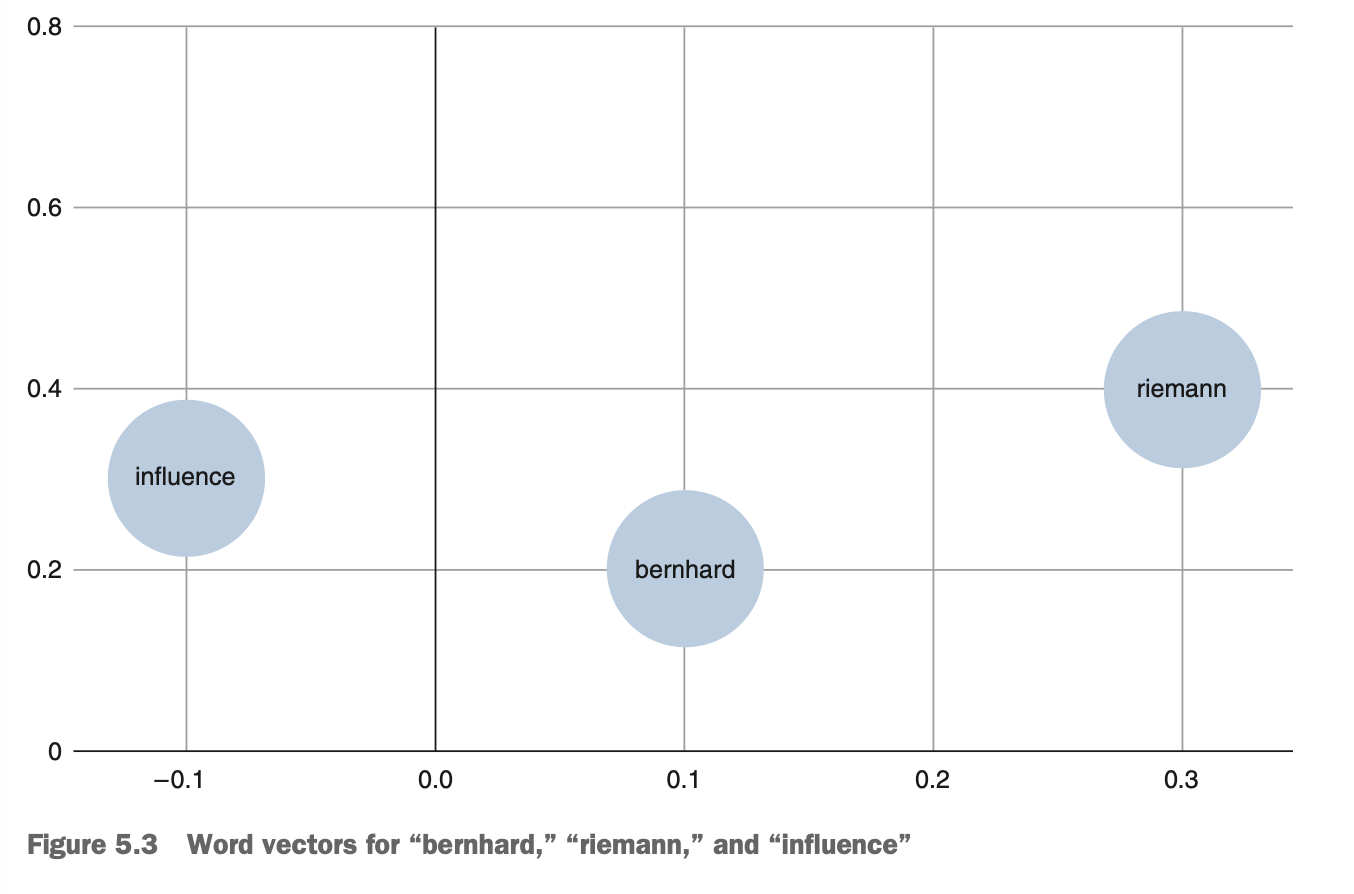
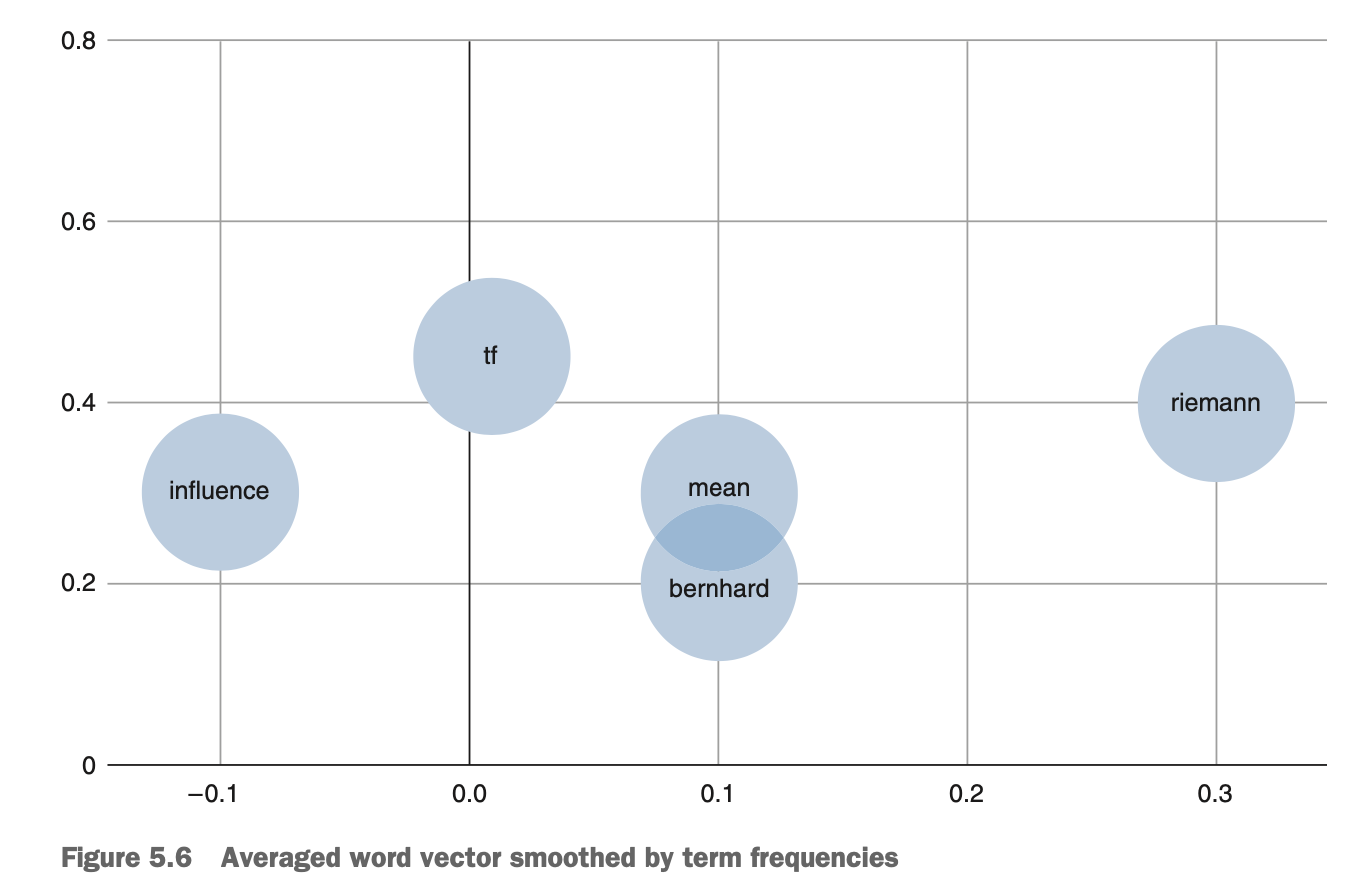
단어에서 문서벡터로 만드는 쉬운 방법은 간단한 연산을 활용해
단어 벡터를 하나의 문서 벡터로 평균하는 것이다.
