Intro
How to do timeseries forecasting using a LSTM model.
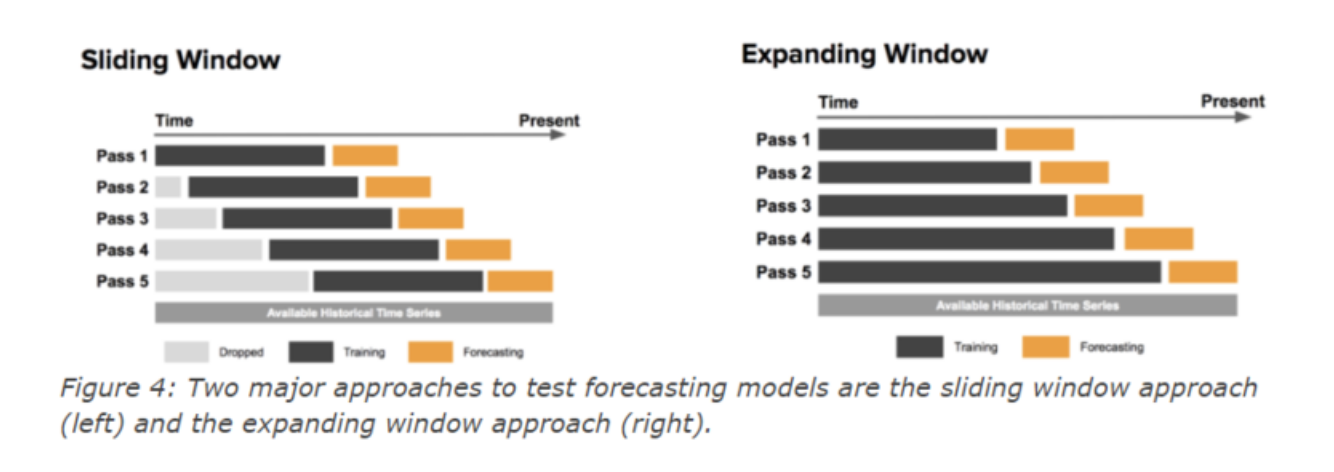
시계열 데이터를 활용해서 수치를 예측하는 모델을 만들 때 사용하는 다양한 방법 중에 Sliding Window를 활용해 과거 데이터를 feature로 사용하는 방법이 있다. 이 방법은 시계열 데이터를 활용한 예측에서 과거 데이터들을 바탕으로 예측을 수행하므로 과거 데이터들을 포함하는 feature를 만들어줘야 한다.
- Sliding window
정해진 사이즈의 데이터로만 훈련시킴(트렌드가 변하는 데이터를 가지고 예측하기 좋음) - Expanding window
테스트 윈도우 사이즈는 고정하고 훈련 윈도우만 점점 늘려감.
Setup
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import kerasClimate Data Time-Series
-
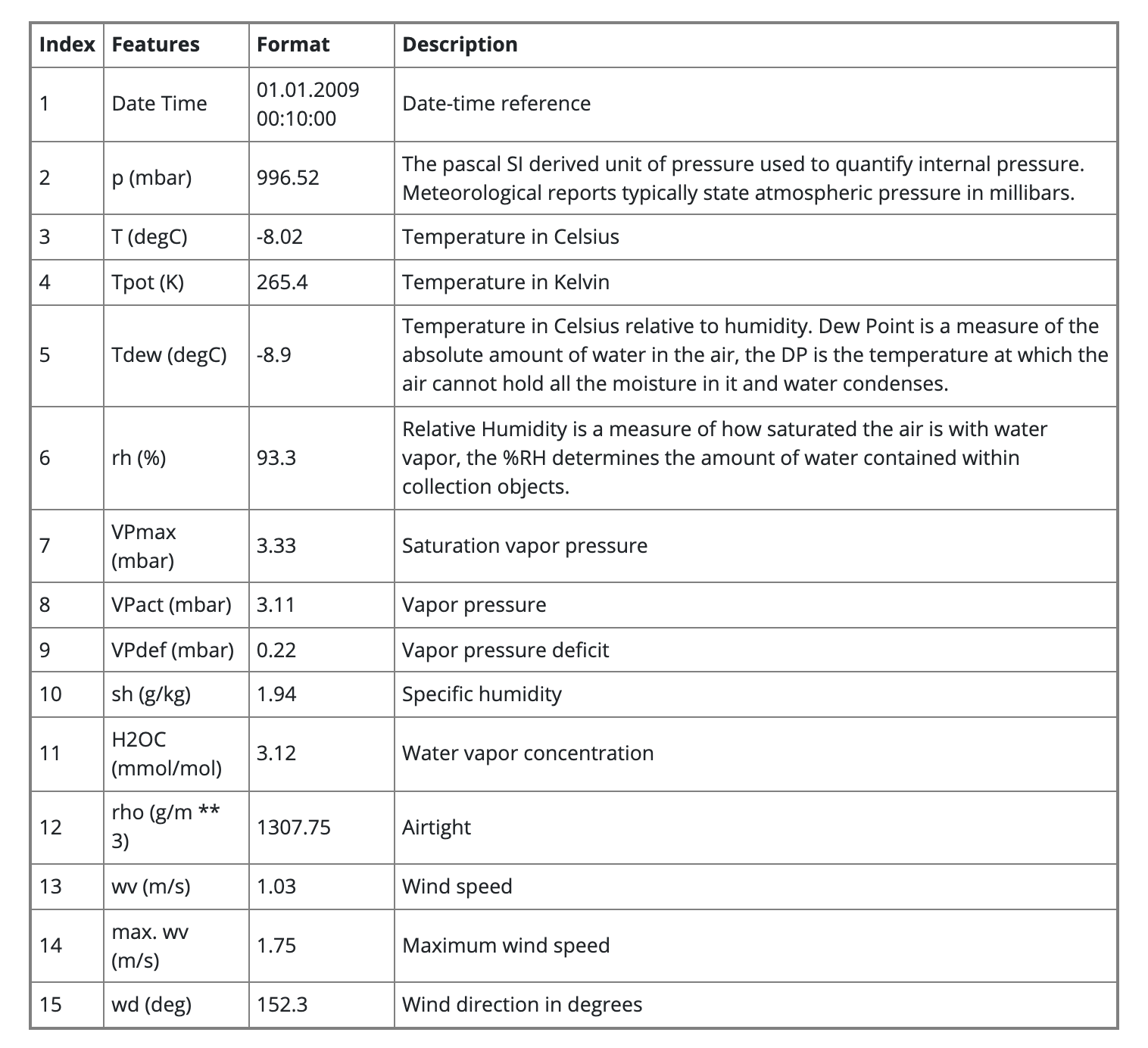
Data set : Jena Climate(Max Planck Institute for Biogeochemistry)
(includes 14 features such as temperture, pressure, humidty etc)
10분 마다 기록되었다. -
Location : Weather Station, Max Planck Institute for Biogeochemistry in Jena, Germany
-
Time-frame Considered: Jan 10, 2009 - December 31, 2016
