Segmentation(CV)
Segmentation
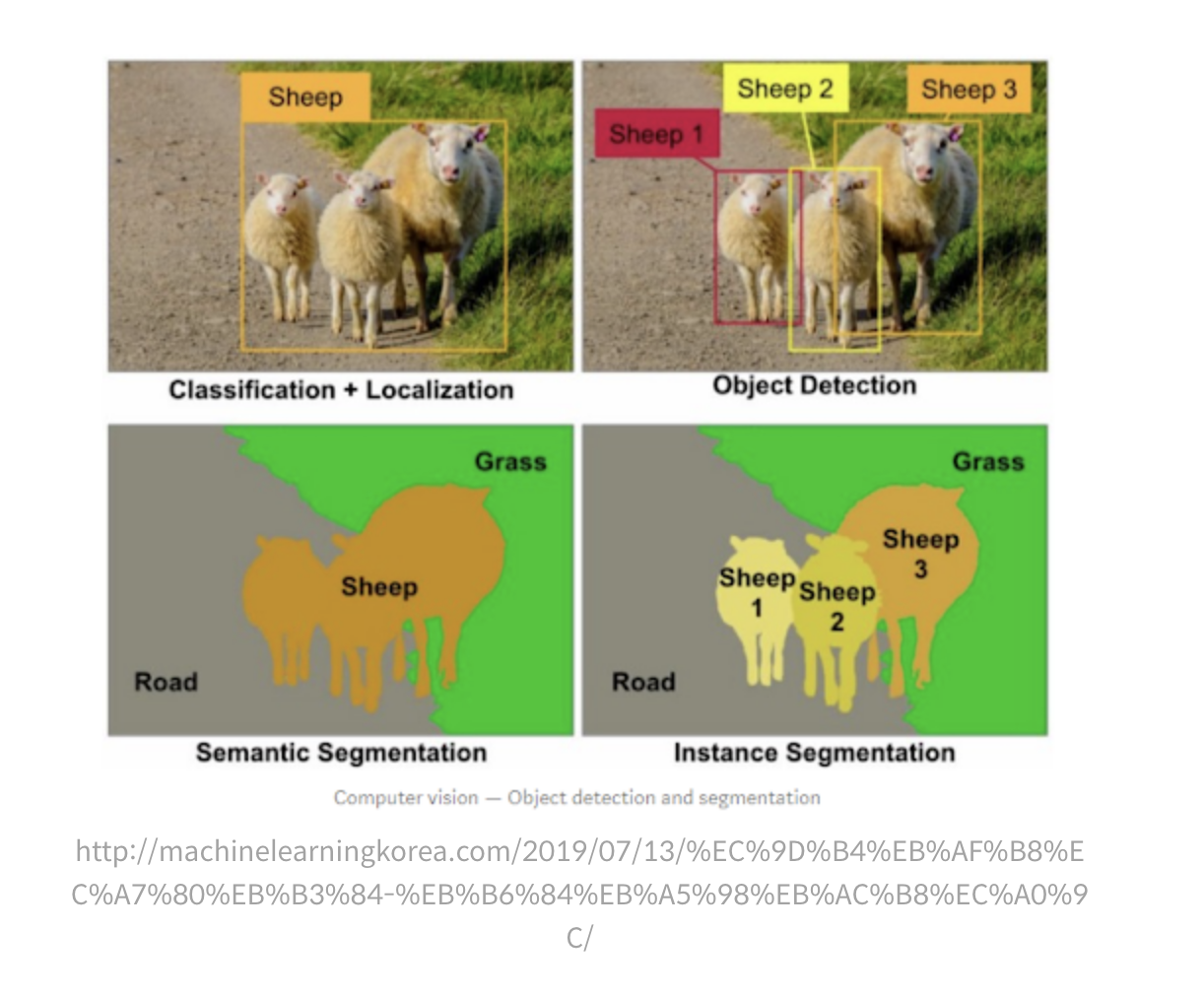
Semantic segmentation은 각각의 양들의 객체 영역을 부분해내지는 않는다.
