Intro
데이터 분석에서 log로 변환하는 경우가 있는데 이유는 무엇일까?
목적부터 얘기하자면 log로 변환하는 이유는 정규성을 높이고 분석에서 정확한 값을 얻기 위함이다. 또 다른 말로 log의 역할은 큰 수를 같은 비율의 작은 수로 바꿔 주는 것이다. 복잡한 계산을 심플하게 만든다. 로그를 취하는 순간 그 수는 지수가 되어버리니, 값이 작아 진다.
Skewness(왜도)와 Kurtosis(첨도)
왜도
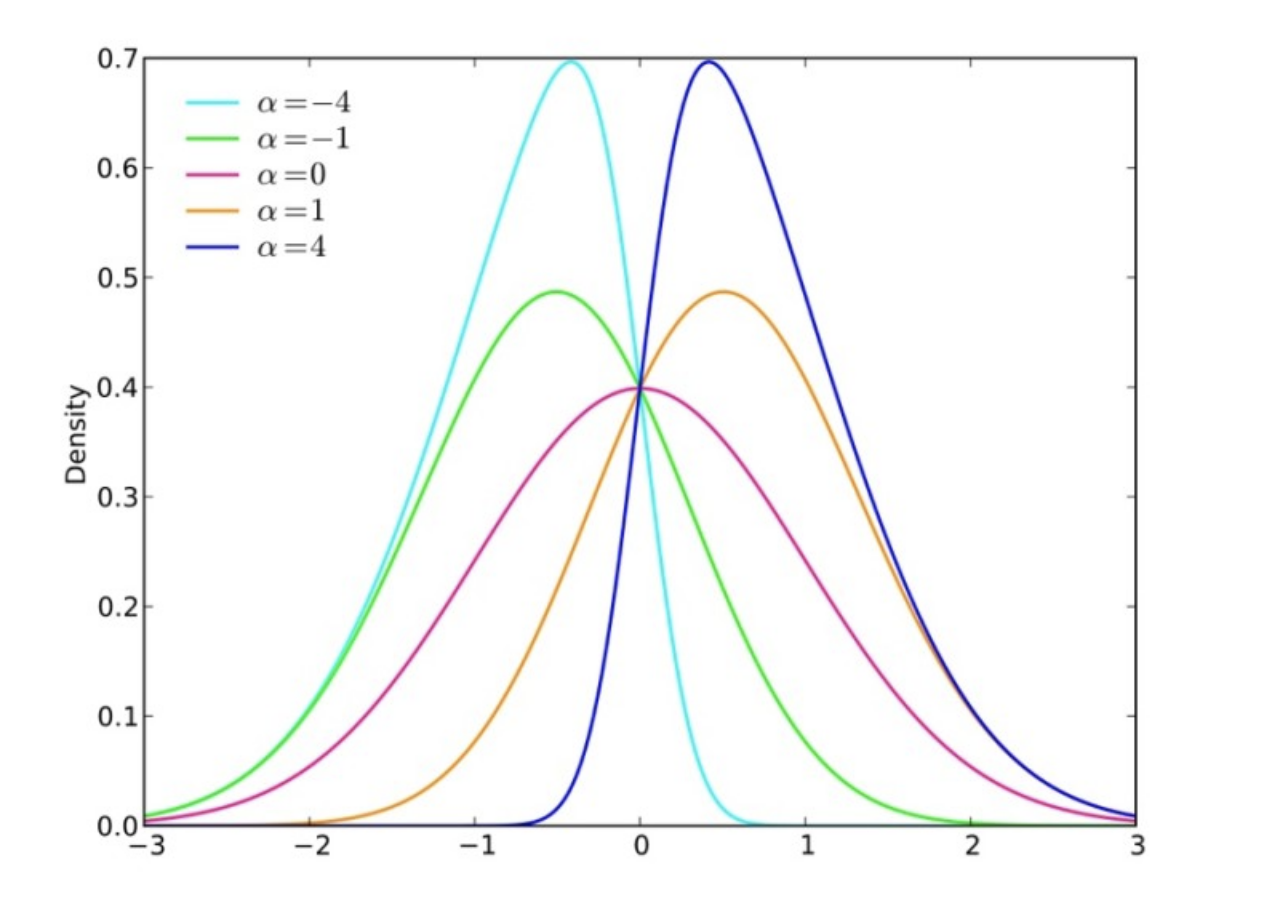