from zipfile import ZipFile import os uri ="https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip" zip_path = keras.utils.get_file(origin=uri, fname="jena_climate_2009_2016.csv.zip") zip_file = ZipFile(zip_path) zip_file.extractall() csv_path = "jena_climate_2009_2016.csv" df = pd.read_csv(csv_path)
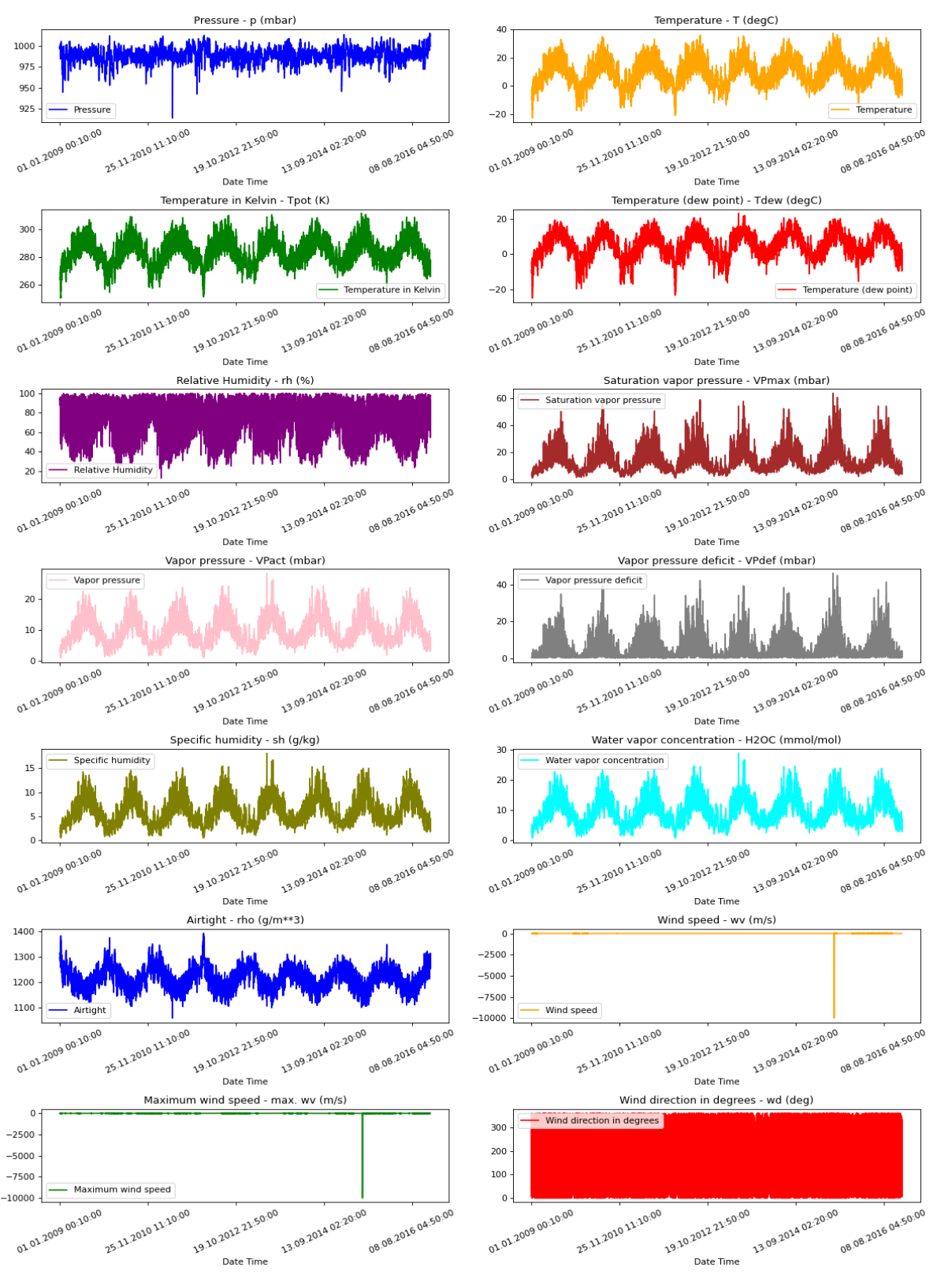
Raw Data Visualization

Method for data visualization
def show_raw_visualization(data):
time_data = data[date_time_key]
fig, axes = plt.subplots(
nrow=7, ncols=2, figsize=(15, 20), dpi=80, facecolor="W", edgecolor="K"
)
for i in range(len(feature_keys)):
key = feature_key[i]
c = colors[i % (len(colors))]
t_data = data[key]
t_data.index = time_data
t_data.head()
ax = t_data.plot(
ax=axes[i // 2, i % 2],
color=c,
title="{} - {}".format(title[i], key),
rot=25,
)
ax.legend([titles[i])
plt.tight_layout()
show_raw_visualization(df)
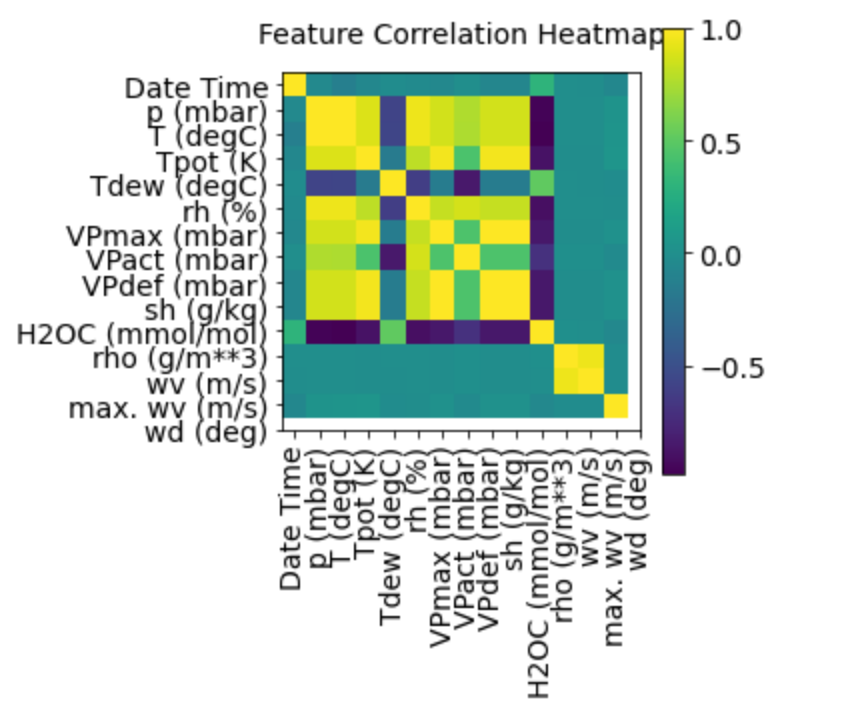