반면, Instance segmentation은 각 객체 영역을 픽셀 단위로 구분한다
- Semantic segmentation

- U-Net(시맨틱 세그멘테이션의 대표적 모델)
설명: 입력으로 572x572 크기인 이미지가 들어가고 출력으로 388x388의 크기에 두 가지의 클래스를 가진 세그멘테이션 맵이 나온다.
- Instance segmentation
같은 크래스 내에서도 각 개체들을 분리해서 세그멘테이션을 한다.
- Mask R-CNN(인스턴스 세그멘테이션의 대표적 모델)
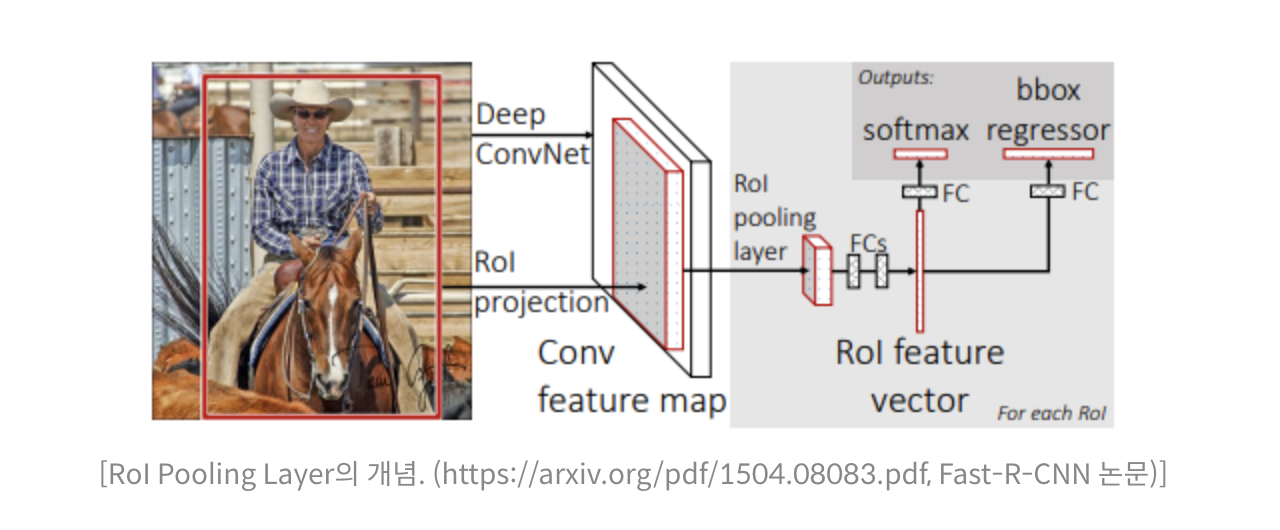
RoIPool layer는 관심 영역인 RoI영역을 통해 동일한 크기의 Feature Map을 추출한다.
이 사이즈의 Feature map을 가지고 bbox와 object의 클래스를 추론한다.
'Mask R-CNN'은 Faster R-CNN에서 특성 추출방식을 'RoIAlign'방식으로 개선을 하고 세그멘테이션을 더한 방식이다.