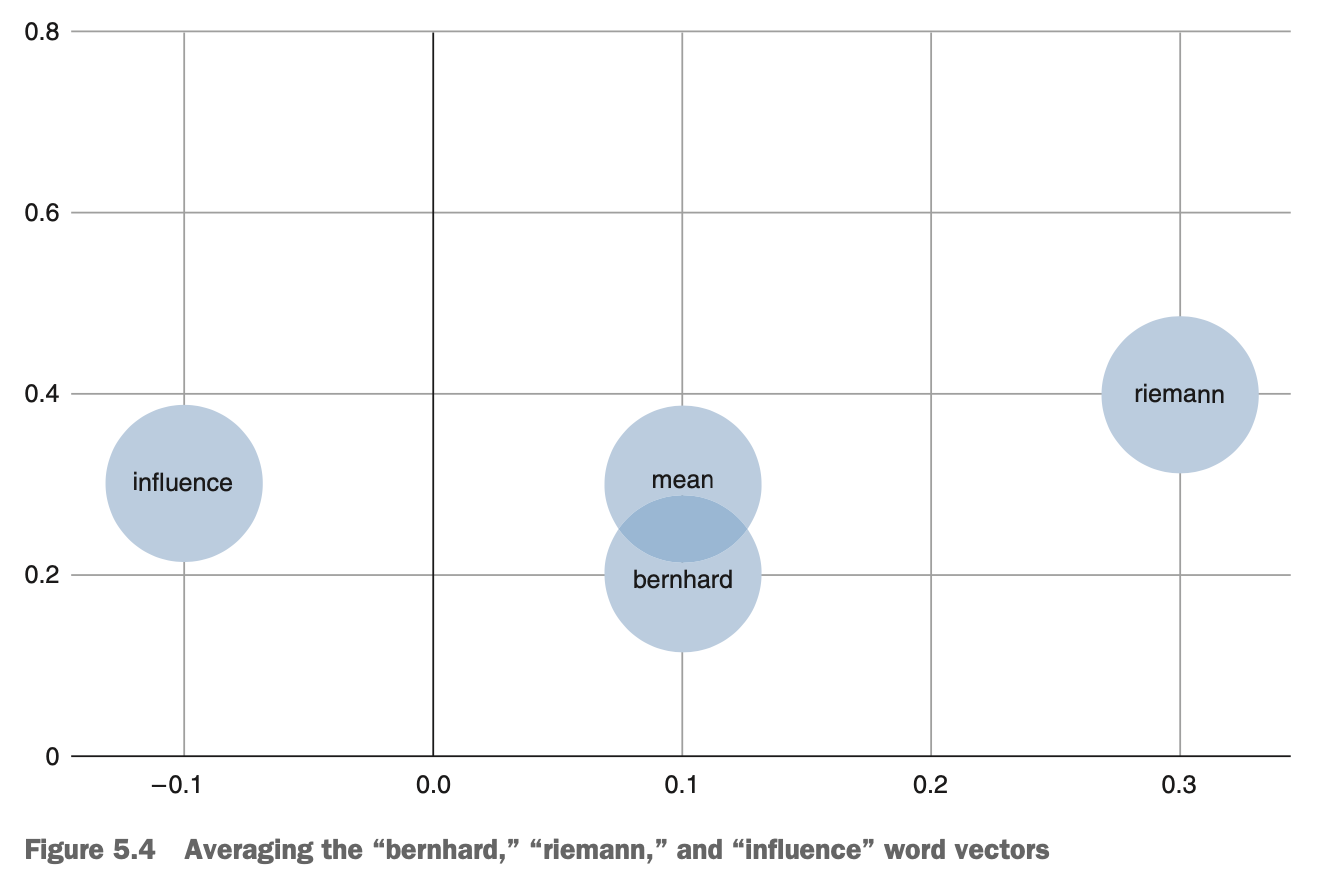
term frequency를 smoothing하면 문서벡터들을 단어들의 중심에 해당하는 자리에 배치하지 않으면서 빈도가 낮은(더 중요한)단어의 더 가까운 자리에 위치하는 데 도움이 된다.
Summary
- VSM과 BM25와 같은 고전적인 검색 모델은 문서를 ranking하기 good baseline이지만 텍스트가 가진 기능의 의미를 이해하기에는 부족하다.
- 신경 정보 검색 모델은 ranking documents를 위한 의미 이해를 더 잘 이해할 수 있게 하는 기능을 제공하는 것이 목적이다.
- 단어들의 분산 표현은 쿼리와 문서의 document embedding을 생성하기 위해 결합할 수 있다.
ref) deeplearning for search