feature간 연관성을 히트맵으로 보기
def show_heatmap(data):
plt.matshow(data.corr())
plt.xticks(range(data.shape[1]), data.columns, fontsize=14, rotation=90)
plt.gca().xaxis.tick_bottom()
plt.yticks(range(data.shape[1]), data.columns, fontsize=14)
cb = plt.colorbar()
cb.ax.tick_params(labelsize=14)
plt.title("Feature Correlation Heatmap", fontsize=14)plt.show()
show_heatmap(df)
Data Preprocessing
훈련을 위한 300,000개의 데이터 포인트가 있다. Observation은 한 시간 당 6번 즉, 10분 단위로 기록할 것이다.
이것을 가지고 60분 사이에 예상되는 변화가 없으면 시간당 1포인트를 다시 샘플링한다.
이는 timeseries_dataset_from_array안의 sampling_rate argument를 통해 실행한다.
우리는 과거 720 timestamps(720/6=120hours)으로부터 데이터를 트래킹한다.
이 데이터는 72stamp(12hours)이후의 온도를 예측하는데 쓰여질 것이다.
신경망을 훈련하기 전에 피쳐 값을 점위로 제한하기 위해 정규화를 해준다.(평균을 빼고 각 피쳐에 표준편차로 나눔)
데이터의 71.5%로 모델을 훈련할 것이다.
모델에는 5일 간 매 시간 샘플된 데이터를 보여준다 (720개의 관측소)

heat map에서 볼 수 있듯이 상대 습도와 특정 습도의 변수는 겹치지 않는다. 전체가 아닌 일부 피쳐만 사용할 것이다.