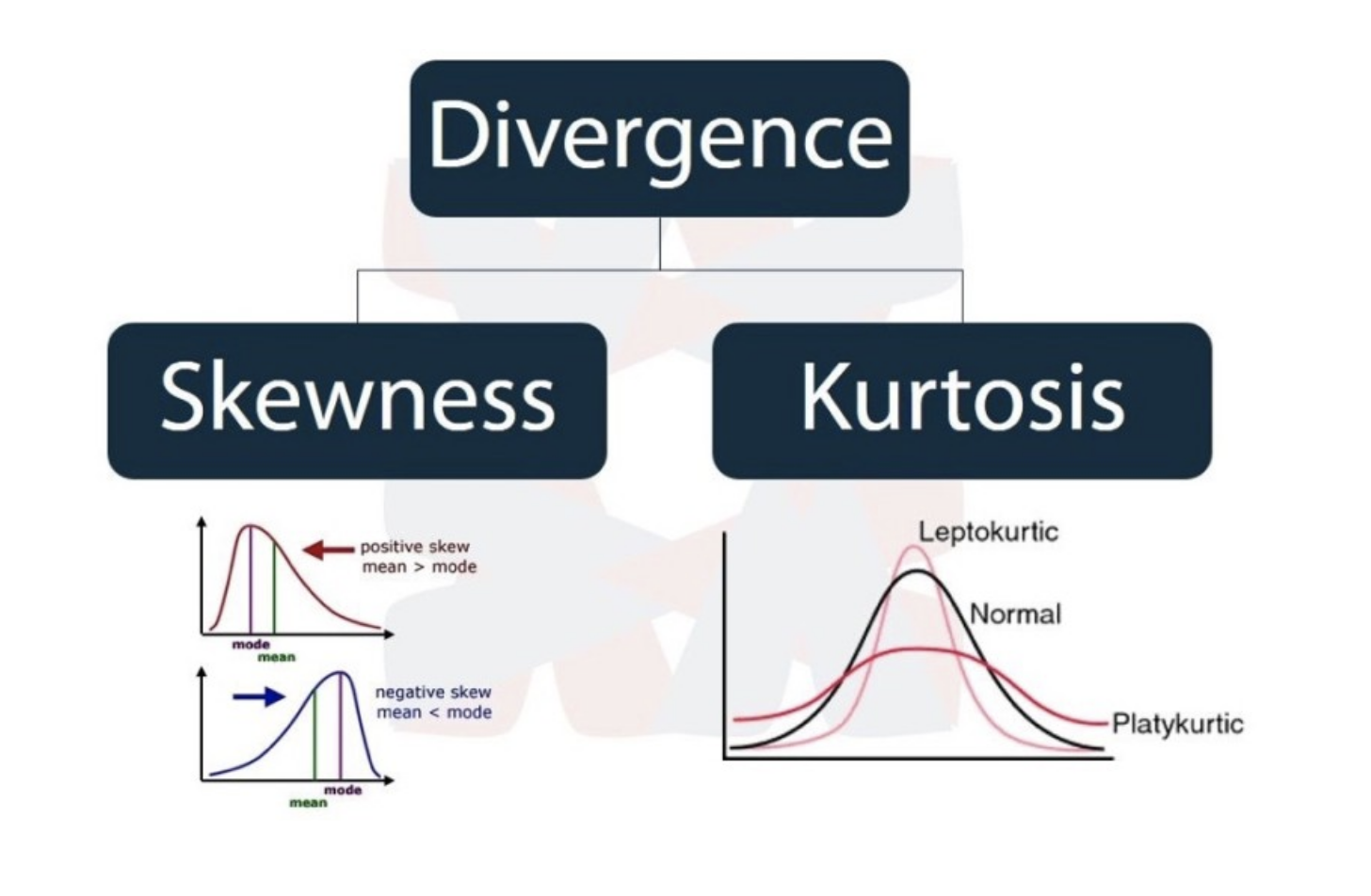
분포의 정규분포에 비해서 얼마나 비대칭성을 나타내는 척도이다.
왜도 값이 양의 값을 가지면(Positive Skewness) - 정규 분포보다 오른쪽에 위치, 음을 값을 가지면(Negative Skewness) - 정규 분포보다 왼쪽에 위치
첨도
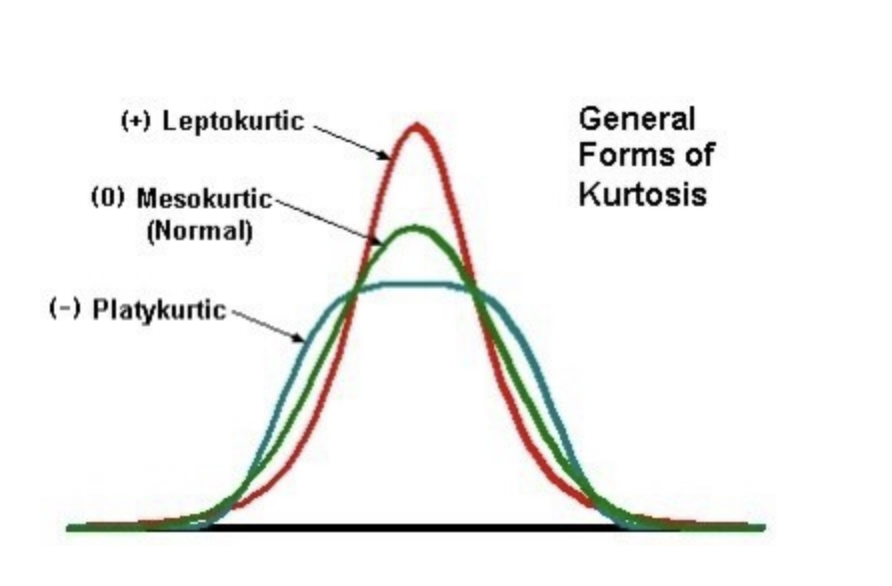
샘플의 점수가 평균을 중심으로 가까이 몰려 있을수록 분포의 정점은 더욱 뾰족하다.