Segmentation Model
- FCN
Fully Convolutional Network
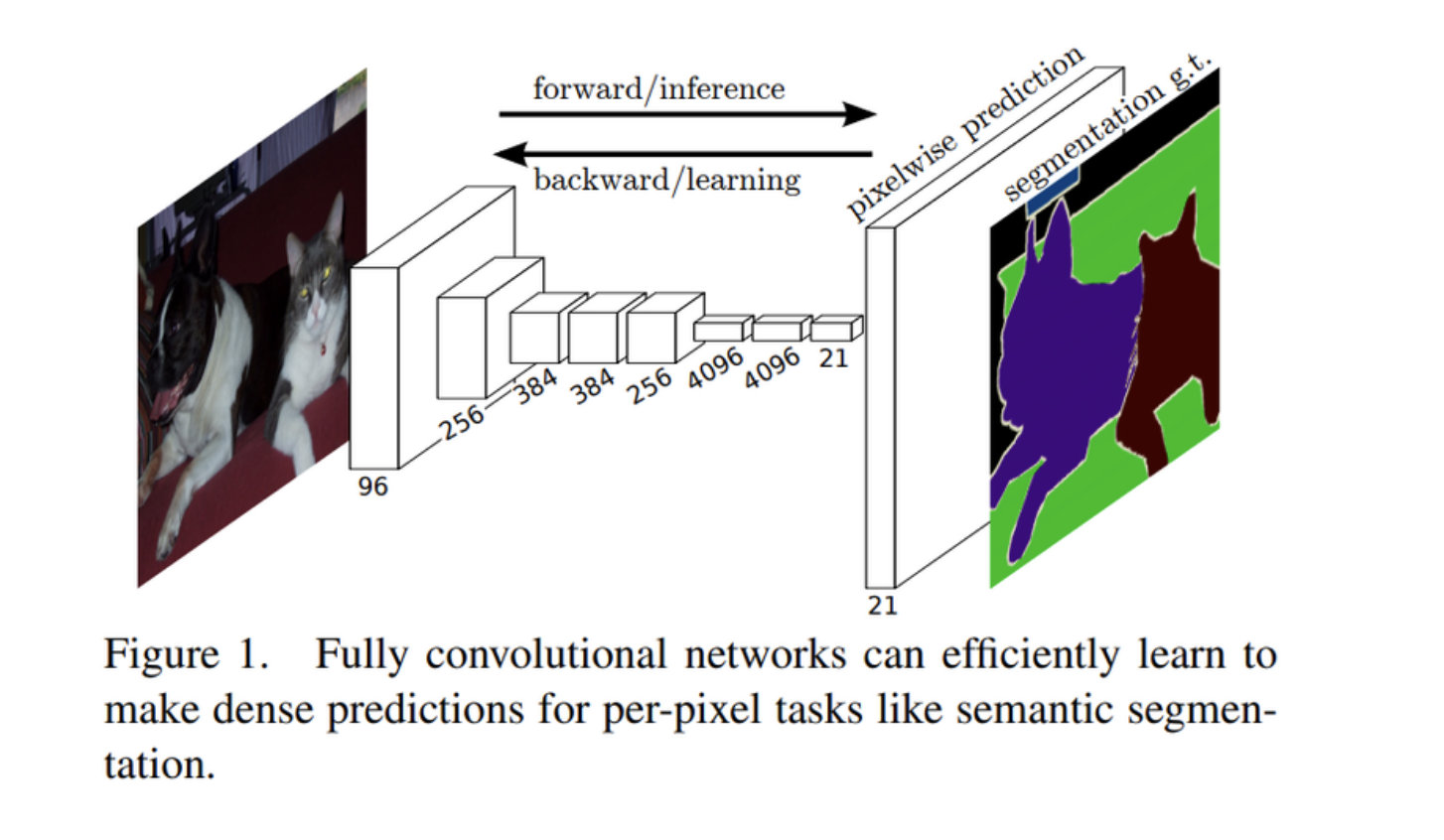