Training dataset
훈련 데이터셋 라벨은 792번째 observation 부터 시작(과거720+미래72)

아래의 timeseries_dataset_from_array function은 시계열 데이터 전처리 함수로써 시퀀스/윈도우의 길이, 두 시퀀스/윈도우 사이의 간격 등과 같은 시계열 매개변수와 함께 동일한 간격으로 수집된 데이터 포인트 시퀀스를 취하여 시계열 입력 및 대상의 배치를 생성한다.

- Arguments
- data: 연속적인 데이터 포인트(시간 단위)를 포함하는 Numpy array 나 Eager tensor. axis 0은 시간 차원으로 예상된다.
- targets: data와 길이가 같아야 한다. data.targets[i]에 시작하는 윈도우는 해당하는 대상이어야 한다.(그 데이터가 없을 경우 None을 전달함. 이 경우 데이터셋은 입력 데이터만 산출함.)
- sequence_length: 출력 시퀀스의 길이(시간 단위 수)
- sequence_stride: 연속되는 출력 시퀀스 사이간 stride
- sampling_rate: 시퀀스 내에서 연속적인 개별 타입스텝 사이의 기간
- batch_size: 배치할 시계열 샘플 수
- shuffle: 출력 샘플을 섞을지 아니면 순차적으로 할지에 대한.
- seed: optional int, shuffle를 하기 위한 random seed이다.
- start_index: optional int, 출력 시퀀스에서 사용되지 않을 것보다 더 이른 데이터 포인트 . 이는 테스트 또는 검증을 위해 데이터의 일부를 예약하는 데 유용합니다.
- end_index: optional int, end_index는 출력 시퀀스에 사용되지 않는다. 이는 테스트 또는 검증을 위해 데이터의 일부를 예약하는 데 유용함.
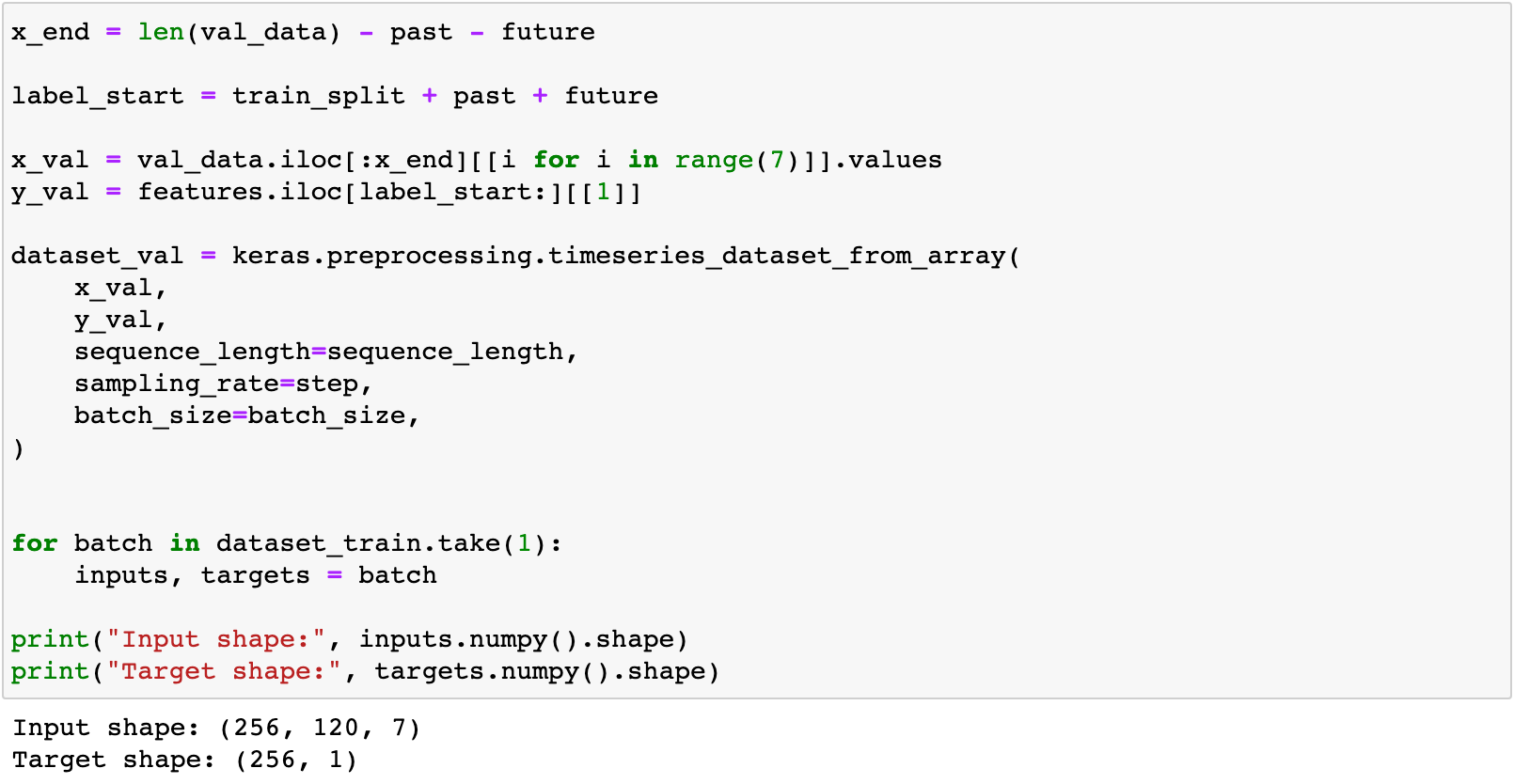
Validation dataset
유효성 검사 데이터 세트에는 해당 레코드에 대한 레이블 데이터가 없으므로 마지막 792개 행이 포함되어서는 안 된다. 따라서 데이터 끝에서 792개를 빼야 한다.