이 뾰족함이 의미하는 것이 첨도이고 분산도가 크면 집단이 이질적이고 분포의 높이가 낮아지면, 분산도가 작으면 집단이 동질적이고 분포의 높이가 높아진다.
Example
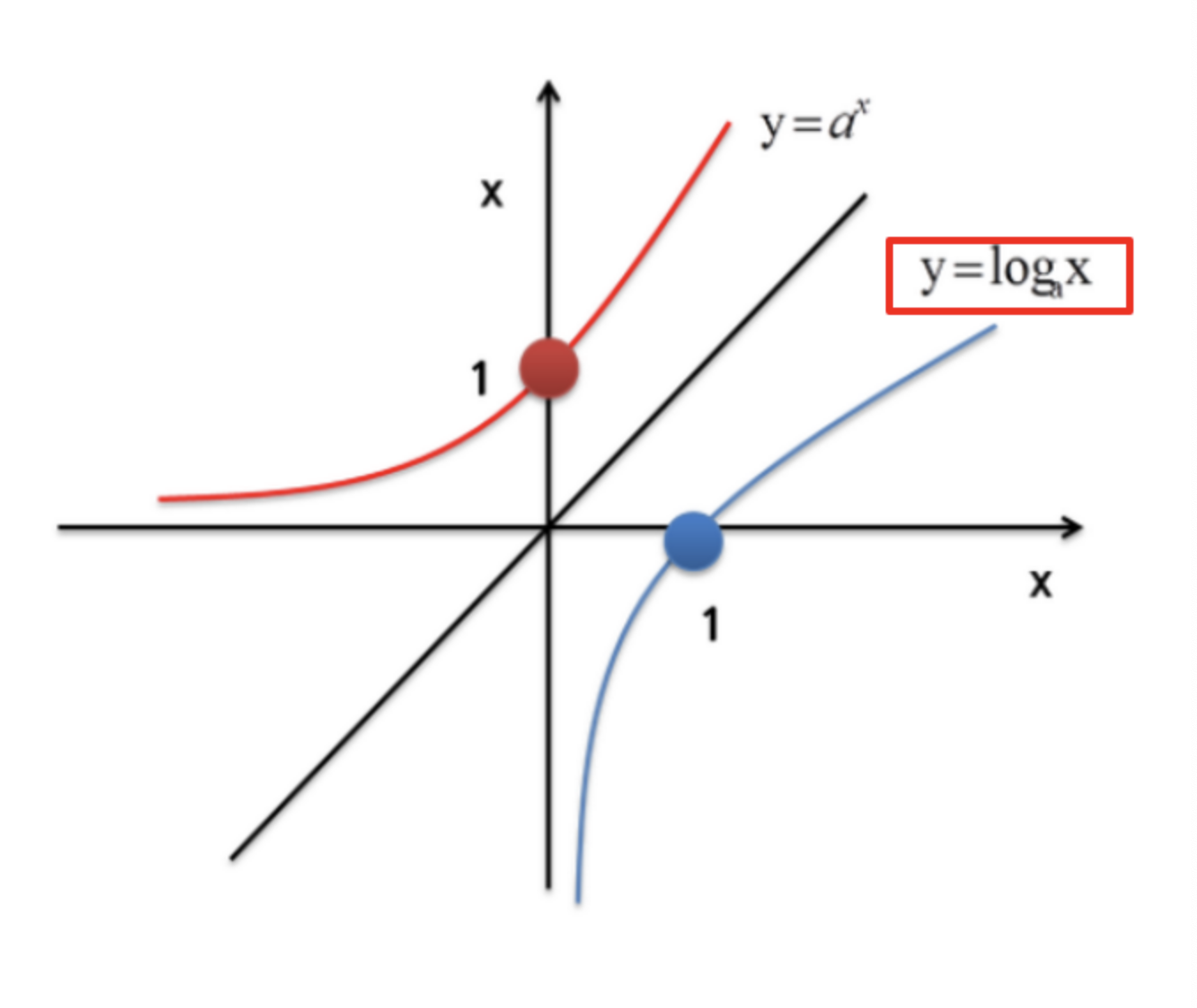
100은 10이다. 100에 상용로그를 취한다면 100에서 밑10으로 하는 지수가 있는 값으로 나타낸다. 그래서 100의 상용로그는 2가 된다. ( 또한 로그를 취하면 로그의 성질에 의해 곱하기가 더하기로, 나누기가 빼기로 바뀐다.
정리
식에 로그를 취하는 이유는
1. 큰 수를 작게 만들고
2. 그로 인해 복잡한 계산을 쉽게 만들고
3. 왜도와 첨도를 줄여서 데이터 분석 시 의미있는 결과를 도출한다.
(로그를 취해 큰 값이 작아지는 것을 보여주는 그래프)

Innovation is mine