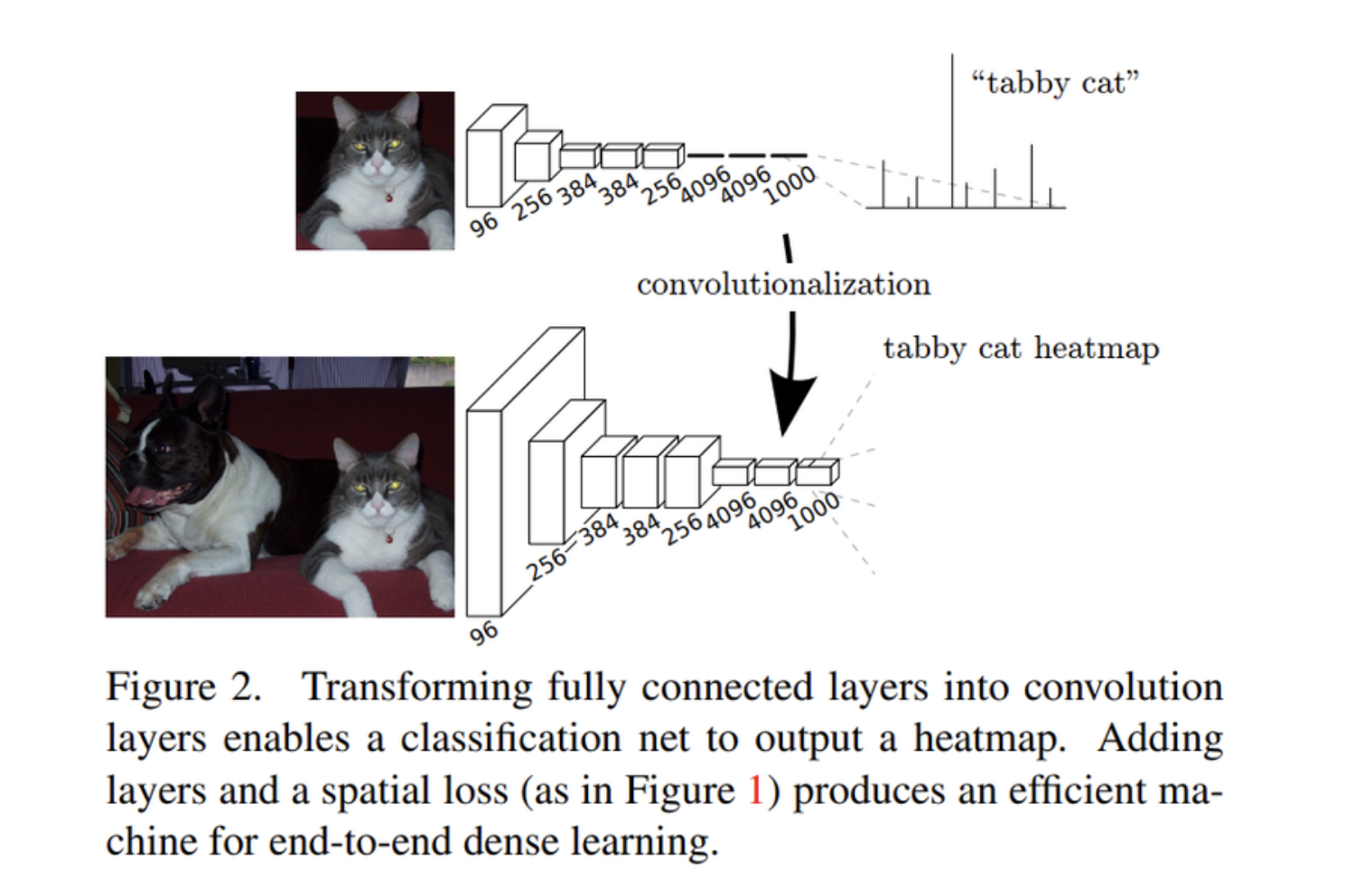
FCN은 AlextNet, VGG-16 등의 모델을 segmentation에 맞게 변형한 모델이다.
세그멘테이션을 하기 위해서 네트워크 뒷단에 CNN을 붙여준다.