그리고 이 데이터 셋은 train_split 이후 792부터 시작해야 하므로 label_start에 past + future(792)를 추가해야 한다.
Training
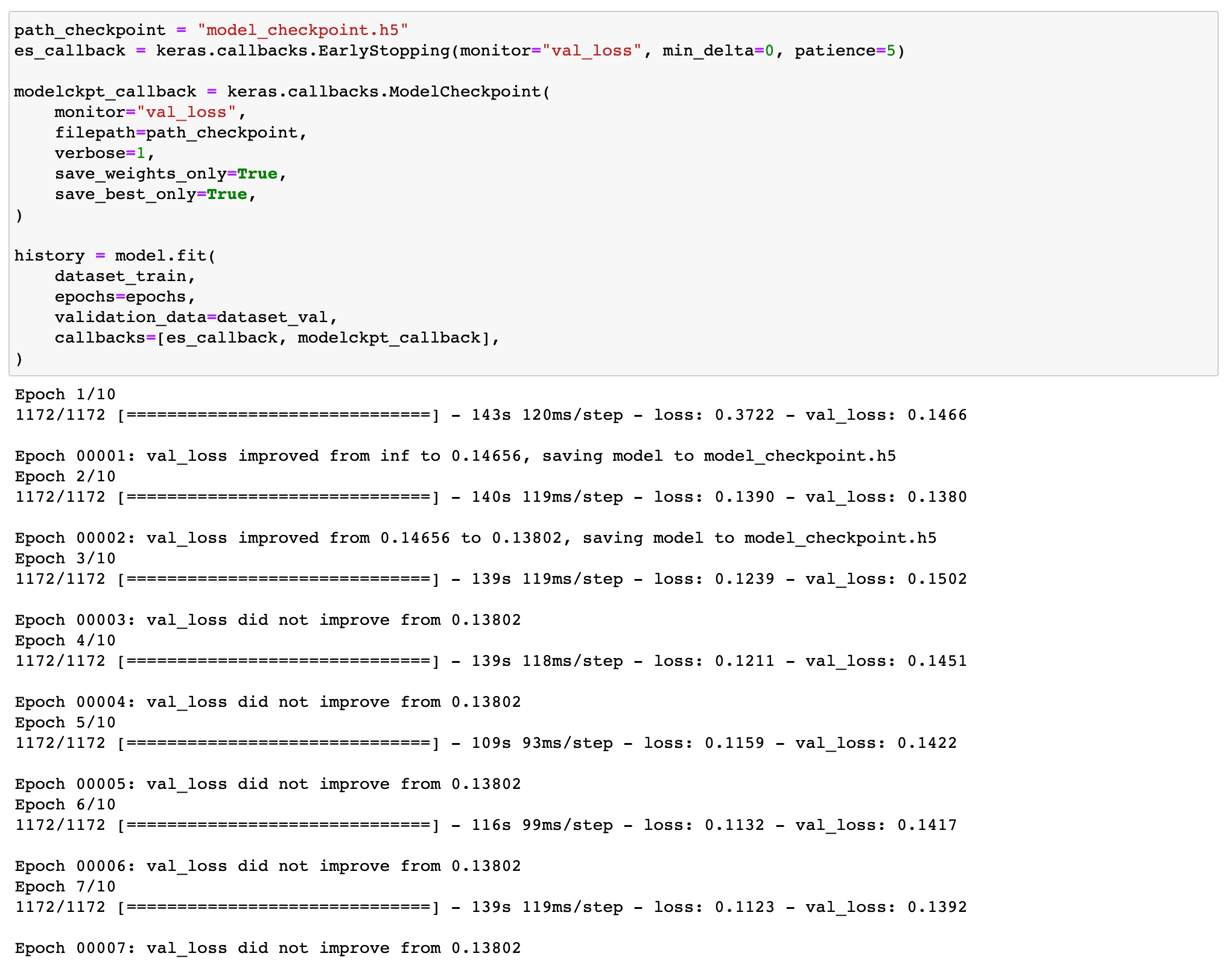
저장을 위한 check point callback과 EarlyStopping callback을 사용할 것이다. 모델을 저장할 때 사용하기 위함과 validation loss가 더 이상 증가하지 않을 때를 위함. 코드는 아래.
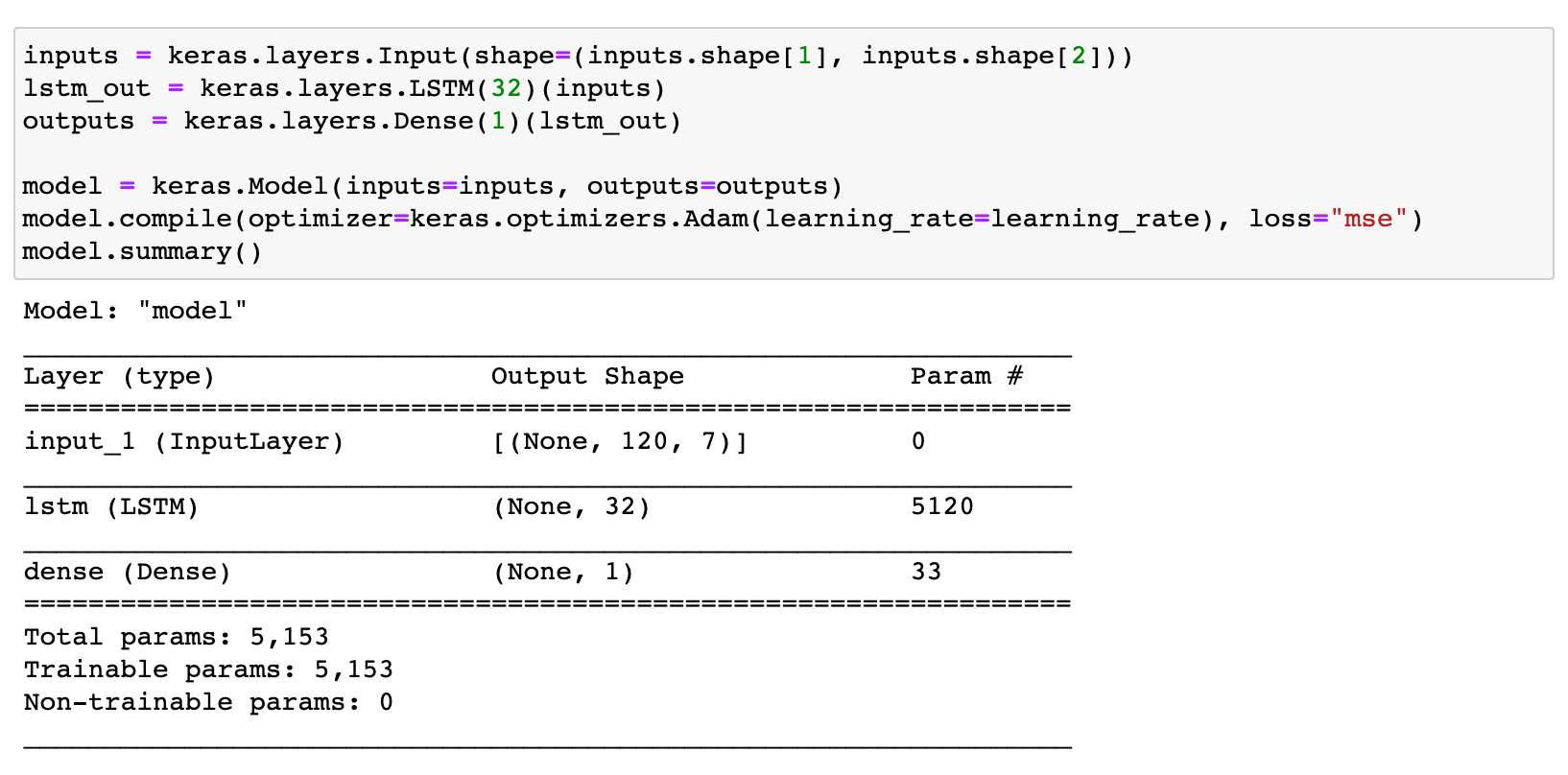
콜백도 써주고
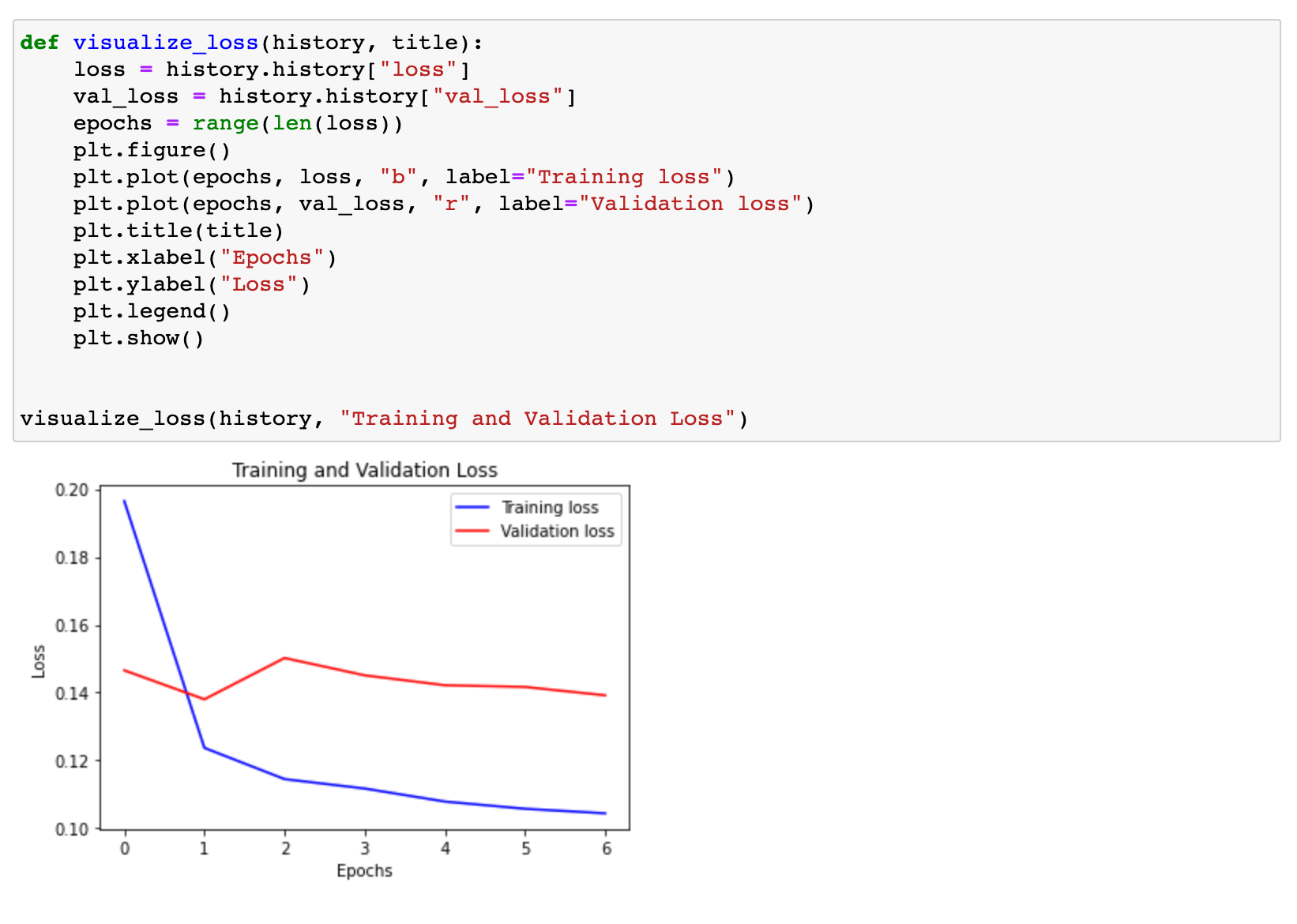