- U-Net
- DeepLab
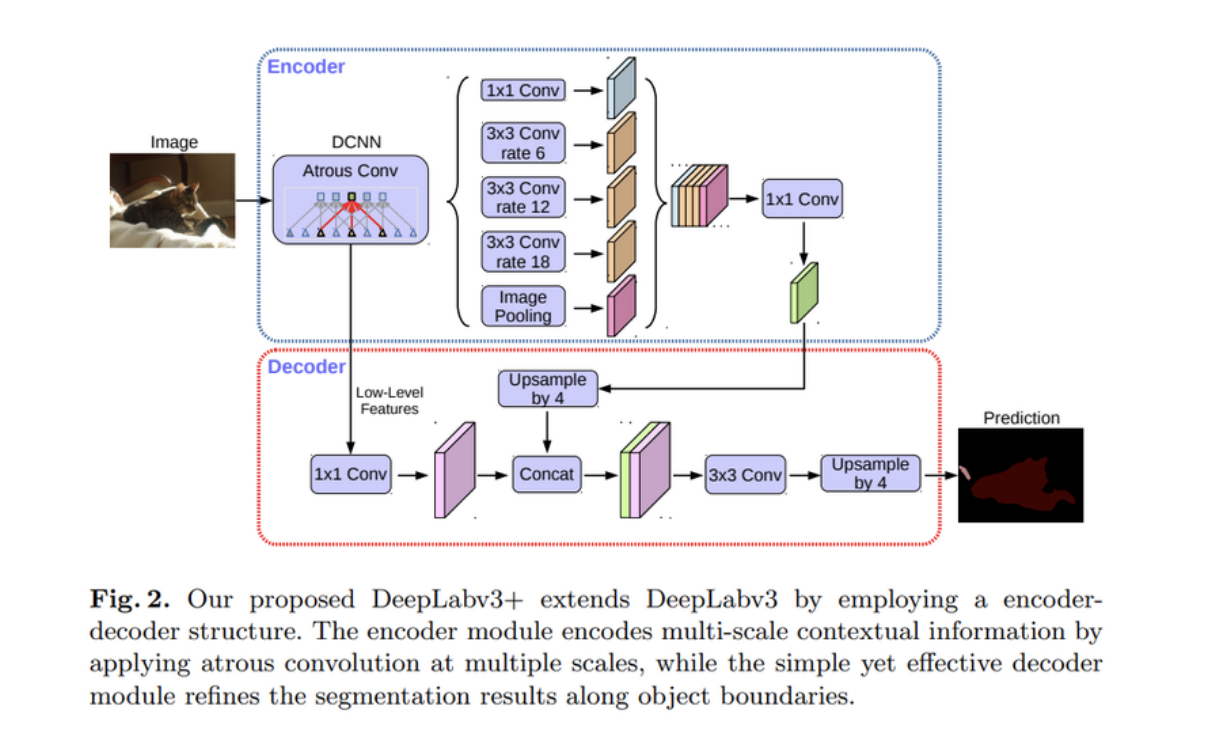
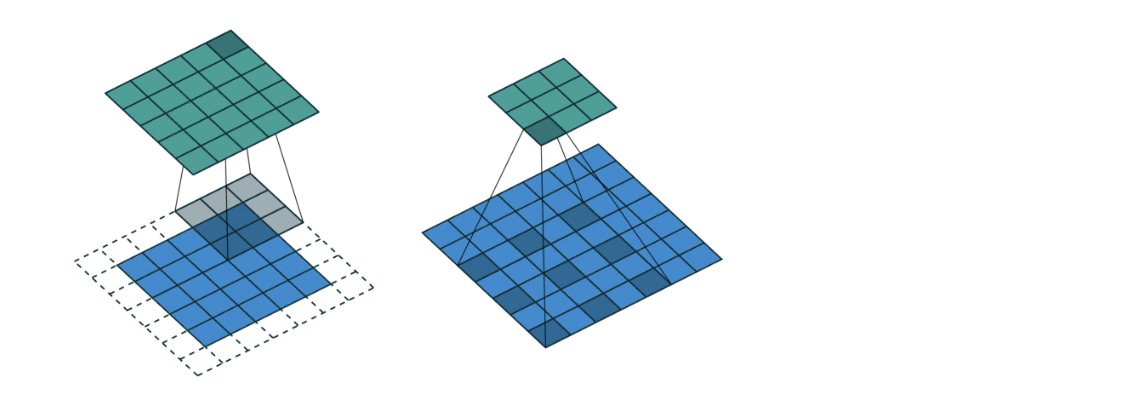
Atrous Convolution을 사용한다.
이는 띄엄보는 컨볼루션이다.
(좌측은 일반적인 컨볼루션, 우측은 Atrous 컨볼루션)
이러면 convolution layer를 너무 깊게 쌓지 않아도 넓은 영역의 정보를 커버함.

Innovation is mine