Visualization
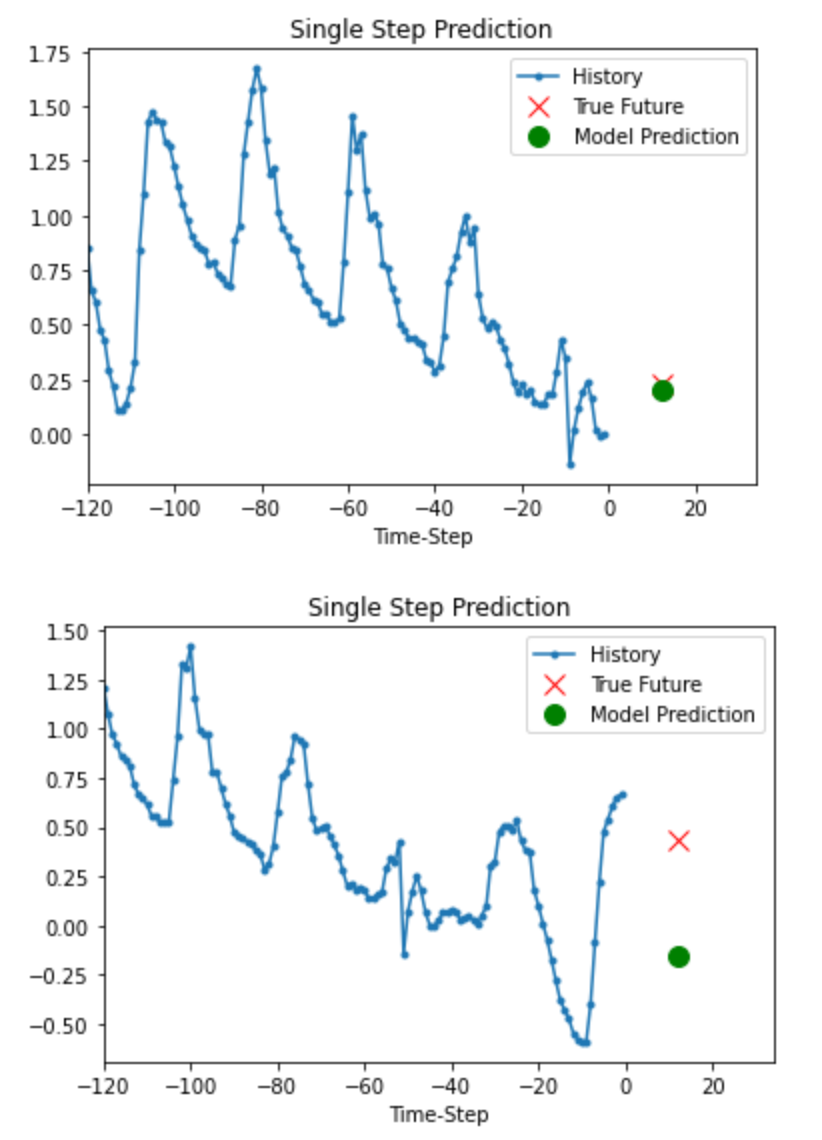
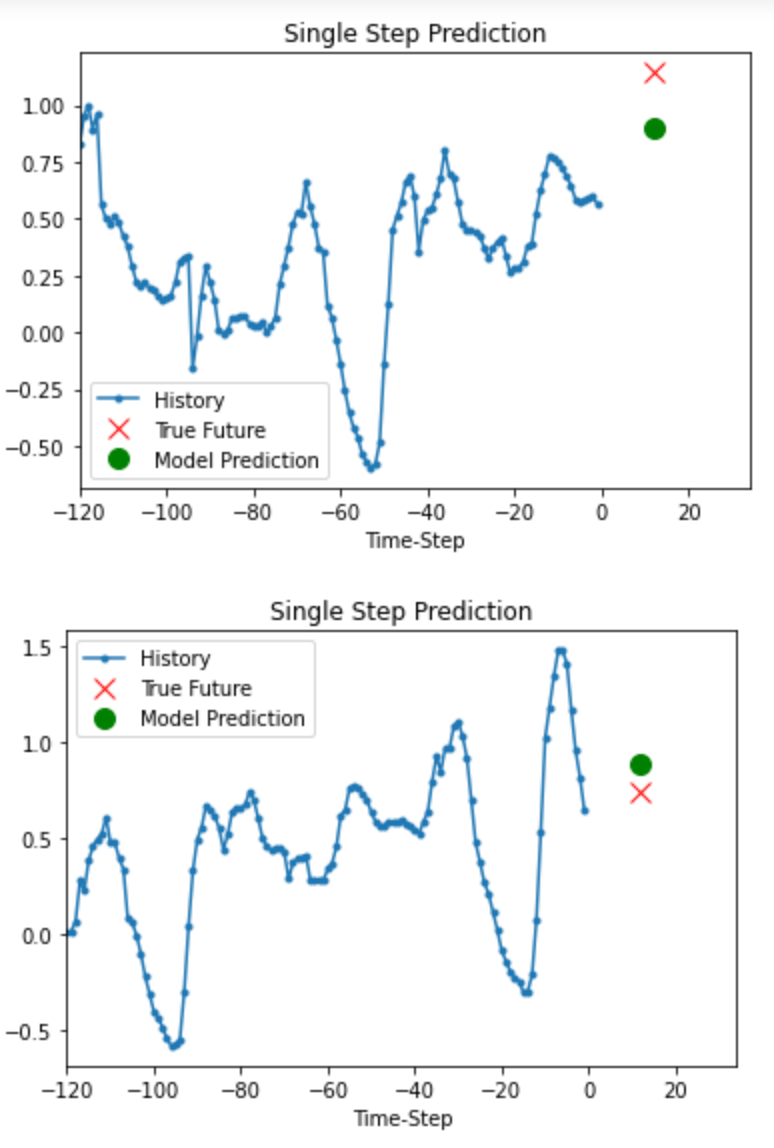
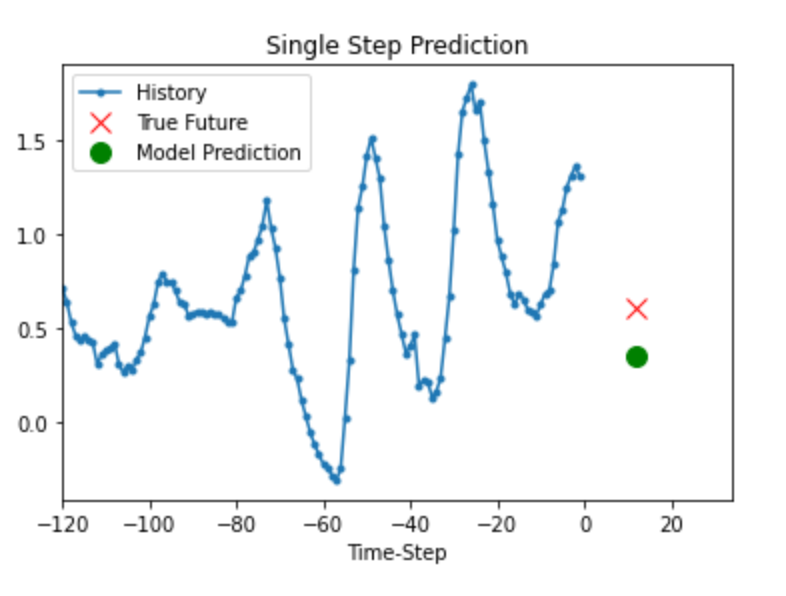
Prediction
이 훈련된 모델은 검증 세트에서 5개의 값 세트에 대한 예측을 할 수 있다.